

А. П. Частиков Т. А. Гаврилова Д. Л.Белов
РАЗРАБОТКА ЭКСПЕРТНЫХ СИСТЕМ.
СРЕДА CLIPS
Санкт-Петербург
«БХВ-Петербург»
2003
УДК 681.3.06
ББК 32.813
Ч-25
Книга является одним из первых российских изданий по практической разработке экспертных систем. Подробно рассмотрены вопросы домашинного этапа разработки – извлечения и структурирования знаний, атакже технологические аспекты разработки систем, основанных на знаниях. В качестве среды разработки экспертных систем описана среда CLIPS. Книга содержит достаточное количество справочной информации по CLIPS, что позволяет рекомендовать ее даже опытным программистам, которые в своей практической деятельности занимаются разработкой экспертных систем.
Для студентов вузов, инженеров по знаниям, программистов, проектировщиков эксепртных систем.
Содержание
Введение……………………………………………………………………………….. 8
ЧАСТЬ I. ЭКСПЕРТНЫЕ СИСТЕМЫ…………………………………………… 10
Глава 1. Системы, основанные на знаниях 11
- Знания и данные 11
- Модели представления знаний 13
- Продукционная модель 14
- Семантические сети 14
- Фреймы 15
- Формальные логические модели 17
1.3. Вывод на знаниях 17
- Управление выводом 19
- Методы поиска в глубину и в ширину 20
1.4. Работа с нечеткостью 21
- Основы теории нечетких множеств 21
- Операции с нечеткими знаниями 23
- Архитектура и особенности экспертных систем 24
- Классификация экспертных систем 28
- Классификация по решаемой задаче 28
- Классификация по связи с реальным временем 30
- Классификация по типу ЭВМ 30
- Классификация по степени интеграции с другими программами 30
1.7. Разработка экспертных систем 30
- Выбор подходящей проблемы 31
- Разработка прототипа 32
Идентификация проблемы 33
Извлечение знаний 33
Структурирование или концептуализация знаний 34
Формализация знаний 34
Программная реализация 34
Тестирование 35
- Развитие прототипа до промышленной ЭС 35
- Оценка системы 36
- Стыковка системы 36
- Поддержка системы 37
1.8. Человеческий фактор при разработке ЭС 37
- Пользователь 38
- Эксперт 38
- Программист 39
- Инженер по знаниям 39
Глава 2. Введение в инженерию знаний 41
2.1. Определение и структура инженерии знаний 41
- Поле знаний 41
- "Пирамида" знаний 44
- Стратегии получения знаний 44
- Теоретико-методические аспекты извлечения и структурирования знаний 47
2.3.1. Психологический аспект 47
Контактный слой 49
Процедурный слой 49
Когнитивный слой 51
2.3.2. Лингвистический аспект 52
"Общий код" 53
Понятийная структура 55
Словарь пользователя 56
2.3.3. Гносеологический аспект 56
Внутренняя согласованность 57
Системность 57
Объективность 57
Историзм 57
Методология процесса получения нового знания 58
- Методы практического извлечения знаний 60
- Практикум по инженерии знаний 62
2.5.1. Текстологические методы 62
Понимание текста 63
Смысловая структура текста 64
Алгоритм извлечения знаний из текста 65
2.5.2. Коммуникативные методы 65
Пассивные методы 65
Активные индивидуальные методы 68
Активные групповые методы 71
Экспертные игры 73
2.6. Методы структурирования и формализации 76
- Теоретические предпосылки 76
- Объектно-структурный подход (ОСП) 78
Стратификация знаний 79
Алгоритм ОСА (объектно-структурного анализа) 80
2.6.3. Практические методы структурирования 81
Алгоритм для "чайников" 81
Методы выявления объектов, понятий и их атрибутов 82
Методы выявления связей между понятиями 84
Методы выделения метапонятий и детализация понятий
(пирамида знаний) 84
Методы определения отношений 85
Визуальное структурирование 85
ЧАСТЬ II. ОБЩИЕ ПОНЯТИЯ 88
Глава 3. Что такое CLIPS? 89
- История создания CLIPS 89
- Работа с CLIPS 91
- Синтаксис определений 93
Глава 4. Обзор возможностей CLIPS 95
4.1. Основные элементы языка 95
- Типы данных 95
- Функции 97
- Конструкторы 98
4.2. Абстракции данных 98
4.2.1. Факты 98
Упорядоченные факты 99
Неупорядоченные факты 99
Инициализация фактов 100
4.2.2. Объекты 100
Инициализация объектов 101
4.2.3. Глобальные переменные 101
4.3. Представление знаний 101
- Эвристические знания 102
- Процедурные знания 102
Функции 102
Родовые функции 103
Обработчики сообщений 103
Модули 103
4.4. Объектно-ориентированные возможности CLIPS 103
- Отличия COOL от других объектно-ориентированных языков 103
- Основные возможности ООП 104
- Запросы и наборы объектов 104
ЧАСТЬ III. ОСНОВНЫЕ КОНСТРУКЦИИ CLIPS 105
Глава 5. Факты 106
- Факты в CLIPS 106
- Работа с фактами 107
- Конструктор deftemplate 108
- Конструктор deffacts 113
- Функция assert 115
- Функция retract 117
- Функция modify 118
- Функция duplicate 120
- Функция assert-string 121
- Функция fact-existp 121
- Функции для работы с неупорядоченными фактами 122
5.2.10. Функции сохранения и загрузки списка фактов 124
Глава 6. Правила 126
- Создание правил. Конструктор defrule 126
- Основной цикл выполнения правил 129
- Свойства правил 130
- Свойство salience 130
- Свойство auto-focus 130
6.4. Стратегия разрешения конфликтов 131
- Стратегия глубины 131
- Стратегия ширины 131
- Стратегия упрощения 131
- Стратегия усложнения 132
- Стратегия LEX 132
- Стратегия МЕА 133
- Случайная стратегия 133
6.5. Синтаксис LHS правила 133
6.5.1. Образец (pattern СЕ) 134
Символьные ограничения 135
Групповые символы для простых и составных полей 136
Переменные, связанные с простыми и составными полями 138
Связывающие ограничения 140
Предикатные ограничения 141
Ограничения, возвращающие значения 142
Сопоставление образцов с объектами 142
Адрес образца 143
- Условный элемент test 144
- Условный элемент or. 145
- Условный элемент and 145
- Условный элемент not 146
- Условный элемент exists 148
- Условный элемент forall 149
- Условный элемент logical 150
- Автоматическое добавление и перегруппировка условных элементов 152
Безусловные правила 153
Использование элементов test и not перед and 153
Использование элемента not перед test 154
Использование элемента not перед or 154
Замечания об автоматическом добавлении и перегруппировке
условных элементов 155
6.6. Команды и функции для работы с правилами 155
- Просмотр и удаление существующих правил 155
- Сохранение правил 157
- Запуск и остановка программы 158
- Просмотр плана решения задачи 160
- Просмотр данных, способных активировать правило 132
Глава 7. Глобальные переменные 164
7.1. Конструктор defglobal и функции для работы с глобальными переменными 164
Глава 8. Функции 169
8.1. Конструктор deffunction и способы работы с внешними функциями 169
Глава 9. Разработка экспертной системы AutoExpert 173
- Исходные данные 173
- Сущности 174
- Сбор информации 175
- Диагностические правила 176
- Последние штрихи 179
- Листинг программы 180
- Запуск программы 186
ЧАСТЬ IV. ДОПОЛНИТЕЛЬНЫЕ ВОЗМОЖНОСТИ CLIPS 190
Глава 10. Родовые функции 191
- Замечание относительно термина "метод" 191
- Рекомендации по использованию родовых функций 191
- Создание родовой функции 192
- Заголовок родовой функции 193
- Индексы методов 193
- Ограничения параметров метода 193
- Групповой параметр 194
10.4. Родовое связывание 195
- Применимость методов 195
- Приоритет методов 196
- Скрытые методы 198
- Ошибки выполнения метода 198
- Значение, возвращаемое родовой функцией 198
10.5. Визуальные инструменты для работы с родовыми функциями 199
Глава 11. Объектно-ориентированный язык CLIPS 203
- Предопределенные системные классы 203
- Конструктор defclass 204
- Множественное наследование 205
- Абстрактные и конкретные классы 207
- Активные и неактивные классы 208
- Слоты класса 209
Тип слота 209
Грани значений по умолчанию 209
Грань хранения 211
Грани доступа 212
Грань распространения при наследовании 213
Грань источника 214
Грань активности при сопоставлении образцов 215
Грань видимости 216
Грань акцессоров 216
Грань переопределения сообщений 218
Грань ограничений 219
Объявление обработчиков сообщений 219
11.3. Конструктор defmessage-handler 220
- Параметры обработчиков сообщений 222
- Действия обработчиков сообщений 223
- Системные обработчики сообщений 225
Инициализация объекта 226
Удаление объекта 227
Отображение объекта 227
Изменение объекта 228
Копирование объекта 228
- Диспетчеризация сообщений 229
- Работа с объектами 230
11.5.1. Создание объекта 231
Конструктор definstances 232
- Переинициализация существующих объектов 234
- Чтение значений слотов 235
- Установка значений слотов 236
- Удаление объектов 237
- Задержка сопоставления образцов при работе с объектами 238
