

« СИБИРСКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ТЕЛЕКОММУНИКАЦИЙ И ИНФОРМАТИКИ На правах рукописи Нечта Иван Васильевич ...»
Таблица 2.5. Результаты работы стеготеста при ![]()
![]() , если в контейнер внедрено зашифрованное сообщение.
, если в контейнер внедрено зашифрованное сообщение.
| Размер элемента | N=100 | N=70 | N=30 | N=15 | ||||
| Род ошибки | ||||||||
| I | II | I | II | I | II | I | II | |
| L=1 | 86 | 6 | 90 | 4 | 92 | 5 | 94 | 19 |
| L=2 | 86 | 5 | 88 | 5 | 91 | 63 | 51 | 65 |
| L=3 | 83 | 6 | 93 | 6 | 13 | 97 | 100 | 0 |
| L=4 | 64 | 29 | 8 | 94 | 62 | 57 | 100 | 0 |
| L=5 | 12 | 92 | 8 | 88 | 100 | 0 | 100 | 0 |
Из представленных результатов видно, что стеготест работает лучше всего при ![]()
![]() и
и ![]()
![]() .
.
Подведем предварительные итоги. В табл. 2.6 представлены результаты работы метода при различных типах внедряемых сообщений.
Таблица 2.6. Эффективность работы разработанной схемы стегоанализа текстовых данных.
| Тип внедряемого сообщения | Род ошибки | Размер входного сообщения | |
| I рода | II рода | ||
| Естественный текст | 8 % | 16 % | 30 бит |
| Зашифрованный текст | 3 % | 5 % | 4000 бит |
2.2.4 Подбор оптимальной схемы стегоанализа
Далее, в ходе работы предлагается модифицировать предложенную схему стегоанализа. Напомним, что в предыдущем разделе главы
мы извлекали стегосообщение из текстового контейнера и разбивали
его на элементы по ![]()
![]() бит. Затем проверялась случайность распределения этих элементов. Таким образом, производилось определение наличия факта внедрения в контейнер. В ходе работы было установлено, что при
бит. Затем проверялась случайность распределения этих элементов. Таким образом, производилось определение наличия факта внедрения в контейнер. В ходе работы было установлено, что при ![]()
![]() и
и ![]()
![]() бит стегоанализ проходит наиболее эффективно[10].
бит стегоанализ проходит наиболее эффективно[10].
В целях повышения эффективности работы метода предлагается модифицировать тест хи-квадрат путем использования квантиля, подбираемого эмпирически. На рис. 2.4 показан график значений хи-квадрат, полученных от 100 сообщений, извлеченных из пустого контейнера, и от 100 сообщений из заполненных. Для наглядности значения были отсортированы по возрастанию и убыванию соответственно.
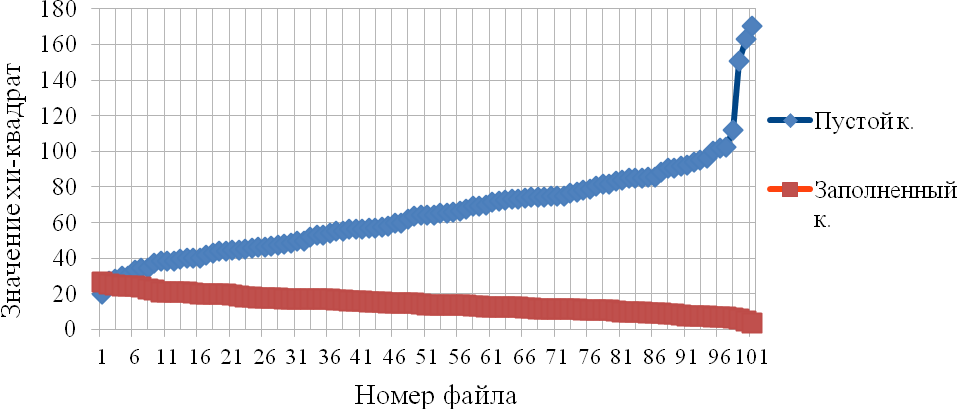
Рис. 2.4. Значения хи-квадрат, полученные для пустых и заполненных контейнеров.
Мы видим, что кривые пересекаются. Это означает, что часть сообщений, извлеченных из пустых контейнеров, статистически неразличимо от сообщений, полученных из заполненных контейнеров. Следовательно, предлагаемый метод стегоанализа будет ошибаться в ряде случаев. Подбирая значение квантиля можно уменьшать ошибку I рода, при этом будет увеличиваться ошибка II рода и наоборот. В дальнейшем, для повышения эффективности работы метода мы будем подбирать значение квантиля эмпирическим путем.
В настоящей работе для повышения точности работы стегоанализа предлагается дополнительно использовать “тест со смещением”, представленный на рис. 2.5.
Тест состоит из пяти шагов. На первом шаге извлеченное сообщение (начиная с первого бита) разбивается на элементы размером 4 бита. Далее, проверяется случайность распределения этих элементов (вышеописанным способом). На каждом последующем шаге происходит отбрасывание одного крайнего левого бита сообщения. Затем, производится аналогичное разбиение на элементы и проверка на случайность. Если на одном из пяти шагов сообщение признается неслучайным, то считается, что контейнер пуст.

Рис. 2.5. Принципиальная схема работы теста со смещением.
2.3 Экспериментальная проверка эффективности работы метода стегоанализа
В этом разделе главы мы переходим к описанию эксперимента, целью которого является определение эффективности предложенной схемы стегоанализа. Как изображено на рис. 2.6, на первом этапе определяется точность работы метода на пустых контейнерах. Набор текстов общим размером в 400 Мб, состоящий из художественных произведений [23]
на английском языке, объединялся в один файл (Text). Затем, из этого файла при помощи программы Tyranozaurus Lex извлекалось сообщение. Полученную двоичную последовательность (message) разбивали
на отдельные фрагменты (frag). Количество фрагментов в нашем эксперименте составляет не менее 1000 шт. Далее, как показано на рис. 2.6, каждый такой фрагмент анализировался с помощью разработанной программы стегоанализа. На заключительном шаге подсчитывались ошибки работы метода (ошибки I рода).
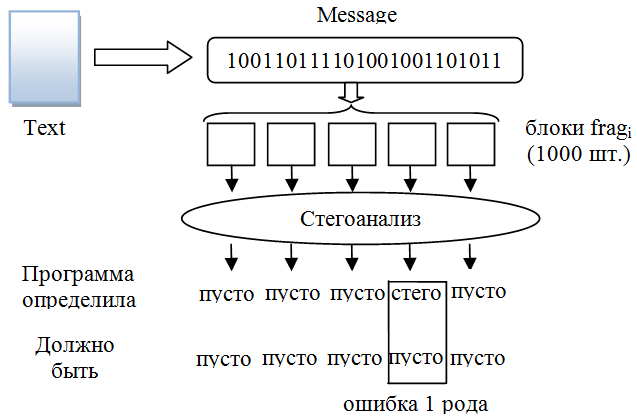
Рис. 2.6. Схема проведения эксперимента на пустых контейнерах
На втором этапе эксперимента определялась точность работы метода на заполненных контейнерах. В отличие от предыдущего раздела 2.2.3, когда секретное сообщение имитировалось при помощи линейного конгруэнтного генератора случайных чисел, здесь оно получено с помощью шифра RC6. Аналогично с первым этапом эксперимента полученное сообщение (message) разбивалось на отдельные фрагменты (frag). Затем, каждый фрагмент независимо от других анализировался с помощью разработанной программы стегоанализа. На заключительном шаге подсчитывались ошибки работы метода (ошибки II рода). По результатам проведения эксперимента были построены табл. 2.6 и табл. 2.7.