- Изменение объектов 238
- Дублирование объектов 239
11.6. Наборы объектов 240
- Определение набора объектов 241
- Создание набора объектов 242
- Определение запроса 243
- Определение действий 243
- Функции-запросы 244
Глава 12. Модули 248
- Создание модулей 248
- Определения модулей в конструкторах 249
- Использование модулей в командах и функциях 250
- Импорт и экспорт конструкций 251
- Импорт и экспорт фактов и объектов 253
- Модули и выполнение правил 254
Глава 13. Ограничения 255
- Атрибут типа 255
- Константный атрибут 256
- Атрибут диапазона 256
- Атрибут мощности 257
- Получение значений по умолчанию с помощью атрибутов ограничений 257
- Примеры нарушения ограничений 258
Глава 14. Разработка экспертной системы CIOS 261
- Постановка задачи 261
- Алгоритм решения задачи 264
- Представление логических элементов 264
- Связь логических элементов 269
- Дополнительные функции и переменные 270
- Реализация правил экспертной системы 271
- Листинг программы 273
- Тестирование системы 280
- Запуск программы 283
ЧАСТЬ V. ФУНКЦИИ И КОМАНДЫ CLIPS 287
Глава 15. Основные функции CLIPS 288
- Логические функции 288
- Математические функции 291
- Функции работы со строками 295
- Функции работы с составными величинами 301
- Функции ввода/вывода 307
- Процедурные функции 311
- Работа с родовыми функциями 318
- Объектно-ориентированные функции 322
- Вспомогательные функции 334
Глава 16. Основные команды CLIPS 336
- Управление интерактивной средой 336
- Работа с конструкторами deftemplate 340
- Работа с фактами 342
- Работа с конструкторами deffacts 343
- Работа с правилами 344
- Работа с планом решения задачи 346
- Работа с глобальными переменными 349
- Работа с конструкторами deffunction 350
- Работа с родовыми функциями 351
- Работа с классами и объектами 353
- Работа с конструкторами defmodule 360
- Профилирование и отладка 361
- Управление памятью 365
ЧАСТЬ VI. ПРИЛОЖЕНИЯ 367
Приложение 1. Основные БНФ-определения 368
Приложение 2. Список основных сообщений об ошибках системы CLIPS 376
Приложение 3. Список основных предупреждений системы CLIPS 384
Приложение 4. Зарезервированные имена CLIPS 385
Приложение 5. Глоссарий 389
Введение
Как-то в середине 90-х годов прошедшего столетия состоялась встреча Роберта Меткалфа, изобретателя Ethernet, и знаменитого профессора по искусственному интеллекту Эдварда Фейгенбаума. В состоявшейся дискуссии двух ученых были затронуты вопросы, связанные с состоянием дел в области искусственного интеллекта. Скептически настроенный Меткалф говорил: "Несмотря на все средства, израсходованные с 1969 года (года повального увлечения проблемами искусственного интеллекта) на работы по искусственному интеллекту, компьютер до сих пор не может разобрать примитивной устной речи и прочесть даже крупные буквы моей рукописи". Профессор Фейгенбаум признал, что "в течение долгого времени от искусственного интеллекта ожидалась большая отдача, чем он мог дать, и компании потеряли массу денег, безуспешно пытаясь использовать его в бизнесе". Однако, продолжал он, "в последнее время, как он убежден, искусственный интеллект прекрасно окупает вложенные средства, в основном в виде так называемых экспертных систем и баз знаний, способных принимать и аргументировать логические решения".
Да, в "классическом" или "традиционном" искусственном интеллекте, как сейчас называют его символьное направление, успешно создаются и развиваются экспертные системы или системы, основанные на знаниях, для широкого круга предметных областей.
Эдварда Фейгенбаума называют "отцом экспертных систем", как это значится на обложке одной из его книг "Становление экспертной компании". Он действительно стоял у истоков экспертной индустрии и создал первую экспертную систему DENDRAL в области идентификации органических соединений с помощью анализа масс-спектрограмм. Далее Фейгенбаум вместе с Шортлифом и Букхененом спроектировали первую медицинскую экспертную систему MYCIN, при этом они сделали открытие, которому было суждено существенно расширить сферу создания и использования экспертных систем. Когда они удалили из системы MYCIN базу знаний (конкретную медицинскую информацию), то осталась часть, называемая "машиной логического вывода". Было показано, что базу знаний можно изменять и заменять полностью, не нарушая целостности системы. Так возникла EMYCIN (Empty MYCIN — пустой MYCIN) или первая экспертная оболочка — инструментальная среда для построения экспертных систем различного назначения. С тех пор (с середины 70-х годов XX столетия) появилось большое число подобных инструментальных систем MicroExpert, GURU, G2, JESS и др.
В предлагаемой читателю книге освещаются вопросы теории и практики разработки экспертных систем. В качестве инструментальной среды разработки используется экспертная оболочка CLIPS. Суть технологии CLIPS заключается в том, что язык и среда CLIPS предоставляют пользователям возможность быстро создавать эффективные, компактные и легко управляемые экспертные системы. При этом пользователь применяет множество уже готовых инструментов (встроенный механизм управления базой знаний, механизм логического вывода, менеджеры различных объектов CLIPS и т. д.) и конструкций (упорядоченные факты, шаблоны, правила, функции, родовые функции, классы, модули, ограничения, встроенный язык COOL и т. д.).
Книга состоит из шести частей (часть VI — приложения, среди которых глоссарий) и списка литературы.
В части I описываются основные проблемы, связанные с разработкой экспертных систем: представление знаний, извлечение знаний, структурирование и концептуализация знаний, вывод на знаниях. Фактически это введение в инженерию знаний.
Часть II посвящена истории создания и развития инструментальной среды CLIPS, а также рассмотрению основных возможностей CLIPS.
Часть III содержит описание синтаксиса базовых конструкций языка CLIPS, необходимых для разработки экспертных систем — фактов, правил, глобальных переменных и функций. В конце данной части приводится пример разработки экспертной системы AutoExpert.
Часть IV раскрывает дополнительные возможности CLIPS, такие как использование классов и объектов, родовых функций, модулей и ограничений. Эти возможности значительно упрощают процесс создания экспертных систем. В последней главе данной части приведен пример построения экспертной системы C1OS для оптимизации бинарных таблиц соответствий логических схем, использующий описанные возможности.
Часть V содержит справочную информацию об основных функциях и командах CLIPS, необходимых разработчику, а также примеры их использования.
Часть VI объединяет приложения. В приложении I сосредоточены БНФ-определения всех основных конструкций языка CLIPS. Приложение 2 содержит список основных сообщений об ошибках среды CLIPS. В приложении 3 приводится перечень основных предупреждений среды CLIPS. Приложение 4 содержит все зарезервированные имена среды CLIPS. Приложение 5 представляет собой глоссарий используемых терминов.
В настоящий момент CLIPS является свободно распространяемым программным продуктом, который продолжает успешно развиваться и совершенствоваться. Совсем недавно, 29 марта 2002 г., появилась очередная версия CLIPS — 6.20. Несмотря на достаточно большое число зарубежных публикаций о языке и среде CLIPS, в русскоязычной литературе эта система до сих пор не освещалась. Данная книга призвана восполнить этот пробел.
Книга может использоваться в качестве учебного пособия студентами вузов при изучении дисциплин: "Интеллектуальные системы", "Системы искусственного интеллекта", "Интеллектуальные информационные системы", "Проектирование экспертных систем" и др. Книга содержит большой объем справочной информации по CLIPS, поэтому она может быть рекомендована и опытным пользователям, и программистам, которые в своей практической деятельности занимаются разработкой экспертных систем.
Авторы выражают свою признательность и благодарность Г. Г. Ворошиловой за помощь в работе при подготовке глав 15 и 16 книги к изданию и Дехкановой Марии за помощь в оформлении рисунков к части I книги.
Авторы благодарят рецензентов за ценные замечания, которые способствовали улучшению книги.
Особенную признательность авторы выражают к. т. н. А. И. Адаменко за доброжелательную помощь и поддержку при подготовке рукописи к изданию.
ЧАСТЬ I.Экспертные системы.