Таблица 2.6. Результаты проведения эксперимента
при.
| Квантиль | Род ошибки | Значение N | ||||
| 1000 | 900 | 800 | 700 | 600 | ||
| 28 | 1 рода | 1.0 | 1.5 | 2.5 | 4.9 | 7.9 |
| 2 рода | 5.1 | 4.9 | 5.8 | 6.3 | 5.7 | |
| 33 | 1 рода | 2.3 | 3.0 | 5.2 | 9.2 | 12.3 |
| 2 рода | 1.9 | 1.7 | 1.1 | 1.7 | 1.7 | |
| 45 | 1 рода | 9.4 | 12.7 | 16.2 | 21.2 | 29.3 |
| 2 рода | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | |
Таблица 2.7. Результаты проведения эксперимента
при.
| Квантиль | Род ошибки | Значение N | ||||
| 500 | 400 | 300 | 200 | 100 | ||
| 28 | 1 рода | 11.7 | 17.8 | 28.0 | 48.9 | 74.7 |
| 2 рода | 4.6 | 4.3 | 5.5 | 6.1 | 4.5 | |
| 33 | 1 рода | 18.8 | 27.6 | 45.8 | 67.7 | 83.8 |
| 2 рода | 1.2 | 1.2 | 1.1 | 1.9 | 1.5 | |
| 45 | 1 рода | 43.5 | 66.5 | 78.5 | 86.1 | 92.8 |
| 2 рода | 0.0 | 0.0 | 0.1 | 0.1 | 0.0 | |
Подытожим результаты. Как показали эксперименты, “тест
со смещением” позволил незначительно увеличить эффективность стегоанализа. Также было установлено, что при анализе следует использовать следующие параметры ![]()
![]() и
и ![]()
![]() бит. В табл. 2.8 приведены основные результаты работы предложенной схемы стегоанализа.
бит. В табл. 2.8 приведены основные результаты работы предложенной схемы стегоанализа.
Мы видим, что квантиль равный 33 позволяет получить наибольшую точность работы стегоанализа.
Таблица 2.8. Результаты работы метода при различных значения квантиля.
| Род ошибки | Квантиль | ||
| 28 | 33 | 45 | |
| I рода | 1.0 % | 2.3 % | 9.4 % |
| II рода | 5.1 % | 1.9 % | 0.0 % |
Выводы
Целью этой главы ставилось создание метода стегоанализа, выявляющего заполнение текстового контейнера секретным сообщением, при помощи программы [3]. Разработанный алгоритм анализирует извлеченное из контейнера сообщение, проверяя его на случайность. Таким образом, мы построили эффективный стеготест, имеющий достаточно простую реализацию, что положительно влияет на скорость его работы.
В табл. 2.9 произведено сравнение разработанного метода с известными аналогами (Taskirian C. и др. 2006 [18], Yu Z. и др. 2009 [19], Chen Z.
и др. 2011 [20]).
Из представленных результатов видно, что предложенный метод
не уступает по точности работы современным аналогам. Несмотря на то,
что реализованный алгоритм требует сравнительно больший объем данных, его реализация значительно более проста, чем у приведенных аналогов.
Таблица 2.9. Результаты сравнения метода с известными аналогами
| Метод | ||||
| Род ошибки | Chen Z. и др. 2011 | Yu Z. и др. 2009 | Taskirian C. и др. 2006 | Новый |
| I рода | 2.3 % | 7.8 % | 61.4 % | 2.3 % |
| II рода | 0.5 % | 8.9 % | 15.1 % | 1.9 % |
| Объем входных данных, бит | 100-150 | 64 | 1-4 | 4000 |
Глава 3. МЕТОД СТЕГОАНАЛИЗА ИСПОЛНЯЕМЫХ ФАЙЛОВ, БАЗИРУЮЩИЙСЯ НА КОДЕ ХАФФМАНА
3.1 Введение
В предыдущей главе диссертации мы рассматривали методы внедрения секретных сообщений в текстовые файлы. Напомним, что в качестве контейнеров могут выступать различные типы данных, например, видео, изображения и другие. Данная глава посвящена методам стеганографии исполняемых файлов, которые рассматриваются как текст на искусственном языке (машинном языке).
В отличие от других видов данных, использующихся для встраивания скрытой информации, применение исполняемых файлов в качестве контейнера имеет свою специфику. Внедрение сообщения не может быть осуществлено прямой модификацией бит программы, так как ее алгоритм работы с высокой долей вероятности разрушится. Следовательно, необходимо использовать такие методы встраивания, которые позволят сохранить работоспособность программы.
Существует два направления развития методов внедрения информации в исполняемые файлы.
Первое направление развития – это построение систем защиты авторских прав. В каждую продаваемую копию программного продукта
с помощью специальных алгоритмов внедряется особое сообщение – водяной знак, по которому, в случае обнаружения нелегальной (пиратской) копии,
с легкостью может быть прослежен исходный файл, с которого была снята эта копия и, соответственно, пользователь, нарушивший лицензионное соглашение. Очевидно, что внедряемый водяной знак должен обладать некоторой степенью устойчивости, то есть противостоять удалению
или искажению. Считается, что заранее можно предугадать, содержится
ли водяной знак или нет. Ряд публикаций, например [25-32], посвящен методам внедрения скрытой информации в программы. Подробно это направление стеганографии будет рассмотрено в главе 4.
Второе направление развития стеганографии исполняемых файлов – передача скрытых секретных сообщений. В данной работе речь пойдет
об этом направлении. За основу был взят метод, предложенный в статье [32]. Его основная идея состоит в том, чтобы размещать секретное сообщение в неиспользуемых местах секций исполняемых файлов формата Portable Executable (PE)[11]. Каждая секция такого файла должна быть размером кратным полю FileAligment (см. документацию Microsoft [33]). Таким образом, см. рис. 3.1, секция кода состоит из байтов инструкций программы и нулевых байтов выравнивания, увеличивающих секцию до требуемых размеров.

Рис. 3.1. Содержимое части секции кода исполняемого файла.
Авторы работы [32] предлагают вместо байтов выравнивания записывать секретное сообщение. По их мнению, это имеет следующие преимущества. Размер файла остается неизменным и внедренное сообщение никак не влияет на ход выполнения программы. Предполагается,
что передаваемое сообщение будет предварительно зашифровано,
и для его прочтения необходимо знать секретный ключ, а также начальную позицию сообщения в файле. Как будет показано ниже, данный подход
не является устойчивым из-за различных статистических свойств кода программы и передаваемого зашифрованного сообщения.
Во многих работах, например [34], используется подход, применяющий статистический анализ для выявления нетипичного для подавляющего большинства исполняемых файлов набора команд, способов выделения регистров, большой избыточности кода или неиспользуемых ветвей программы (т.н. мертвый код). В настоящей работе предлагается новый метод стегоанализа, предполагающий использование архиватора
для выявления случайности сообщения.
Известно, что зашифрованное сообщение выглядит как случайная последовательность. А это означает, что при сжатии архиватором такой последовательности ее размер более уменьшаться не может. Программа, наоборот, имеет часто повторяющиеся наборы двоичных инструкций. Архиватор такие повторения обнаружит, следовательно, это даст уменьшение размера при сжатии. На этой особенности и основан предлагаемый метод стегоанализа. Стоит отметить, что для выявления случайности сообщения можно использовать не только архиваторы,
но и любой другой метод кодирования, применяющийся при сжатии данных. В настоящей работе предлагается использовать кодирование Хаффмана.
3.2. Описание и построение предлагаемого метода стегоанализа
3.2.1 Описание предлагаемого метода
В данном разделе главы будет дано описание предлагаемого метода стегоанализа исполняемых файлов. Ранее уже было упомянуто, что за основу была взята схема встраивания, опубликованная в работе [32]. Указанный метод внедрения предполагает записывать сообщение в конец секции кода программы. Соответственно, для выявления факта внедрения необходимо анализировать эту же часть секции. Таким образом, предлагаемая схема стегоанализа состоит из следующих этапов:
- Извлечение исполняемой секции из файла программы;
- Удаление байтов выравнивания;
- Кодирование последних
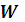
 байт секции[12] ;
байт секции[12] ; - Заключительный этап определения факта внедрения.
Этап извлечения секции кода требует определенный уровень знания
PE формата. Для начала, необходимо найти смещение заголовка PE. Одно
из полей заголовка – Section headers указывает на массив заголовков секций, каждый элемент которого описывает набор атрибутов секций файла, таких как адрес начала, размер и атрибуты секции. Определять, является ли секция кодовой (т.е. искомой), необходимо по значению бит характеристики.
Второй этап сводится к тривиальному удалению серии нулевых байт, завершающих секцию, если таковые присутствуют. Подобная ситуация может возникнуть, если была использована только часть допустимого объема внедрения.
Третий этап основывается на особенности исходного метода внедрения и заключается в том, что запись сообщения осуществляется в конец секции, непосредственно после кода программы. Следовательно, должен производиться анализ этих последних байтов (предположительное место размещения скрытого сообщения). Для простоты эту анализируемую часть секции мы будем называть “окном”.
Уточним некоторые детали, связанные с выбором величины ![]()
![]() . Здесь следует стремиться к уменьшению размера окна по следующим причинам. На рис. 3.2 показана ситуация выбора большого размера окна (заштрихованная область). В этом случае, в окно попадет и скрытое сообщение, и часть кода программы. На этапе кодирования стегосообщение
. Здесь следует стремиться к уменьшению размера окна по следующим причинам. На рис. 3.2 показана ситуация выбора большого размера окна (заштрихованная область). В этом случае, в окно попадет и скрытое сообщение, и часть кода программы. На этапе кодирования стегосообщение
в размерах практически не уменьшится, а код, из-за частого повторения одинаковых инструкций, «сожмется» значительно лучше. Следовательно,
в результате анализа таких разнородных данных нельзя однозначно определить, какими статистическими свойствами (зашифрованного сообщения или кода программы) обладает содержимое окна. Как следствие, увеличение числа ошибок работы стегоанализа.
Если выбрать маленький размер окна, как показано на рис. 3.3,
то в таком случае, анализируемые байты будут состоять только из секретного сообщения. Данные будут однородными, а это означает, что наш метод стегоанализа будет работать более точно. В тоже время, очевидно,
что чем меньше размер окна, тем меньше повторяющихся инструкций может оно содержать и, как следствие, код программы будет иметь меньше статистических отличий от зашифрованного сообщения. Оптимальный размер окна будет подбираться эмпирически в разделе 3.2.3.
На заключительном этапе по полученной длине кода можно определить, принадлежит ли анализируемая последовательность к коду программы или к зашифрованному сообщению.
3.2.2 Выбор архиватора
В этом разделе главе мы проанализируем работу различных архиваторов и выберем среди них наиболее подходящий для нашего метода.
Итак, произведем сравнение следующих архиваторов: Bzip, Bzip2, Zip, Rar, Paq8, Nanozip. Нам нужно выбрать такой архиватор, у которого размеры сжатых фрагментов программ и зашифрованных сообщений будут различаться. Исходя из того, что зашифрованное сообщение выглядит
как случайная последовательность байт, мы будем имитировать
его последовательностью, полученной с помощью генератора случайных чисел. Далее, возьмем по 1000 фрагментов размером 80 байт (причины выбора именно такого размера окна подробнее будут рассмотрены
в следующем разделе) сгенерированной случайной последовательности
и кода программы соответственно. Затем, произведем сжатие имеющихся фрагментов различными архиваторами. Получившиеся длины сжатых фрагментов будем представлять в виде интервалов. Строго говоря,
для каждого архиватора мы получим два интервала:
- интервал длин сжатых фрагментов случайной последовательности;
- интервал длин сжатых фрагментов кода.
В лучшем случае, эти два интервала не будут пересекаться. Следовательно, при стегоанализе по размеру анализируемого фрагмента можно будет однозначно определить, к какому типу данных он относится
(к коду или к секретному сообщению).
Таблица 3.1. Интервалы размеров фрагментов.
| Архиватор | Интервалы | Число пересекающихся элементов | |
| Случайная последовательность | Код | ||
| Bzip2 | [141;159] | [97;142] | 2 |
| Paq8 | [112;126] | [75;126] | 339 |
| Rar | [148;151] | [128;151] | 823 |
| Nanozip | [132;135] | [113;135] | 864 |
| Bzip | [109;112] | [94;112] | 959 |
| Zip | [188;194] | [180;194] | 994 |
Под числом пересекающихся элементов понимается количество сжатых фрагментов, размеры которых попали в оба интервала (т.е. в данном случае не получилось однозначно определить – это двоичные инструкции программы или псевдослучайная последовательность). Из таблицы видно, что наиболее подходящим архиватором для стегоанализа является Bzip2 (использующий преобразование Барроуза-Уилера и код Хаффмана), т.к. дает минимальное количество пересекающихся элементов. Как уже отмечалось ранее, вместо архиваторов можно использовать любой другой метод кодирования, применяющийся для сжатия данных. Возьмем оптимальный код Хаффмана. Для построения кода предварительно рассчитываются оценки вероятностей появления каждого символа в окне. В качестве символа
мы будем брать один байт.
Рассмотрим подробнее процесс получения оценок вероятностей. Пусть имеется алфавит ![]()
![]() , его мощность
, его мощность ![]()
![]() , где
, где ![]()
![]() . Будем говорить, что анализируемое окно состоит из символов алфавита
. Будем говорить, что анализируемое окно состоит из символов алфавита![]()
![]() . Причем символ
. Причем символ ![]()
![]() есть байт равный
есть байт равный ![]()
![]() . Введем множество счетчиков
. Введем множество счетчиков ![]()
![]() . Каждый элемент этого множества содержит число повторений соответствующего символа в окне. Следовательно, искомые оценки вероятностей
. Каждый элемент этого множества содержит число повторений соответствующего символа в окне. Следовательно, искомые оценки вероятностей ![]()
![]() появления каждого символа в окне можно вычислить по формуле:
появления каждого символа в окне можно вычислить по формуле:
![]()
![]()
Далее, по полученным оценкам вероятностей строится дерево Хаффмана. Содержимое окна кодируется, и по длине полученной последовательности определяется наличие факта внедрения. Рассмотрим интервалы для кода Хаффмана на той же выборке, что и вышеописанные архиваторы.
Таблица 3.2. Интервалы размеров фрагментов.
| Метод кодирования | Интервалы | Число пересекающихся элементов | |
| Сл. последов. | Код | ||
| Код Хаффмана | [58;64] | [19;53] | 0 |
Как видно из табл. 3.2, в отличие от архиватора Bzip2, интервалы
не пересекаются, следовательно, возможно однозначное определение факта внедрения скрытого сообщения. Таким образом, эмпирически было показано, что для нашего метода стегоанализа следует использовать оптимальный
код Хаффмана.
3.2.3 Выбор оптимального размера окна
В предыдущем разделе главы размер окна был взят ![]()
![]() байт.
байт.
Как будет показано ниже, причина выбора указанного значения обусловлена тем, что обеспечивается безошибочное (на исследуемой выборке) определение факта наличия внедрения в исполняемый файл
при минимальной длине окна.
Рассмотрим подробнее процесс подбора размера окна. Для поиска минимально допустимого значения ![]()
![]() была взята та же выборка,
была взята та же выборка,
что и в разделе 3.2.2.