Глава 1. Системы, основанные на знаниях.
Глава 2. Введение в инженерию знаний.
ГЛАВА 1. Системы, основанные на знаниях.
1.1. Знания и данные
Если у вас есть проблема или задача, которую нельзя решить самостоятельно — вы обращаетесь к знающим людям, или к экспертам, к тем, кто обладает ЗНАНИЯМИ. Термин "системы, основанные на знаниях" (knowledge-based systems) появился в 1976 году одновременно с первыми системами, аккумулирующими опыт и знания экспертов. Это были экспертные системы (expert systems) MYCIN и DENDRAL [Shortliffe, 1976; Shortliffe Feigenbaum, Buchanan, 1978] для медицины и химии. Они ставили диагноз при инфекционных заболеваниях крови и расшифровывали данные масс-спектрографического анализа.
Экспертные системы появились в рамках исследований по искусственному интеллекту (ИИ) (artificial intelligence) в тот период, когда эта наука переживала серьезный кризис, и требовался существенный прорыв в развитии практических приложений. Этот прорыв произошел, когда на смену поискам универсального алгоритма мышления и решения задач исследователям пришла идея моделировать конкретные знания специалистов-экспертов. Так в США появились первые коммерческие системы, основанные на знаниях, или экспертные системы (ЭС). Эти системы по праву стали первыми интеллектуальными системами, и до сих пор единственным критерием интеллектуальности является наличие механизмов работы со знаниями.
Так появился новый подход к решению задач искусственного интеллекта — представление знаний.
Подробнее об истории искусственного интеллекта можно почитать в [Поспелов, 1986; Джексон, 2001; Гаврилова, Хорошевский, 2001; Эндрю, 1985|.
При изучении интеллектуальных систем традиционно возникает вопрос — что же такое знания и чем они отличаются от обычных данных, десятилетиями обрабатываемых на компьютерах. Можно предложить несколько рабочих определений, в рамках которых это становится очевидным.
Определение 1.1
Данные— это информация, полученная в результате наблюдений или измерений отдельных свойств (атрибутов), характеризующих объекты, процессы и явления предметной области.
Иначе, данные — это конкретные факты, такие как температура воздуха, высота здания, фамилия сотрудника, адрес сайта и пр.
При обработке на ЭВМ данные трансформируются, условно проходя следующие этапы:
- D1 — данные как результат измерений и наблюдений;
- D2 — данные на материальных носителях информации (таблицы, протоколы, справочники);
- D3 — модели (структуры) данных в виде диаграмм, графиков, функций;
- D4 — данные в компьютере на языке описания данных;
- D5 — базы данных на машинных носителях информации.
Знания же основаны на данных, полученных эмпирическим путем. Они представляют собой результат опыта и мыслительной деятельности человека, направленной на обобщение этого опыта, полученного в результате практической деятельности.
Так, если вооружить человека данными о том, что у него высокая температура (результат наблюдения или измерения), то этот факт не позволит ему решить задачу выздоровления. А если опытный врач поделится знаниями о том, что температуру можно снизить жаропонижающими препаратами и обильным питьем, то это существенно приблизит решение задачи выздоровления, хотя на самом деле нужны дополнительные данные и более глубокие знания.
Определение 1.2
Знаний— это связи и закономерности предметной области (принципы, модели, законы), полученные в результате практической деятельности и профессионального опыта, позволяющего специалистам ставить и решать задачи в данной области.
При обработке на ЭВМ знания трансформируются аналогично данным:
- Z1 — знания в памяти человека как результат анализа опыта и мышления;
- Z2 — материальные носители знаний (специальная литература, учебники, методические пособия);
- Z3 — поле знаний — условное описание основных объектов предметной области, их атрибутов и закономерностей, их связывающих;
- Z4 — знания, описанные на языках представления знаний (продукционные языки, семантические сети, фреймы — см. далее);
- Z5 — база знаний на машинных носителях информации. Часто используется и такое определение знаний:
Знания — это хорошо структурированные данные, или данные о данных, или метаданные.
Ключевым этапом при работе со знаниями является формирование поля знаний (третий этап Z3), эта нетривиальная задача включает выявление и определение объектов и понятий предметной области, их свойств и связей между ними, а также представление их в наглядной и интуитивно понятной форме. Этот термин впервые был введен при практической разработке экспертной системы по психодиагностике АВТАНТЕСТ [Гаврилова, 1984] и теперь широко используется разработчиками ЭС.
Без тщательной проработки поля знаний не может быть речи о создании базы знаний.
Существенным для понимания природы знаний являются способы определения понятий. Один из широко применяемых способов основан на идее интенсионала и экстенсионала.
Определение 1.3
Интенсионал понятия — это определение его через соотнесение с понятием более высокого уровня абстракции с указанием специфических свойств.
Например, интенсионал понятия "МЕБЕЛЬ": "предметы, предназначенные для обеспечения комфортного проживания человека и загромождающие дом".
Определение 1.4
Экстенсионал — это определение понятия через перечисление его конкретных примеров, т. е. понятий более низкого уровня абстракции.
Экстенсионал понятия "МЕБЕЛЬ": "Шкаф, диван, стол, стул и т. д.".
Интенсионалы формируют знания об объектах, в то время как экстенсионал объединяет данные. Вместе они формируют элементы поля знаний конкретной предметной области.
Для хранения данных используются базы данных (для них характерны большой объем и относительно небольшая удельная стоимость информации), для хранения знаний — базы знаний (небольшого объема, но исключительно дорогие информационные массивы).
База знаний — основа любой интеллектуальной системы, где знания описаны на некотором языке представления знаний, приближенном к естественному.
Знания можно разделить на:
- глубинные;
- поверхностные.
Поверхностные — знания о видимых взаимосвязях между отдельными событиями и фактами в предметной области.
Глубинные — абстракции, аналогии, схемы, отображающие структуру и природу процессов, протекающих в предметной области. Эти знания объясняют явления и могут использоваться для прогнозирования поведения объектов.
Поверхностные знания
"Если ввести правильный пароль, на экране компьютера появится изображение рабочего стола".
Глубинные знания
"Понимание принципов работы операционной системы и знания на уровне квалифицированного системного администратора".
Современные экспертные системы работают, в основном, с поверхностными знаниями. Это связано с тем, что на данный момент нет универсальных методик, позволяющих выявлять глубинные структуры знаний и работать с ними.
Кроме того, в учебниках по ИИ знания традиционно делят на процедурные и декларативные. Исторически первичными были процедурные знания, т. е. знания, "растворенные" в алгоритмах. Они управляли данными. Для их изменения требовалось изменять текст программ. Однако с развитием информатики и программного обеспечения все большая часть знаний сосредотачивалась в структурах данных (таблицы, списки, абстрактные типы данных), т. е. увеличивалась роль декларативных знаний.

Сегодня знания приобрели чисто декларативную форму, т. е. знаниями считаются предложения, записанные на языках представления знаний, приближенных к естественному языку и понятных неспециалистам.
Один из пионеров ИИ Алан Ньюэлл проиллюстрировал эволюцию средств общения человека с компьютером как переход от машинных кодов через символьные языки программирования к языкам представления знаний (рис. 1.1).
1.2. Модели представления знаний
В настоящее время разработаны десятки моделей (или языков) представления знаний для различных предметных областей. Большинство из них может быть сведено к следующим классам:
- продукционные модели;
- семантические сети;
- фреймы;
- формальные логические модели.
В свою очередь это множество классов можно разбить на две большие группы (рис. 1.2):
- модульные;
- сетевые.
Модульные языки оперируют отдельными (не связанными) элементами знаний, будь то правила или аксиомы предметной области.
Сетевые языки предоставляют возможность связывать эти элементы или фрагменты знаний через отношения в семантические сети или сети фреймов.
Рассмотрим подробнее наиболее популярные у разработчиков языки представления знаний (ЯПЗ).

1.2.1. Продукционная модель
ЯПЗ, основанные на правилах (rule-based), являются наиболее распространенными и более 80% ЭС используют именно их.
Определение 1.5
Продукционная модель или модель, основанная на правилах, позволяет представить знания в виде предложений типа "Если (условие), то (действие)".
Под "условием" (антецедентом) понимается некоторое предложение-образец, по которому осуществляется поиск в базе знаний, а под "действием" (консеквентом) — действия, выполняемые при успешном исходе поиска (они могут быть промежуточными, выступающими далее как условия, и терминальными или целевыми, завершающими работу системы).
Чаще всего вывод на такой базе знаний бывает прямой (от данных к поиску цели) или обратный (от цели для ее подтверждения — к данным). Данные — это исходные факты, хранящиеся в базе фактов, на основании которых запускается машина вывода или интерпретатор правил, перебирающий правила из продукционной базы знаний (см. разд. 1.3).