Производилось кодирование содержимого окна методом Хаффмана при различных значениях ![]()
![]() (от 4 Кб до 40 байт). На рис. 3.3 и 3.4 приведены размеры закодированных фрагментов при
(от 4 Кб до 40 байт). На рис. 3.3 и 3.4 приведены размеры закодированных фрагментов при ![]()
![]() .
.
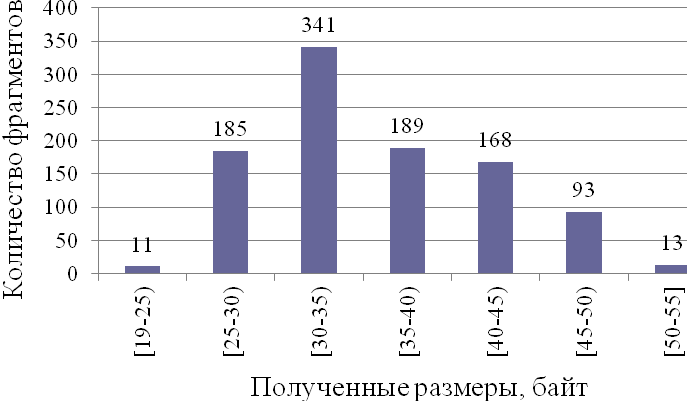
Рис. 3.3. Диаграмма размеров сжатых фрагментов программ W=80.
Мы видим, что получены два интервала размеров: [19;55] и [58;64]
для фрагментов кода и случайной последовательности соответственно. Поскольку интервалы не пересекаются, то возможно однозначное определение факта внедрения секретного сообщения.
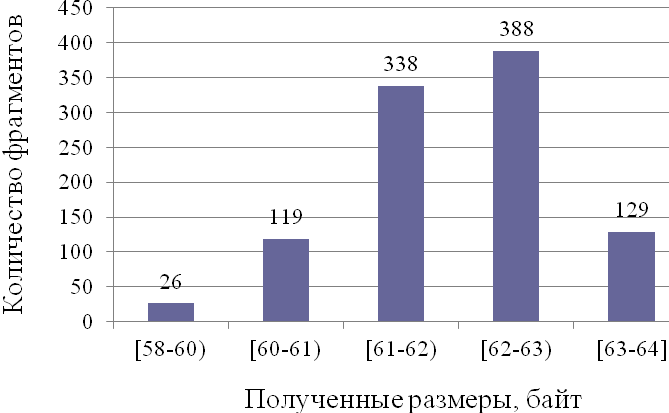
Рис. 3.4. Диаграмма размеров сжатых фрагментов псевдослучайной последовательности W=80.
Как уже упоминалось ранее, необходимо стремиться к уменьшению ![]()
![]() . Рассмотрим диаграммы при
. Рассмотрим диаграммы при ![]()
![]() байт.
байт.
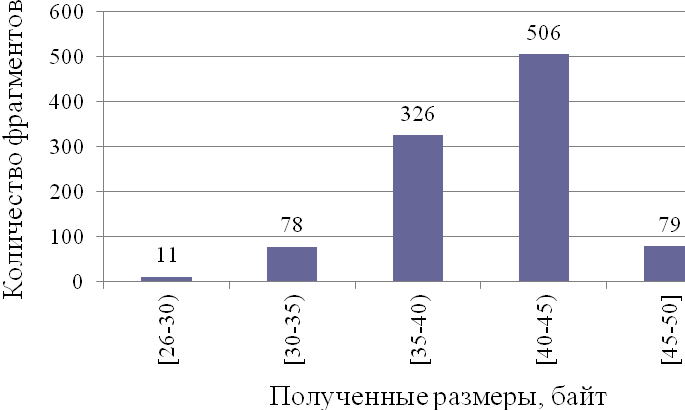
Рис. 3.5. Диаграмма размеров сжатых фрагментов программ W=70.
Из диаграмм (рис. 3.5, 3.6) видно, что при ![]()
![]() байт происходит пересечение интервалов длин ([26;50] и [49;54]). Следовательно, оптимальное значение
байт происходит пересечение интервалов длин ([26;50] и [49;54]). Следовательно, оптимальное значение ![]()
![]() составляет 80 байт.
составляет 80 байт.
Итак, мы установили, что для эффективного стегоанализа необходимо анализировать последние 80 байт окна. Если размер сжатого фрагмента окажется больше 56 байт, то будем считать, что контейнер заполнен стегосообщением. В остальных случаях – пуст.
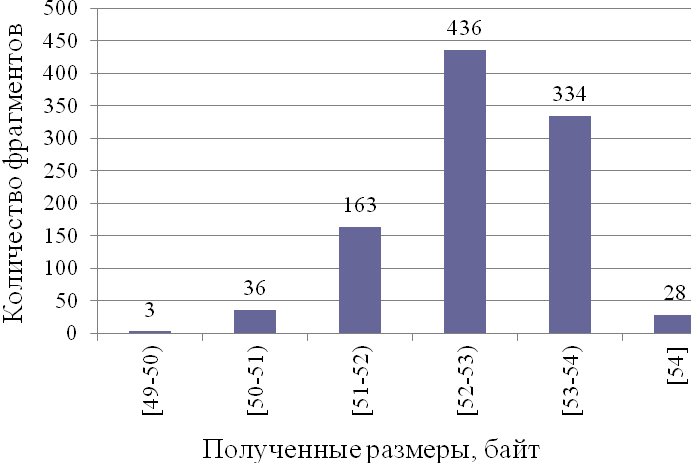
Рис. 3.6. Диаграмма размеров сжатых фрагментов псевдослучайной последовательности W=70.
3.2.4 Описание схемы проведения эксперимента
После того как был определен размер окна ![]()
![]() , а также обоснована целесообразность использования кода Хаффмана вместо архиваторов, определим эффективность нового метода экспериментально. В качестве критерия эффективности будем использовать количество ложных срабатываний алгоритма на пустых и заполненных контейнерах. Здесь необходимо различать два вида ошибок:
, а также обоснована целесообразность использования кода Хаффмана вместо архиваторов, определим эффективность нового метода экспериментально. В качестве критерия эффективности будем использовать количество ложных срабатываний алгоритма на пустых и заполненных контейнерах. Здесь необходимо различать два вида ошибок:
- ошибка I рода – ситуация, при которой пустой контейнер признается заполненным;
- ошибка II рода – ситуация, при которой заполненный контейнер признается пустым.
Для эксперимента была сформирована выборка из 1000 файлов[13]
формата PE (программ). Рассмотрим результаты работы метода, представленные в табл. 3.3.
Таблица 3.3. Эффективность работы метода стегоанализа.
| Род ошибки | Значение ошибки, % |
| I рода | 0.0 |
| II рода | 0.1 |
Мы видим, что предложенный метод эффективно обнаруживает факт наличия секретного сообщения. Основным достоинством разработанной схемы анализа следует считать отсутствие необходимости дизассемблирования.
Далее, будем постепенно заполнять контейнер на различное количество байт и анализировать результаты работы метода. На рис 3.7 представлена зависимость количества правильных определений от размера внедрения.