Продукционная, модель так часто применяется в промышленных экспертных системах, поскольку привлекает разработчиков своей наглядностью, высокой модульностью, легкостью внесения дополнений и изменений и простотой механизма логического вывода.
Имеется большое число программных средств, реализующих продукционный подход (например, языки высокого уровня CLIPS и OPS 5; "оболочки" или "пустые" ЭС — EXSYS Professional и Карра, инструментштьные системы КЕЕ, ARTS, PIES [Хорошевский, 1993]), а также промышленных ЭС на его основе (например, ЭС, созданных средствами G2 [Попов, 1996]). Подробнее см. [Попов, Фоминых и др., 1996; Хорошевский, 1993; Гаврилова, Хорошевский, 2001; Durkin, 1998].
1.2.2.Семантические сети
Термин "семантическая" означает "смысловая", а сама семантика — это наука, устанавливающая отношения между символами и объектами, которые они обозначают, т. е. наука, определяющая смысл знаков. Модель на основе семантических сетей была предложена американским психологом Куиллиа-ном. Основным ее преимуществом является то, что она более других соответствует современным представлениям об организации долговременной памяти человека [Скрэгг, 1983].
Определение 1.6
Семантическая сеть — это ориентированный граф, вершины которого — понятия, а дуги — отношения между ними.
В качестве понятий обычно выступают абстрактные или конкретные объекты, а отношения это связи типа: "это" ("АКО — A-Kind-Of, "is" или "элемент класса"), "имеет частью" ("has part"), "принадлежит", "любит".
Можно предложить несколько классификаций семантических сетей, связанных с типами отношений между понятиями.
-По количеству типов отношений:
- однородные (с единственным типом отношений);
- неоднородные (с различными типами отношений).
-По типам отношений:
- бинарные (в которых отношения связывают два объекта);
• N-арные (в которых есть специальные отношения, связывающие более двух понятий).
Наиболее часто в семантических сетях используются следующие отношения:
- элемент класса (роза это цветок);
- атрибутивные связи /иметь свойство (память имеет свойство — объем);
- значение свойства (цвет имеет значение — желтый);
- пример элемента класса (роза, например — чайная);
- связи типа "часть-целое" (велосипед включает руль);
- функциональные связи (определяемые обычно глаголами "производит", "влияет"...);
- количественные (больше, меньше, равно...);
- пространственные (далеко от, близко от, за, под, над...);
- временные (раньше, позже, в течение...);
- логические связи (и, или, не) и др.
Минимальный состав отношений в семантической сети таков:
- элемент класса или АКО;
- атрибутивные связи /иметь свойство;
- значение свойства.
Недостатком этой модели является сложность организации процедуры организации вывода на семантической сети.
Эта проблема сводится к нетривиальной задаче поиска фрагмента сети, соответствующего некоторой подсети, отражающей поставленный запрос к базе.
На рис. 1.3 изображен пример семантической сети. В качестве вершин тут выступают понятия "человек", "т. Смирнов", "Audi A4", "автомобиль", "вид транспорта" и "двигатель".

Рис. 1.3. Семантическая сеть
Для реализации семантических сетей существуют специальные сетевые языки, например, NET [Цейтин, 1985], язык реализации систем SIMER + MIR [Осипов, 1997] и др. Широко известны экспертные системы, использующие семантические сети в качестве языка представления знаний — PROSPECTOR, CASNET, TORUS [Хейес-Рот и др., 1987; Durkin, 1998].
1.2.3. Фреймы
Термин фрейм (от англ. frame — "каркас" или "рамка") был предложен Марвином Минским [Минский, 1979], одним из пионеров ИИ, в 70-е годы для обозначения структуры знаний для восприятия пространственных сцен. Эта модель, как и семантическая сеть, имеет глубокое психологическое обоснование.
Определение 1.7
Фрейм — это абстрактный образ для представления стереотипа объекта, понятия или ситуации.
Интуитивно понятно, что под абстрактным образом понимается некоторая обобщенная и упрощенная модель или структура. Например, произнесение вслух слова "комната" порождает у слушающих образ комнаты: "жилое помещение с четырьмя стенами, полом, потолком, окнами и дверью, площадью 6—20 м2". Из этого описания ничего нельзя убрать (например, убрав окна, мы получим уже чулан, а не комнату), но в нем есть "дырки" или "слоты"— это незаполненные значения некоторых атрибутов — например, количество окон, цвет стен, высота потолка, покрытие пола и др.
В теории фреймов такой образ комнаты называется фреймом комнаты. Фреймом также называется и формализованная модель для отображения образа.
Различают фреймы-образцы или прототипы, хранящиеся в базе знаний, и фреймы-экземпляры, которые создаются для отображения реальных фактических ситуаций на основе поступающих данных. Модель фрейма является достаточно универсальной, поскольку позволяет отобразить все многообразие знаний о мире через:
- фреймы-структуры, использующиеся для обозначения объектов и понятий (заем, залог, вексель);
- фреймы-роли (менеджер, кассир, клиент);
- фреймы-сценарии (банкротство, собрание акционеров, празднование именин);
- фреймы-ситуации (тревога, авария, рабочий режим устройства) и др.
Традиционно структура фрейма может быть представлена как список свойств:
(ИМЯ ФРЕЙМА:
(имя 1-го слота: значение 1-го слота),
(имя 2-го слота: значение 2-го слота),
…………….
(имя N-гo слота: значение N-го слота)).
Ту же запись можно представить в виде таблицы (см. табл. 1.1), дополнив ее двумя столбцами.
Таблица 1.1. Структура фрейма
| Имя фрейма | |||
| Имя слота | Значение слота | Способ получения значения | Присоединенная процедура |
В таблице дополнительные столбцы (3-й и 4-й) предназначены для описания способа получения слотом его значения и возможного присоединения к тому или иному слоту специальных процедур, что допускается в теории фреймов. В качестве значения слота может выступать имя другого фрейма, так образуются сети фреймов.
Существует несколько способов получения слотом значений во фрейме-экземпляре:
- по умолчанию от фрейма-образца (Default-значение);
- через наследование свойств от фрейма, указанного в слоте АКО;
- по формуле, указанной в слоте;
- через присоединенную процедуру;
- явно из диалога с пользователем;
- из базы данных.
Важнейшим свойством теории фреймов является заимствование из теории семантических сетей — так называемое наследование свойств. И во фреймах, и в семантических сетях наследование происходит по АКО-связям (A-Kind-Of = это). Слот АКО указывает на фрейм более высокого уровня иерархии, откуда неявно наследуются, т. е. переносятся, значения аналогичных слотов.
Например, в сети фреймов на рис. 1.4 понятие "ученик" наследует свойства фреймов "ребенок" и "человек", которые находятся на более высоком уровне иерархии. На вопрос "любят ли ученики сладкое?" следует ответ "да", т. к. этим свойством обладают все дети, что указано во фрейме "ребенок". Наследование свойств может быть частичным: возраст для учеников не наследуется из фрейма "ребенок", поскольку указан явно в своем собственном фрейме.

Рис. 1.4. Сеть фреймов
Основным преимуществом фреймов как модели представления знаний является то, что она отражает концептуальную основу организации памяти человека [Шенк, Хантер, 1987], а также ее гибкость и наглядность.
Специальные языки представления знаний в сетях фреймов FRL (Frame Representation Language) [Байдун, Бунин, 1990], KRL (Knowledge Representation Language) [Уотермен, 1989], фреймовая "оболочка" Kappa [Стрельников, Борисов, 1997] и другие программные средства позволяют эффективно строить промышленные ЭС. Широко известны такие фрейм-ориентированные экспертные системы, как ANALYST, МОДИС, TRISTAN, ALTERID [Ковригин, Перфильев, 1988; Николов, 1988; Sisodia, Warkentin, 1992].
1.2.4. Формальные логические модели
Традиционно в представлении знаний выделяют формальные логические модели, основанные на классическом исчислении предикатов 1-го порядка, когда предметная область или задача описывается в виде набора аксиом. Реально исчисление предикатов 1-го порядка в промышленных экспертных системах практически не используется. Эта логическая модель применима в основном в исследовательских "игрушечных" системах, т. к. предъявляет очень высокие требования и ограничения к предметной области. В промышленных же экспертных системах используются различные ее модификации и расширения, изложение которых выходит за рамки этой книги. См. [Ада-менко, Кучуков, 2003].
1.3. Вывод на знаниях
Как уже сказано в разд. 1.2, наибольшее распространение получила продукционная модель представления знаний. При ее использовании база знаний состоит из набора правил, а программа, управляющая перебором правил, называется машиной вывода.