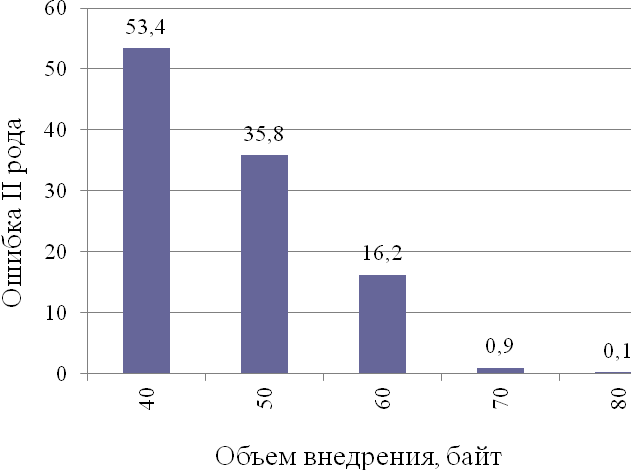
Рис. 3.7. Результаты работы метода при различных объемах внедрения
Ранее отмечалось, что наш метод рассчитан на работу с контейнером, заполненным на 80 байт. Если контейнер заполнен менее чем на 70 байт,
то ошибка II рода достаточно велика, что делает затруднительным практическое применение метода. Ошибка I рода отсутствует.
Причина столь высокой ошибки кроется в разнородности анализируемых данных и была описана в разделе 3.2.1. Однако
уже при заполнении контейнера на 70 байт и более, метод стегоанализа достаточно эффективно обнаруживает факт внедрения секретного сообщения.
3.3 Описание подхода повышения устойчивости метода внедрения информации в исполняемый файл
3.3.1 Описание схемы передачи секретного сообщения
В предыдущем разделе главы мы рассматривали исходный метод внедрения информации в исполняемые файлы [32]. Было установлено,
что упомянутый метод имеет существенный недостаток – различие статистических свойств кода программы и передаваемого секретного сообщения. Это различие свойств может быть использовано
для стегоанализа. Очевидно, что если секретное сообщение перед внедрением будет закодировано так, что распределение вероятностей будет такое же, как у кода программы, то атаки подобного рода станут неэффективными. В данном разделе главы предлагается использовать оптимальный код Хаффмана для предварительного кодирования зашифрованного сообщения перед внедрением. Рассмотрим пример, представленный на рис. 3.8.
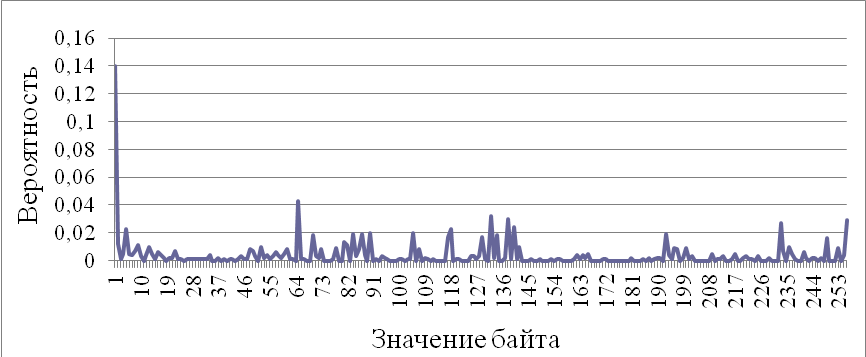
Рис. 3.8. Распределение вероятностей байт инструкций программы
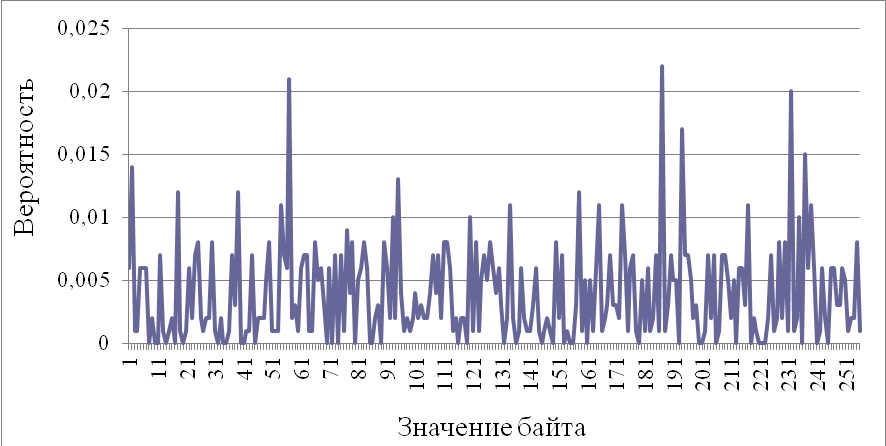
Рис. 3.9. Распределение вероятностей байт случайной последовательности до кодирования
Мы видим, что распределения, представленные на рис. 3.8 и 3.9, существенно отличаются, что с легкостью может быть выявлено
и использовано для стегоанализа. Ниже, на рис. 3.10, представлено распределение вероятностей байт случайной последовательности после кодирования.
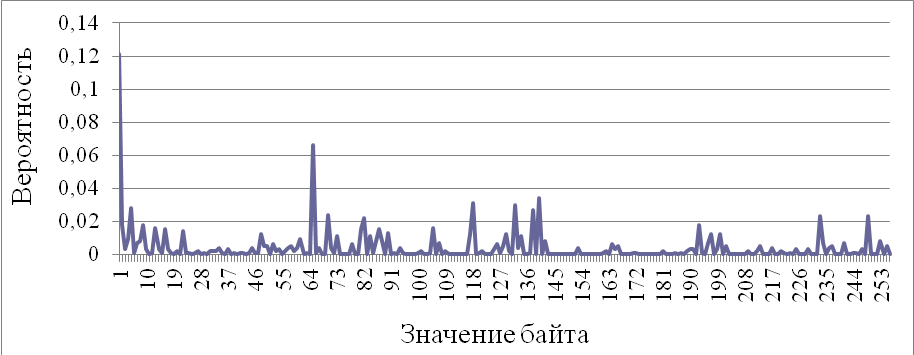
Рис. 3.10. Распределение вероятностей байт случайной последовательности после кодирования
Очевидно, что после применения предлагаемого подхода, распределения вероятностей байт, представленные на рис. 3.8 и 3.10 практически совпадают. Таким образом, может быть повышена устойчивость
к обнаружению исходного метода внедрения секретного сообщения [32].
Рассмотрим улучшенную схему передачи секретного сообщения
в общем виде, представленную на рис. 3.11.

Рис. 3.11. Модифицированная схема передачи секретного сообщения
Таким образом, предложенная схема отличается от исходной наличием этапов кодирования и декодирования сообщения.
Для передачи секретного сообщения Бобу, Алиса совершает следующие шаги:
Шаг 1. Шифрует исходное сообщение, используя секретный ключ;
Шаг 2. Кодирует зашифрованное сообщение, подавая его на вход декодеру Хаффмана;
Шаг 3. Внедряет полученное сообщение в секцию кода программы;
Шаг 4. Передает файл по открытому каналу связи;
Затем Боб совершает следующие шаги:
Шаг 5. Принимает файл от Алисы;
Шаг 6. Извлекает сообщение из секции кода программы;
Шаг 7. Декодирует сообщение, подавая его на вход кодеру Хаффмана;
Шаг 8. Расшифровывает сообщение, используя секретный ключ.
Таким образом, Боб получает от Алисы исходное сообщение. Участники обмена сообщениями заранее договариваются об используемом при шифровании секретном ключе. На шаге 6 Бобу необходимо знание начальной позиции в файле внедренного сообщения. Об этом также следует договориться заранее. Для шагов 2 и 7 (кодирования / декодирования) используется дерево Хаффмана, для построения которого требуются оценки вероятностей появления символов в окне. Процесс декодирования происходит аналогично.
3.3.2 Описание способа получения распределения вероятностей байт
Как уже отмечалось, для построения дерева Хаффмана требуется распределение вероятностей байт. В данной разделе главы рассматривается два способа получения такого распределения, которые используется на этапе кодирования / декодирования передаваемого сообщения:
- распределение считается в передаваемом пустом контейнере;
- выбирается единственное (особое) распределение, которое используется во всех случаях обмена сообщениями.
Рассмотрим первый способ. На шаге 2 Алисе необходимо знать распределение вероятностей байт пустого контейнера. Так как изначально Алиса имеет пустой контейнер, то она без труда сможет его получить.
На шаге 7 Бобу также нужно знать распределение вероятностей байт пустого контейнера. Боб получает уже заполненный контейнер, но так как известна начальная позиция встроенного сообщения, то он не будет учитывать байты внедренного сообщения при получении этого распределения. Таким образом, Алиса и Боб могут получить распределение, необходимое на этапах кодирования и декодирования сообщения.
Проверим эффективность предлагаемого подхода экспериментально. Будем осуществлять внедрение закодированного секретного сообщения,
и применять стеготест, описанный разделе 3.2. Для эксперимента была сформирована выборка из 1000 исполняемых файлов. Далее, используя вышеописанную схему, заполним контейнеры сообщениями. На этапе предварительного кодирования будем получать распределение вероятностей байт, анализируя секцию кода программы (полностью[14] ). После заполнения контейнеров и применения разработанного стеготеста получим результат, приведенный в табл. 3.4.
Таблица 3.4. Результаты применения стеготеста при использовании распределения вероятностей байт всей секции кода.
| Количество файлов | Обнаружено, % |
| 1000 | 6.6 |
Как видно из табл. 3.4, в 66 контейнерах из 1000 сообщение было обнаружено несмотря на предварительное кодирование. Можно утверждать, что распределение вероятностей обнаруженных стеготестом контейнеров было близко («с точки зрения» стеготеста) к случайному. При изучении структуры исполняемых файлов было обнаружено, что секция кода исполняемого файла может содержать не только набор двоичных инструкций, но и некоторый набор данных, например: таблицы адресов импорта. Обычно для таблицы адресов импорта используется дополнительная секция (например, для компиляторов фирмы Borland такая секция называется.idata). Но компиляторы сторонних производителей могут размещать ее в кодовой секции и, как правило, она размещается в конце секции. Строго говоря, формат PE допускает размещение таблицы импорта
в начале, середине и конце секции кода. Данные, расположенные в этой таблице, могут существенно влиять на получаемое распределение.
На рис. 3.12 и 3.13 показаны распределения средних вероятностей первой тысячи байт секции кода и последней, взятых из 1000 файлов.
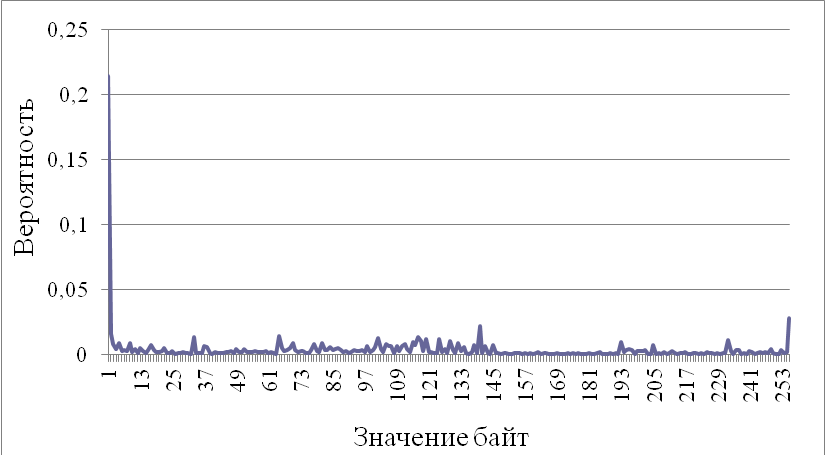
Рис. 3.12. Распределение средних вероятностей первой тысячи байт секции кода
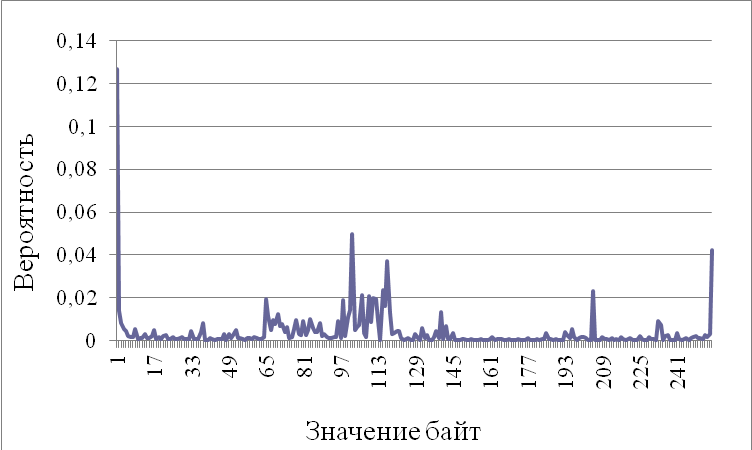
Рис. 3.13. Распределение средних вероятностей последней тысячи байт секции кода
Из графиков видно, что распределения первых и последних байт секции кода действительно отличаются. Таким образом, следует получать распределение вероятностей, анализируя не всю секцию, а только какую-то ее часть. Далее, будет рассмотрено, какая из частей секции должна анализироваться.
Рассмотрим результаты работы стеготеста, описанного в разделе 3.2, при использовании распределения вероятностей ![]()
![]() первых байт секции кода, представленных в табл. 3.5.
первых байт секции кода, представленных в табл. 3.5.
Таблица 3.5. Результаты стеготеста при использовании распределения вероятностей первых N байт секции
| Анализируемая часть N, байт | 80 | 300 | 500 | 1000 | 2000 | 3000 | 4000 | 5000 |
| Обнаружено, % | 0.0 | 0.2 | 0.1 | 0.6 | 1.5 | 2.7 | 2.0 | 3.0 |
Как мы уже выяснили, распределения вероятностей первых
и последних байт секции кода различаются. Теперь будем использовать
для кодирования распределение вероятностей ![]()
![]() последних байт.
последних байт.
Таблица 3.6. Результаты стеготеста при использовании распределения вероятностей байт последних N байт секции
| Анализируемая часть N, байт | 80 | 300 | 500 | 1000 | 2000 | 3000 | 4000 | 5000 |
| Обнаружено, % | 0.0 | 0.1 | 0.2 | 0.8 | 0.8 | 1.2 | 1.7 | 1.8 |
Итак, из табл. 3.5 и 3.6 мы видим, что для получения распределения лучше всего анализировать 80 первых или 80 последних байт секции кода.
Рассмотрим второй способ получения распределения вероятностей байт. При получении особого распределения следует учитывать
два требования:
- распределение является «типичным» для большинства файлов (очевидно, что любое нетипичное распределение может вызывать подозрение);
- распределение позволяет успешно проходить стеготест.
Для получения распределения, наиболее «типичного» для всех файлов, были проанализированы 1000 файлов. Для каждого из них были получены распределения вероятностей первых 1000 байт. Далее, было выбрано одно распределение, наиболее близкое ко всем остальным. Для этого составлялась матрица, элементами которой являются расстояния между распределениями. Под расстоянием понимается расстояние Кульбака Лейблера:
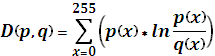
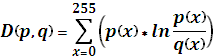 (1)
(1)
На рис. 3.14 изображена матрица, содержащая расстояния между двумя распределениями. Для того чтобы выбрать искомое распределение, суммировались элементы строк матрицы (как показано на рис. 3.14)
и выбиралось то распределение, которое давало минимальную сумму
по соответствующей строке матрицы.
| № | 1 | 2 | … | 1000 | Сумма |
| 1 | 1 | 10 | … | 31 | 1+10+…+31 |
| 2 | 10 | 1 | … | 25 | 10+1+…+25 |
| … | … | … | … | … | … |
Рис. 3.14. Матрица расстояний Кульбака-Лейблера
Таким образом, было получено следующее распределение, представленное на рис. 3.15.