Определение 1.8
Машина вывода (интерпретатор правил) — это программа, имитирующая логический вывод эксперта, пользующегося данной продукционной базой знаний для интерпретации поступивших в систему данных.
Обычно она выполняет две функции:
- просмотр существующих данных (фактов) из рабочей памяти (базы данных) и правил из базы знаний и добавление (по мере возможности) в рабочую память новых фактов;
- определение порядка просмотра и применения правил. Этот механизм управляет процессом консультации, сохраняя для пользователя информацию о полученных заключениях, и запрашивает у него информацию, когда для срабатывания очередного правила в рабочей памяти оказывается недостаточно данных [Осуга, Саэки, 1990].
В подавляющем большинстве систем, основанных на знаниях, механизм вывода представляет собой небольшую по объему программу и включает двакомпонента — один реализует собственно вывод, другой управляет этим процессом.
Действие компонента вывода основано на применении правила, называемого modus ponens: "Если известно, что истинно утверждение А, и существует правило вида "ЕСЛИ А, ТО В", тогда утверждение В также истинно".
Таким образом, правила срабатывают, когда находятся факты, удовлетворяющие их левой части: если истинна посылка, то должно быть истинно и заключение.
Компонент вывода должен функционировать даже при недостатке информации. Полученное решение может и не быть точным, однако система не должна останавливаться из-за того, что отсутствует какая-либо часть входной информации.
Управляющий компонент определяет порядок применения правил и выполняет четыре функции:
- Сопоставление— образец правила сопоставляется с имеющимися фактами.
- Выбор — если в конкретной ситуации могут быть применены сразу несколько правил, то из них выбирается одно, наиболее подходящее по заданному критерию (разрешение конфликта).
- Срабатывание — если образец правила при сопоставлении совпал с какими-либо фактами из рабочей памяти, то правило срабатывает.
- Действие — рабочая память подвергается изменению путем добавления в нее заключения сработавшего правила. Если в правой части правила содержится указание на какое-либо действие, то оно выполняется (как, например, в системах обеспечения безопасности информации).
Интерпретатор продукций работает циклически. В каждом цикле он просматривает все правила, чтобы выявить те, посылки которых совпадают с известными на данный момент фактами из рабочей памяти. После выбора правило срабатывает, его заключение заносится в рабочую память, и затем цикл повторяется сначала.
В одном цикле может сработать только одно правило. Если несколько правил успешно сопоставлены с фактами, то интерпретатор производит выбор по определенному критерию единственного правила, которое срабатывает в данном цикле. Цикл работы интерпретатора схематически представлен на рис. 1.5.
Информация из рабочей памяти последовательно сопоставляется с посылками правил для выявления успешного сопоставления. Совокупность отобранных правил составляет так называемое конфликтное множество. Для разрешения конфликта интерпретатор имеет критерий, с помощью которого он выбирает единственное правило, после чего оно срабатывает. Это выражается в занесении фактов, образующих заключение правила, в рабочую
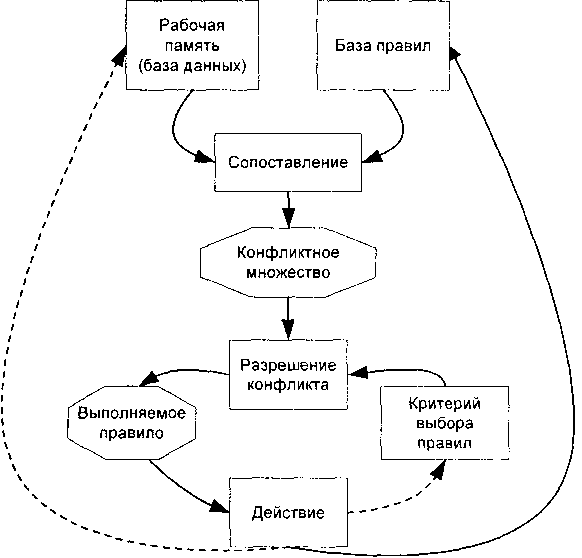
Рис. 1.5. Цикл работы интерпретатора

память или в изменении критерия выбора конфликтующих правил. Если же в заключение правила входит название какого-нибудь действия, то оно выполняется.
Работа машины вывода зависит только от состояния рабочей памяти и от состава базы знаний. На практике обычно учитывается история работы, т. е. поведение механизма вывода в предшествующих циклах. Информация о поведении механизма вывода запоминается в памяти состояний (рис. 1.6). Обычно память состояний содержит протокол системы.
1.3.1. Управление выводом
От выбранного метода поиска, т. е. стратегии вывода, будет зависеть порядок применения и срабатывания правил. Процедура выбора сводится к определению направления поиска и способа его осуществления. Процедуры, реализующие поиск, обычно "зашиты" в механизм вывода, поэтому в большинстве систем инженеры знаний не имеют к ним доступа и, следовательно, не могут в них ничего изменять по своему желанию.
При разработке стратегии управления выводом важны:
- исходная точка в пространстве состояний. От выбора этой точки зависит и метод осуществления поиска — в прямом или в обратном направлении.
- метод и стратегия перебора — в глубину, в ширину, по подзадачам или иначе.
При обратном порядке вывода вначале выдвигается некоторая гипотеза, а затем механизм вывода как бы возвращается назад, переходя к фактам, пытаясь найти те, которые подтверждают гипотезу (рис. 1.7, правая часть). Если она оказалась правильной, то выбирается следующая гипотеза, детализирующая первую и являющаяся по отношению к ней подцелью. Далее отыскиваются факты, подтверждающие истинность подчиненной гипотезы. Вывод такого типа называется управляемым целями, или управляемым консеквентами. Обратный поиск применяется в тех случаях, когда цели известны и их сравнительно немного.
В системах с прямым выводом по известным фактам отыскивается заключение, которое из этих фактов следует (см. рис. 1.7, левая часть). Если такое заключение удается найти, то оно заносится в рабочую память. Прямой вывод часто называют выводом, управляемым данными, или выводом, управляемым антецедентами.
Существуют системы, в которых вывод основывается на сочетании упомянутых выше методов — обратного и ограниченного прямого. Такой комбинированный метод получил название циклического.
Пусть имеется фрагмент базы знаний из двух правил:
- П1: Если "отдых — летом" и "человек — активный", то "ехать в горы".
- П2: Если "любит солнце", то "отдых летом".

Рис. 1.7. Стратегии вывода
Предположим, в систему поступили факты — "человек активный" и "любит солнце".
ПРЯМОЙ ВЫВОД— исходя из фактических данных, получить рекомендацию.
- 1-й проход.
- Шаг 1. Пробуем /7/, не работает (не хватает данных "отдых — летом").
- Шаг 2. Пробуем /72, работает, в базу поступает факт "отдых — летом".
- 2-й проход.
• Шаг 3. Пробуем Я/, работает, активизируется цель "ехать в горы",
которая и выступает как совет, который дает ЭС.
ОБРАТНЫЙ ВЫВОД— подтвердить выбранную цель при помощи имеющихся правил и данных.
- 1-й проход.
• Шаг 1. Цель — "ехать в горы": пробуем П1 — данных "отдых — летом"
нет, они становятся новой целью и ищется правило, где она в левой
части.
• Шаг 2. Цель "отдых — летом": правило П2 подтверждает цель и акти-
визирует ее.
- 2-й проход.
• Шаг 3. Пробуем П1, подтверждается искомая цель.
1.3.2. Методы поиска в глубину и в ширину
В системах, база знаний которых насчитывает сотни правил, желательным является использование стратегии управления выводом, позволяющей минимизировать время поиска решения и тем самым повысить эффективность вывода. К числу таких стратегий относятся: поиск в глубину, поиск в ширину, разбиение на подзадачи и альфа-бета-алгоритм [Таунсенд, Фохт, 1991; Уэно, Исидзука, 1989; Справочник по ИИ, 1990].
При поиске в глубину в качестве очередной подцели выбирается та, которая соответствует следующему, более детальному уровню описания задачи. Например, диагностирующая система, сделав на основе известных симптомов предположение о наличии определенного заболевания, будет продолжать запрашивать уточняющие признаки и симптомы этой болезни до тех пор, пока полностью не опровергнет выдвинутую гипотезу.
При поиске в ширину, напротив, система вначале проанализирует все симптомы, находящиеся на одном уровне пространства состояний, даже если они относятся к разным заболеваниям, и лишь затем перейдет к симптомам следующего уровня детальности.
Разбиение на подзадачи подразумевает выделение подзадач, решение которых рассматривается как достижение промежуточных целей на пути к конечной цели. Примером, подтверждающим эффективность разбиения на подзадачи, является поиск неисправностей в компьютере — сначала выявляется отказавшая подсистема (питание, память и т. д.), что значительно сужает пространство поиска. Если удается правильно понять сущность задачи и оптимально разбить ее на систему иерархически связанных целей-подцелей, то можно добиться того, что путь к ее решению в пространстве поиска будет минимален.