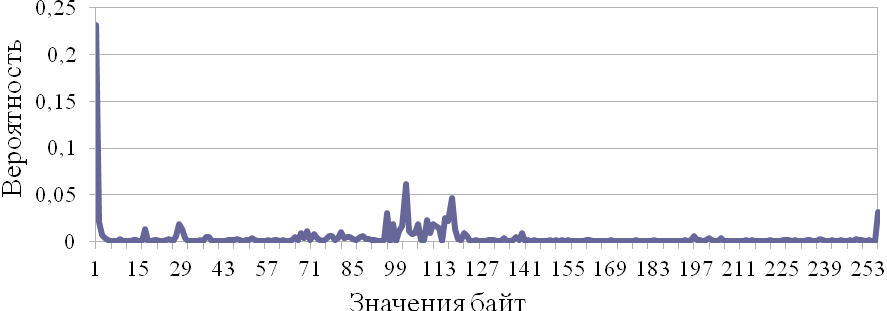
Рис. 3.15. Выбранное распределение вероятностей байт
Будем использовать при кодировании полученное (особое) распределение. Рассмотрим результаты стеготеста, представленные
в табл. 3.7.
Таблица 3.7. Результаты стеготеста при использовании особого распределения вероятностей байт
| Число заполненных контейнеров | Обнаружено, % |
| 1000 | 0 |
Результаты стеготеста показывают, что при данном способе выбора распределения вероятностей стеготест, предложенный в разделе
3.2, не обнаруживает ни один заполненный контейнер.
3.3.3 Заключение
Целью данной работы была модификация существующего метода внедрения информации в исполняемый файл. Было предложено перед внедрением сообщения в контейнер предварительно его кодировать. Тогда, распределение вероятностей байт внедряемого сообщения будет неотличимо от распределения кода программы, что делает стеготест, предложенный
в разделе 3.2, неэффективным. Было установлено, что на этапе кодирования
и декодирования сообщения для построения дерева Хаффмана следует использовать одно из следующих распределений вероятностей:
- распределение вероятностей первых 80 байт секции кода;
- распределение вероятностей последних 80 байт секции кода;
- распределение вероятностей, показанное на рис. 3.15[15].
Как уже было упомянуто, некоторые компиляторы размещают таблицу импорта в конце секции кода. Очевидно, что наличие ненулевых байт после таблицы может вызывать подозрение. Поскольку задача перемещения таблицы импорта после внедренного сообщения достаточно трудоемкая
и требует дизассемблирования, производимого в полуавтоматическом режиме (с участием человека), то рекомендуется не использовать такие контейнеры. Для передачи секретного сообщения лучше подбирать контейнеры, у которых таблица располагается в отдельной секции, например, как у представленного на рис. 3.16 файла.
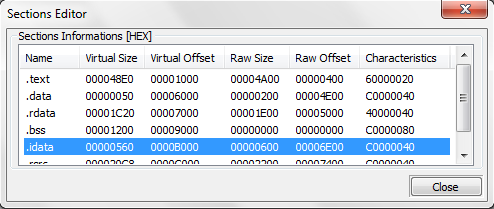
Рис. 3.16. Набор секций исполняемого файла bzip2.exe
Выводы
В данной главе была продемонстрирована нестойкость метода внедрения информации в исполняемые файлы формата Portable Executable, предложенного в статье [32]. В ходе работы построен новый эффективный метод стегоанализа, определяющий наличие факта внедрения скрытого сообщения размером 80 байт. Преимущество предложенной схемы стегоанализа заключается в том, что отсутствует необходимость
в трудоемком дизассемблировании. Также в этой главе, была предложена модификация исходной схемы внедрения информации, устойчивая к разработанному стеготесту.
Глава 4. Система внедрения цифровых водяных знаков в исходные коды программ
4.1 Введение
Построение систем цифровых водяных знаков является одним
из направлений стеганографии, к целям которого относят сокрытие данных
в цифровых средах или файлах таким образом, чтобы внедренный знак было бы трудно удалить или обнаружить. В отличие от классической задачи стеганографии, то есть проблемы сокрытия факта передачи данных, обычно не требуется скрыть наличие водяного знака в большинстве приложений. Считается, что можно заранее предугадать содержится ли водяной знак
или нет.
Одно из применений цифровых водяных знаков – это защита авторского права. Предположим, что вы создали программный продукт
и внедрили него водяной знак “NECHTA”. После некоторого времени
вы находите компанию, продающую этот же продукт как свой собственный, возможно с измененным названием или метаданными во внутренних файлах. Но если водяной знак устойчив, то есть он противостоит удалению
или модификации, то будет возможно извлечь слово “NECHTA” и доказать авторство в суде. Вероятность того, что водяной знак “NECHTA” возник
в файлах программы случайно, ничтожна мала.
Другое, более перспективное применение – защита от нелегального копирования. Идея сводится к следующему: автор внедряет в каждую продаваемую копию программы уникальный водяной знак, который позволил бы отслеживать пользователя, производящего незаконные копии. Проблема здесь возникает, когда два или больше пользователя создают коалицию. Они могут сравнить имеющиеся копии программ и найти
все различия с целью определения местоположения водяного знака. Знание этих местоположений может помочь им изменять водяной знак таким образом, чтобы создать копию, по которой не может быть прослежен ни один пользователь из коалиции. Для предотвращения подобной возможности существуют так называемые коды снятия отпечатков пальцев, которые используются как водяные знаки. Специальная конструкция и избыточность таких кодов гарантируют, что никакая коалиция размера менее
чем некоторое предопределенное значение не может создать непрослеживаемый водяной знак. Одной из проблем в схеме создания водяного знака состоит в обеспечении достаточного участка памяти
для размещения длинных кодов снятия отпечатков пальцев.
Согласно предложенной в работе [35] классификации, водяные знаки могут быть разделены на две категории:
- статические – добавляются к коду или данным программы на этапе создания;
- динамические – представляют собой структуру данных, процесс построения которой осуществляется во время выполнения программы.
Существует другая классификация, представленная в статье [36]. Здесь, происходит разделение типов водяных знаков по назначению.
- Авторская метка – предназначена для подтверждения подлинности программы. Такая метка должна быть доступна для чтения конечному пользователю. Водяной знак такого типа предназначен
для противодействия некоторым вредоносным программам, выступающим под видом другого известного приложения; - Цифровой отпечаток пальцев – идентифицируют канал поставки программного продукта и конечного пользователя. Отпечаток предназначен для отслеживания исходного источника нелицензионных копий. Как правило, водяной знак такого типа должен быть невидим для третьих лиц и устойчивым к удалению или модификации;
- Проверяющая метка – гарантирует отсутствие модификаций
в программе. Должна быть видима конечному пользователю; - Лицензионная метка – используется для аутентификации программного обеспечения. Должна быть невидимой и «хрупкой»[16].
Некоторые типы водяных знаков используют цифровую подпись, гарантирующую, что любое изменение части программы повлечет искажение подписи. Подробнее об этом рассматривается в работе [37].
4.2 Обзор существующих систем цифровых водяных знаков
Поскольку мы говорим о водяных знаках в программах, то следует отметить, что внедрение данных в исполняемые файлы имеет свою собственную специфику. Например, внедрение не может быть осуществлено прямой модификацией некоторых бит исполняемых файлов, потому
что любая такая модификация, с высокой долей вероятности, уничтожит алгоритм работы программы. Внедрение должно быть сделано таким путем, который гарантирует правильное функционирование программы. Проблема водяных знаков в программных была заявлена и рассматривалась в ряде работ [38-44].