Альфа-бета-алгоритм позволяет уменьшить пространство состояний путем удаления ветвей, не перспективных для успешного поиска. Поэтому просматриваются только те вершины, в которые можно попасть в результате следующего шага, после чего неперспективные направления исключаются. Альфа-бета-алгоритм нашел широкое применение в основном в системах, ориентированных на различные игры, например, в шахматных программах.
1.4. Работа с нечеткостью
При формализации знаний существует проблема, затрудняющая использование традиционного математического аппарата. Это проблема описания понятий, оперирующих качественными характеристиками объектов (много, мало, сильный, очень сильный и т. п.). Эти характеристики обычно размыты и не могут быть однозначно интерпретированы, однако содержат важную информацию (например, "одним из возможных признаков гриппа является высокая температура").
Кроме того, в задачах, решаемых интеллектуальными системами, часто приходится пользоваться неточными знаниями, которые не могут быть интерпретированы как полностью истинные или ложные (логические true/false или 0/1). Существуют знания, достоверность которых выражается некоторой промежуточной цифрой, например 0,7.
Как, не разрушая свойства размытости и неточности, представлять подобные знания формально? Для разрешения таких проблем в начале 70-х годов XX века американский математик Лотфи Заде предложил формальный аппарат нечеткой (fuzzy) алгебры и нечеткой логики [Заде, 1972]. Позднее это направление получило широкое распространение [Орловский, 1981; Аверкин и др., 1986; Яшин, 1990] и положило начало одной из ветвей ИИ под названием мягкие вычисления (soft computing).
Л. Заде ввел одно из главных понятий в нечеткой логике — понятие лингвистической переменной.
Лингвистическая переменная (ЛП) — это переменная, значение которой определяется набором вербальных (т. е. словесных) характеристик некоторого свойства.
Например, ЛП "рост" определяется через набор {карликовый, низкий, средний, высокий, очень высокий}.
1.4.1. Основы теории нечетких множеств
Значения лингвистической переменной (ЛП) определяются через так называемые нечеткие множества (НМ), которые в свою очередь определены на некотором базовом наборе значений или базовой числовой шкале, имеющей размерность. Каждое значение ЛП определяется как нечеткое множество (например, НМ "низкий рост").
Нечеткое множество определяется через некоторую базовую шкалу В и функцию принадлежности НМ — ![]() (х), х
(х), х![]() B Д принимающую значения на интервале [0; 1]. Таким образом, нечеткое множество B — это совокупность пар вида (х,
B Д принимающую значения на интервале [0; 1]. Таким образом, нечеткое множество B — это совокупность пар вида (х, ![]() (х)), где х
(х)), где х ![]() В. Часто встречается и такая запись:
В. Часто встречается и такая запись:
![]()
где хi — i-е значение базовой шкалы.
Функция принадлежности определяет субъективную степень уверенности эксперта в том, что данное конкретное значение базовой шкалы соответствует определяемому НМ. Эту функцию не стоит путать с вероятностью, носящей объективный характер и подчиняющейся другим математическим зависимостям.
Например, для двух экспертов определение НМ "высокая" для ЛП "цена автомобиля" в условных единицах может существенно отличаться в зависимости от их социального и финансового положения.
"Высокая_цена_автомобиля_1" = {50000/1 + 25000/0.8 + 10000/0.6 + 5000/0.4}
"Высокая_цена_автомобиля_2" = {25000/1 + 10000/0.8 + 5000/0.7 + 3000/0.4}
Пусть перед нами стоит задача интерпретации значений ЛП "возраст", таких как "молодой" возраст, "преклонный" возраст или "переходный" возраст. Определим "возраст" как ЛП (рис. 1.8). Тогда "молодой", "преклонный", "переходный" будут значениями этой лингвистической переменной. Более полно, базовый набор значений ЛП "возраст" следующий:
В = {младенческий, детский, юный, молодой, зрелый, преклонный, старческий}.

Рис. 1.8. Лингвистическая переменная "возраст" и нечеткие множества, определяющие ее значения
Для ЛП "возраст" базовая шкала — это числовая шкала от 0 до 120, обозначающая количество прожитых лет, а функция принадлежности определяет, насколько мы уверены в том, что данное количество лет можно отнести к данной категории возраста. На рис. 1.9 отражено, как одни и те же значения базовой шкалы могут участвовать в определении различных НМ.
Например, определить значение НМ "младенческий" можно так:
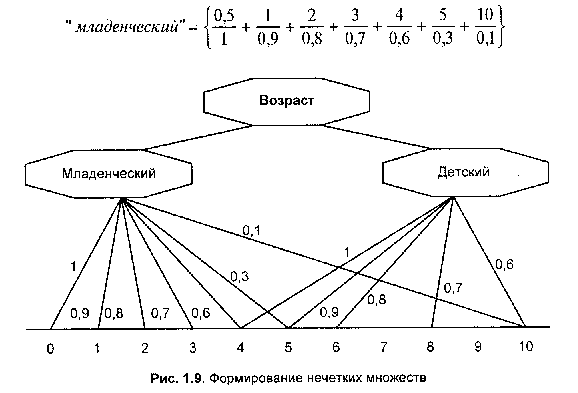

Рис. 1.10 иллюстрирует оценку НМ неким усредненным экспертом, который ребенка до полугода с высокой степенью уверенности относит к младенцам ( = 1). Дети до четырех лет причисляются к младенцам тоже, но с меньшей степенью уверенности (0,5 < < 0,9), а в десять лет ребенка называют так только в очень редких случаях — к примеру, для девяностолетней бабушки и 15 лет может считаться младенчеством. Таким образом, нечеткие множества позволяют при определении понятия учитывать субъективные мнения отдельных индивидуумов.
1.4.2. Операции с нечеткими знаниями
Для операций с нечеткими знаниями, выраженными при помощи лингвистических переменных, существует много различных способов. Эти способы являются в основном эвристиками.
Мы не будем останавливаться на этом вопросе подробно, укажем лишь для примера определение нескольких операций. Например, операция "ИЛИ" часто задается так [Аверкин и др., 1986; Яшин, 1990]:
![]()
(так называемая логика Заде) или так:
![]()
(вероятностный подход).
Усиление иди ослабление лингвистических понятий достигается введением специальных квантификаторов. Например, если понятие "старческий возраст" определяется как
то понятие "очень старческий возраст" распознается как
con (А) = А2 =![]()
т. е. очень старческий возраст определится так:
Для вывода на нечетких множествах используются специальные отношения и операции над ними (подробнее см. [Орловский, 1981]).
Одним из первых применений теории НМ стало использование коэффициентов уверенности для вывода рекомендаций медицинской системы MYC1N [Shortliffe, 1976]. Этот метод использует несколько эвристических приемов. Он стал примером обработки нечетких знаний, повлиявших на последующие системы.
В настоящее время в большинство инструментальных средств разработки систем, основанных на знаниях, включены элементы работы с НМ, кроме того, разработаны специальные программные средства реализации так называемого нечеткого вывода, например "оболочка" FuzzyCLIPS.
1.5. Архитектура и особенности экспертных систем
Центральная парадигма интеллектуальных технологий сегодня — это обработка знаний. Системы, ядром которых является база знаний или модель предметной области, описанная на языке сверхвысокого уровня, приближенном к естественному, называют интеллектуальными.
Чаще всего интеллектуальные системы (ИС) применяются для решения сложных задач, где основная сложность решения связана с использованием слабоформализованных знаний специалистов-практиков и где логическая (или смысловая) обработка информации превалирует над вычислительной. Например, понимание естественного языка, поддержка принятия решения в сложных ситуациях, постановка диагноза и рекомендации по методам лечения, анализ визуальной информации, управление диспетчерскими пультами и др.
Фактически сейчас прикладные интеллектуальные системы используются в десятках тысяч приложений. А годовой доход от продаж программных и аппаратных средств искусственного интеллекта еще в 1989 г. в США составлял 870 млн. долларов, а в 1990 г. — 1,1 млрд. долларов [Попов, 1996]. В дальнейшем почти тридцати процентный прирост дохода сменился более плавным наращиванием темпов (по материалам [Поспелов, 1997; Хорошевский, 1997; Попов, 1996; Walker, Miller, 1987; Tuthill, 1994; Durkin, 1998]).
Наиболее распространенным видом ИС являются экспертные системы.
Определение 1.9
Экспертные системы (ЭС)— это наиболее распространенный класс ИС, ориентированный на тиражирование опыта высококвалифицированных специалистов в областях, где качество принятия решений традиционно зависит от уровня экспертизы, например таких, как медицина, юриспруденция, геология, экономика, военное дело и др.