Существует два основных подхода. Первый предлагает использование специальных дополнительных функций, которые добавляются к коду программы, [39], [41], [42]. Код дополнительных функций содержит требуемый водяной знак, например, в виде констант, использующихся
в различных вычислениях. Эти добавленные функции не должны выглядеть как “мертвый код” (код, который никогда не будет выполнен) потому,
что иначе они могут быть легко удалены алгоритмом устранения мертвого кода. То есть они должны быть интегрированы в программу и вызваны
в течение выполнения программы. Преимущество этого подхода состоит
в фактически неограниченной длине водяного знака. Однако недостаток – потенциальная деградация алгоритма работы программы. Другим недостатком является уязвимость к нападениям, которые находят некоторые известные образцы функциональных конструкции водяного знака и пути обращения к нему.
Второй подход не использует добавление явных кодов, а скорее задействует некоторую незначительную избыточность в программных файлах, которая позволяет внедрять водяной знак. Подобный подход используется в работах [38], [40], [43-47], чтобы скрыть данные непосредственно в исполняемых файлах. Общая особенность этих методов состоит в нахождении некоторого набора эквивалентных способов генерации исполняемого файла и сокрытие данных через выбор одного из них. Методы генерации кода зависят от компилятора и, в частности, его методов выбора типа команды, планирования инструкций, размещения текста программы, выделения регистров, расстановке переменных и расстановке адресов функций в таблицах импорта. Следует обратить внимание на то,
что некоторые модификации кода могут быть применены к уже готовому исполняемому файлу, в то время как другие только во время компиляции
и, поэтому, требуются специально разработанный компилятор. Мы кратко проиллюстрируем сущность каждого метода. Примеры во всей главе будут даваться на C\C++ и языках трансляции процессора ARM [17].
Метод выбора команды состоит в нахождении различных последовательностей кода, которые производят то же самое вычисление. Например, инструкция d = d + 1 могла быть выполнена путем добавления
1 или, вычитанием -1 от d. Инструкция d = d * 2 могла быть выполнена добавлением d к d или левым битовым сдвигом d. Эти варианты могут быть закодированы как 0 и 1 соответственно. Выбор одного из них зависит
от внедряемого бита данных. Следует обратить внимание на то,
что возможность эффективного поиска альтернативной команды зависит
от типа процессора и ограничены в RISC типа ARM. В ARM удвоение переменной может быть сделано следующим образом:
add rd, rd, #0
или
mov rd, rd, asl #1,
где оба варианта одинаковы по длине байт и времени выполнения. Следует учесть, что непосредственное вычитание отрицательного числа невозможно.
Метод планирования инструкций находит блоки с независимыми командами процессора. Все перестановки независимых команд упорядочивают лексикографически и рассматриваются как эквивалентные. Двоичное представление номера перестановки команд есть внедренное сообщение. Например, в блоке
mov r3, r4
add r0, r4, #1
две операции являются независимыми следовательно, возможна эквивалентная последовательность:
add r0, r4, #1
mov r3, r4
Таким образом можно закодировать один бит информации.
Метод размещения кода программы основан на информации, полученной в ходе анализа ряда программ. Любой машинный код может быть представлен как набор блоков с последовательно выполняющимися командами и отделенными инструкциями вида “go to” (переходы).
Эти блоки кода могут быть помещены в память (в содержимое исполняемого файла) в различном порядке. Аналогично, внедренные данные – это двоичное представление номера перестановки блоков кода.
Метод выделения регистров имеет дело с назначением регистра процессора под размещение некоторой переменной. Если в предыдущем примере переменная d может быть помещена в регистр и компилятор имеет несколько свободных регистров, скажем r3 и r4, то дополнительный
бит может быть внедрен, путем назначения d = r3 или d = r4.
Для переменных, которые не могут быть помещены в регистр, может использоваться различный порядок их расположения в памяти. Различные комбинации назначения регистров или расположения переменных в памяти дают возможность скрывать данные.
В работе [50] показана возможность воспользоваться преимуществом технологии динамического связывания, которая преобладает в современном программировании. Различные перестановки адресов начала функций
в таблицах импорта\экспорта и поддерживающих структурах могут быть использованы для скрытия данных.
Все рассматриваемые методы могут быть объединены вместе, чтобы увеличить общий объем внедрения информации. Однако существует проблема: внедрение данных не всегда устойчиво. Это, прежде всего, относится к внедрению, сделанному непосредственно в готовую исполняемую программу. Та же самая программа, которая внедряет данные, может использоваться для стирания или изменения водяного знака. Именно поэтому в данной работе особое внимание уделяется методам внедрения, применяемых к исходным текстам программ, после компиляции которых найти или исказить водяной знак значительно труднее.
4.3 Описание предложенной схемы внедрения водяных знаков
4.3.1 Описание предлагаемой схемы
В данном разделе будет предложена схема нанесения водяных знаков в тексты программ на языке C\C++.
Разработанная схема предполагает создание автономной программы, запускающейся перед компиляцией программы, которая используется для того, чтобы внедрить водяной знак в исходные файлы C\C++.
В реализованной версии программы внедрения водяных знаков, производится упорядочивание операции присваивания и упорядочивание локальных переменных.
Рассмотрим пример работы предлагаемой схемы. Пусть дана следующая функция:
int f (int x)
{
int a, b;
a = x + 1;
b = x - 1;
return a + 2 * b;
}
Вычислительная часть функции, откомпилированая с GCC:
ldr r3, [fp, #-16]
add r3, r3, #1
str r3, [fp, #-20]
ldr r3, [fp, #-16]
sub r3, r3, #1
str r3, [fp, #-24]
ldr r3, [fp, #-24]
mov r2, r3, asl #1
ldr r3, [fp, #-20]
add r3, r2, r3
mov r0, r3
где распределение памяти для переменных соответствует порядку
их объявления:
x = [fp, #-16], a = [fp, #-20], b = [fp, #-24].
Согласно предложенному подходу мы можем внедрить два бита водяного знака в эту функцию путем выбора порядка объявления переменных и порядка следования независимых инструкций:
0 int a, b; 1 int b, a;
0 a = x + 1; 1 b = x – 1;
b = x – 1; a = x + 1;
Так, исходная функция, в которой объявления локальных переменных и инструкции упорядочены лексикографически, соответствует водяному знаку “00”. Чтобы внедрить водяной знак “11”, мы перезаписываем функцию в виде:
int f (int x)
{
int b, a;
b = x - 1;
a = x + 1;
return a + 2 * b;
}
Вычислительная часть функции, откомпилированая с GCC:
ldr r3, [fp, #-16]
sub r3, r3, #1
str r3, [fp, #-20]
ldr r3, [fp, #-16]
add r3, r3, #1
str r3, [fp, #-24]
ldr r3, [fp, #-20]
mov r2, r3, asl #1
add r3, r2, r3
mov r0, r3
где распределение памяти для переменных соответствует порядку
их объявления:
x = [fp, #-16], a = [fp, #-24], b = [fp, #-20].
Рассмотрим устойчивость данного метода к искажению водяного знака. Предположим, что мы имеем две исполняемых программы или объектных модуля, которые содержат нашу функцию с водяными знаками “00” и “11” соответственно. В табл. 4.1 приведено сравнение двух объектных файлов
с помощью команды unix shell “cmp –l”. Мы обнаруживаем 4 различия.
Таблица 4.1. Различия объектных файлов до и после внедрения водяного знака
| Адреса | Байты файлов | |
| Без водяного зн. | С водяным зн. | |
| 79 | 203 | 103 |
| 91 | 103 | 203 |
| 97 | 30 | 24 |
| 105 | 24 | 30 |