ЭС эффективны лишь в специфических "экспертных" областях, где важен эмпирический опыт специалистов.
Только в США ежегодный доход от продаж инструментальных средств разработки ЭС составлял в начале 90-х годов 300—400 млн. долларов, а от применения ЭС — 80—90 млн. долларов [Попов, 1996]. Ежегодно крупные фирмы разрабатывают десятки ЭС типа "in-house" для внутреннего пользования. Эти системы интегрируют опыт специалистов компании по ключевым и стратегически важным технологиям. В начале 90-х гг. появилась новая наука— "управление знаниями" (knowledge management), ориентированная на методы обработки и управления корпоративными знаниями (Borghoff, 1998; Гаврилова, Хорошевский, 2001).
Современные ЭС — это сложные программные комплексы, аккумулирующие знания специалистов в конкретных предметных областях и распространяющие этот эмпирический опыт для консультирования менее квалифицированных пользователей. Разработка экспертных систем, как активно развивающаяся ветвь информатики, направлена на использование ЭВМ для обработки информации в тех областях науки и техники, где традиционные математические методы моделирования малопригодны. В этих областях важна смысловая и логическая обработка информации, важен опыт экспертов.
Основные факторы, влияющие на целесообразность и эффективность разработки ЭС (частично из [Уотермен, 1989]):
- нехватка специалистов, затрачивающих значительное время для оказания помощи другим;
- выполнение небольшой задачи требует многочисленного коллектива специалистов, поскольку ни один из них не обладает достаточным знанием;
- сниженная производительность, поскольку задача требует полного анализа сложного набора условий, а обычный специалист не в состоянии просмотреть (за отведенное время) все эти условия;
- большое расхождение между решениями самых хороших и самых плохих исполнителей;
- наличие экспертов, готовых поделиться своим опытом. Подходящие задачи имеют следующие характеристики:
- не могут быть решены средствами традиционного математического моделирования;
- имеется "шум" в данных — некорректность определений, неточность, неполнота, противоречивость информации;
- условий, ограничений;
- являются узкоспециализированными;
- не зависят в значительной степени от общечеловеческих знаний или соображений здравого смысла;
- не являются для эксперта ни слишком легкими, ни слишком сложными. (Время, необходимое эксперту для решения проблемы, может составлять от трех часов до трех недель.)
Хотя экспертные системы достаточно молоды — первые системы такого рода MYCIN появились в США в середине 70-х годов. В настоящее время в мире насчитывается несколько тысяч промышленных ЭС, которые дают советы:
- при управлении сложными диспетчерскими пультами, например, сети распределения электроэнергии;
- при постановке медицинских диагнозов;
- при поиске неисправностей в электронных приборах, диагностика отказов контрольно-измерительного оборудования;
- по проектированию интегральных схем;
- по управлению перевозками;
- по прогнозу военных действий;
- по формированию портфеля инвестиций, оценке финансовых рисков, налогообложению и т. д.
Наиболее популярные приложения ИС отражены на рис. 1.11 [Durkin, 1998].

Рис. 1.11. Основные приложения ИС
Сейчас легче назвать области, не использующие ЭС, чем те, где они уже применяются. Уже в 1987 году опрос пользователей, проведенный журналом "Intelligent Technologies" (США), показал, что примерно:
- 25% пользователей используют ЭС;
- 25% собираются приобрести ЭС в ближайшие 2—3 года;
- 50% предпочитают провести исследование об эффективности их использования.
Главное отличие ИС и ЭС от других программных средств — это наличие базы знаний (БЗ), в которой знания хранятся в форме, понятной специалистам предметной области, и могут быть изменены и дополнены также в понятной форме. Это и есть языки представления знаний — ЯПЗ.
До последнего времени именно различные ЯПЗ были центральной проблемой при разработке ЭС.
Для перечисленных в разд. 1.2 моделей существует соответствующая математическая нотация, разработаны системы программирования, реализующие эти ЯПЗ, и имеется большое количество реальных коммерческих ЭС. Подробнее вопросы программной реализации прикладных ИС рассмотрены в книге далее.
В России в исследования и разработку ЭС большой вклад внесли работы Д. А. Поспелова (основателя Российской ассоциации искусственного интеллекта и его первого президента), Э. В. Попова, В. Ф. Хорошевского, В. Л. Стефанюка, Г. С. Осипова, В. К. Финна, В. Л. Вагина, В. И. Городецкого и многих других.
Современное состояние разработок в области ЭС в России можно охарактеризовать как стадию все возрастающего интереса среди широких слоев специалистов — финансистов, топ-менеджеров, преподавателей, инженеров, медиков, психологов, программистов, лингвистов. В последние годы этот интерес имеет пока достаточно слабое материальное подкрепление — явная нехватка учебников и специальной литературы, отсутствие символьных процессоров и рабочих станций, ограниченное финансирование исследований в этой области, слабый отечественный рынок программных продуктов для разработки ЭС.
Поэтому появляется возможность распространения "подделок" под экспертные системы в виде многочисленных диалоговых систем и интерактивных пакетов прикладных программ, которые дискредитируют в глазах пользователей это чрезвычайно перспективное направление. Процесс создания экспертной системы требует участия высококвалифицированных специалистов в области искусственного интеллекта, которых пока готовит небольшое количество высших учебных заведений страны.
Наибольшие трудности в разработке ЭС вызывает сегодня не процесс машинной реализации систем, а домашинный этап анализа знаний и проектирования базы знаний. Этим занимается специальная наука — инженерия знаний (см. гл. 2).
Обобщенная структура экспертной системы представлена на рис. 1.12. Следует учесть, что реальные ЭС могут иметь более сложную структуру, однако блоки, изображенные на рисунке, непременно присутствуют в любой действительно экспертной системе, поскольку представляют собой стандарт де-факто структуры современной ЭС.

Рис. 1.12. Структура экспертной системы
В целом процесс функционирования ЭС можно представить следующим образом: пользователь, желающий получить необходимую информацию, через пользовательский интерфейс посылает запрос к ЭС; решатель, пользуясь базой знаний, генерирует и выдает пользователю подходящую рекомендацию, объясняя ход своих рассуждений при помощи подсистемы объяснений.
Так как терминология в области разработки ЭС постоянно модифицируется, определим основные термины в рамках данной книги:
- Пользователь— специалист предметной области, для которого преднаначена система. Обычно его квалификация недостаточно высока и поэтому он нуждается в помощи и поддержке своей деятельности со стороны ЭС.
- Инженер по знаниям — специалист в области искусственного интеллекта, выступающий в роли промежуточного буфера между экспертом и базой знаний. Синонимы: когнитолог, инженер-интерпретатор, аналитик.
- Интерфейс пользователя — комплекс программ, реализующих диалог пользователя с ЭС как на стадии ввода информации, так и при получении результатов.
- База знаний (БЗ) — ядро ЭС, совокупность знаний предметной области, записанная на машинный носитель в форме, понятной эксперту и пользователю (обычно на некотором языке, приближенном к естественному).
Параллельно такому "человеческому" представлению существует БЗ во внутреннем "машинном" представлении.
- Решатель — программа, моделирующая ход рассуждений эксперта на основании знаний, имеющихся в БЗ. Синонимы: дедуктивная машина, машина вывода, блок логического вывода.
- Подсистема объяснений — программа, позволяющая пользователю получить ответы на вопросы: "Как была получена та или иная рекомендация?" и "Почему система приняла такое решение?" Ответ на вопрос "как" — это трассировка всего процесса получения решения с указанием использованных фрагментов БЗ, т. е. всех шагов цепи умозаключений. Ответ на вопрос "почему" — ссылка на умозаключение, непосредственно предшествовавшее полученному решению, т. е. отход на один шаг назад. Развитые подсистемы объяснений поддерживают и другие типы вопросов.
- Интеллектуальный редактор БЗ — программа, представляющая инженеру по знаниям возможность создавать БЗ в диалоговом режиме. Включает в себя систему вложенных меню, шаблонов языка представления знаний, подсказок ("help" — режим) и других сервисных средств, облегчающих работу с базой.
Еще раз следует подчеркнуть, что представленная на рис. 1.12 структура является минимальной, что означает обязательное присутствие указанных на ней блоков. Если система объявлена разработчиками как экспертная, только наличие всех этих блоков гарантирует реальное использование аппарата обработки знаний. Однако промышленные прикладные ЭС могут быть существенно сложнее и дополнительно включать базы данных, интерфейсы обмена данными с различными пакетами прикладных программ, электронными библиотеками и т. д.
1.6. Классификация экспертных систем
Существуют различные подходы к классификации экспертных систем, т. к. класс ЭС сегодня объединяет несколько тысяч различных программных комплексов, которые можно классифицировать по десятку критериев. Полезными могут оказаться классификации, представленные на рис. 1.13.
1.6.1. Классификация по решаемой задаче
Традиционно ЭС решают следующие классы задач (примеры взяты из [Попов и др., 1996; Adeli, 1994]):
- Интерпретация данных. Это одна из традиционных задач для экспертных систем. Под интерпретацией понимается процесс определения смысла данных, результаты которого должны быть согласованными и корректными. Обычно предусматривается много вариантный анализ данных.

Рис. 1.13. Классификация экспертных систем
Например, обнаружение и идентификация различных типов океанских судов по результатам аэрокосмического сканирования — SIAP; определение основных свойств личности по результатам психодиагностического тестирования в системах АВТАНТЕСТ и МИКРОЛЮШЕР и др.
- Диагностика. Под диагностикой понимается процесс соотнесения объекта с некоторым классом объектов и/или обнаружение неисправности в некоторой системе. Неисправность — это отклонение от нормы. Такая трактовка позволяет с единых теоретических позиций рассматривать и неисправность оборудования в технических системах, и заболевания живых организмов, и всевозможные природные аномалии. Важной спецификой является здесь необходимость понимания функциональной структуры ("анатомии") диагностирующей системы. Например: диагностика и терапия сужения коронарных сосудов — ANGY; диагностика ошибок в аппаратуре и математическом обеспечении ЭВМ — система CRIB и др.
- Мониторинг. Основная задача мониторинга — непрерывная интерпретация данных в реальном масштабе времени и сигнализация о выходе тех или иных параметров за допустимые пределы. Главные проблемы — "пропуск" тревожной ситуации и инверсная задача "ложного" срабатывания. Сложность этих проблем в размытости симптомов тревожных ситуаций и необходимость учета временного контекста. Например: контроль за работой электростанций СПРИНТ, помощь диспетчерам атомного реактора — REACTOR; контроль аварийных датчиков на химическом заводе — FALCON и др.
- Проектирование. Проектирование состоит в подготовке спецификаций на создание "объектов" с заранее определенными свойствами. Под спецификацией понимается весь набор необходимых документов — чертеж, пояснительная записка и т. д. Основные проблемы здесь — получение четкого структурного описания знаний об объекте и проблема "следа". Для организации эффективного проектирования и, в еще большей степени, перепроектирования необходимо формировать не только сами проектные решения, но и мотивы их принятия. Таким образом, в задачах проектирования тесно связываются два основных процесса, выполняемых в рамках соответствующей ЭС: процесс вывода решения и процесс объяснения. Например: проектирование конфигураций ЭВМ VAX — 11/780 в системе XCON (или R1), проектирование БИС — CADHELP; синтез электрических цепей — SYN и др.
- Прогнозирование. Прогнозирование позволяет предсказывать последствия некоторых событий или явлений на основании анализа имеющихся данных. Прогнозирующие системы логически выводят вероятные следствия из заданных ситуаций. В прогнозирующей системе обычно используется параметрическая динамическая модель, в которой значения параметров "подгоняются" под заданную ситуацию. Выводимые из этой модели следствия составляют основу для прогнозов с вероятностными оценками. Например: предсказание погоды — система WILLARD; оценки будущего урожая — PLANT; прогнозы в экономике — ECON и др.
- Планирование. Под планированием понимается нахождение планов действий, относящихся к объектам, способным выполнять некоторые функции. В таких ЭС используются модели поведения реальных объектов с тем, чтобы логически вывести последствия планируемой деятельности. Например: планирование поведения робота— STRIPS; планирование промышленных заказов — 1SIS; планирование эксперимента — MOLGEN и др.
- Обучение. Под обучением понимается использование компьютера для обучения какой-то дисциплине или предмету. Системы обучения диагностируют ошибки при изучении какой-либо дисциплины с помощью ЭВМ и подсказывают правильные решения. Они аккумулируют знания о гипотетическом "ученике" и его характерных ошибках, затем в работе они способны диагностировать слабости в познаниях обучаемых и находить соответствующие средства для их ликвидации. Кроме того, они планируют акт общения с учеником в зависимости от успехов ученика с целью передачи знаний. Например: обучение языку программирования LISP в системе "Учитель LISP"; система PROUST — обучение языку Паскаль и др.
- Управление. Под управлением понимается функция организованной системы, поддерживающая определенный режим деятельности. Такого рода ЭС осуществляют управление поведением сложных систем в соответствии с заданными спецификациями. Например: помощь в управлении газовой котельной — GAS; управление системой календарного планирования Project Assistant и др.
- Поддержка принятия решений. Поддержка принятия решения — это совокупность процедур, обеспечивающая принимающего решения индивидуума необходимой информацией и рекомендациями, облегчающими процесс принятия решения. Эти ЭС помогают специалистам выбрать и/или сформировать нужную альтернативу среди множества выборов при принятии ответственных решений. Например: выбор стратегии выхода фирмы из кризисной ситуации — CRYSIS; помощь в выборе страховой компании или инвестора — CHOICE и др.
В общем случае все системы, основанные на знаниях, можно подразделить на системы, решающие задачи анализа и на системы, решающие задачи синтеза. Основное отличие задач анализа от задач синтеза заключается в том, что если в задачах анализа множество решений может быть перечислено и включено в систему, то в задачах синтеза множество решений потенциально не ограничено и строится из решений компонентов или подпроблем. Задачами анализа являются: интерпретация данных, диагностика, поддержка принятия решения; к задачам синтеза относятся проектирование, планирование, управление. Комбинированные: обучение, мониторинг, прогнозирование.
1.6.2. Классификация по связи с реальным временем
- Статические ЭС разрабатываются в предметных областях, в которых база знаний и интерпретируемые данные не меняются во времени. Они стабильны.
Пример: диагностика неисправностей в автомобиле.
- Квазидинамические ЭС интерпретируют ситуацию, которая меняется с некоторым фиксированным интервалом времени.
Пример: микробиологические ЭС, в которых снимаются лабораторные измерения с технологического процесса один раз в 4—5 часов (производство лизина, например) и анализируется динамика полученных показателей по отношению к предыдущему измерению.
- Динамические ЭС работают в сопряжении с датчиками объектов в режиме реального времени с непрерывной интерпретацией поступающих в систему данных.
Пример: управление гибкими производственными комплексами, мониторинг в реанимационных палатах.
Программный инструментарий для разработки динамических систем — G2 [Попов, 1996].
1.6.3.Классификация по типу ЭВМ
На сегодняшний день существуют:
- ЭС для уникальных стратегически важных задач на суперЭВМ (Эльбрус, CRAY, CONVEX и др.);
- ЭС на ЭВМ средней производительности (mainframe);
- ЭС на символьных процессорах и рабочих станциях (SUN, Silicon Graphics, APOLLO);
- ЭС на персональных компьютерах (IBM-совместимые, Macintosh).
1.6.4.Классификация по степени интеграции с другими программами
- Автономные ЭС работают непосредственно в режиме консультаций с пользователем для специфически "экспертных" задач, для решения которых не требуется привлекать традиционные методы обработки данных (расчеты, моделирование и т. д.).
- Гибридные ЭС представляют программный комплекс, агрегирующий стандартные пакеты прикладных программ (например, математическую статистику, линейное программирование или системы управления базами данных) и средства манипулирования знаниями. Это может быть интеллектуальная надстройка над ППП (пакетами прикладных программ) или интегрированная среда для решения сложной задачи с элементами экспертных знаний. Несмотря на внешнюю привлекательность гибридного подхода следует отметить, что разработка таких систем являет собой задачу на порядок более сложную, чем разработка автономной ЭС. Стыковка не просто разных пакетов, а различных методологий (что происходит в гибридных системах) порождает целый комплекс теоретических и практических трудностей.
1.7. Разработка экспертных систем
На сегодняшний день следует констатировать, что разработка программных комплексов экспертных систем как за рубежом, так и в нашей стране осталась скорее на уровне искусства, чем науки. Это связано с тем, что долгое время системы искусственного интеллекта внедрялись в основном во время фазы проектирования, а чаще всего разрабатывалось несколько прототип-ных версий программ, и на их основе уже создавался конечный продукт. Такой подход действует хорошо в исследовательских условиях, однако в коммерческих условиях он является слишком дорогим, чтобы оправдать затраты на разработку.
Процесс разработки промышленной экспертной системы, опираясь на традиционные технологии [Николов и др., 1990; Хейес-Рот и др., 1987; Tuthill, 1994], практически для любой предметной области можно разделить на шесть более или менее независимых этапов (рис. 1.14).

Рис. 1.14. Этапы разработки ЭС