

Обработка информации на основе спектрального импульсного преобразования для сравнения и классификации дискретных данных, циркулирующих в промышленном предприятии
- На правах рукописи
- Тверетин Алексей Александрович
ОБРАБОТКА ИНФОРМАЦИИ НА ОСНОВЕ СПЕКТРАЛЬНОГО
ИМПУЛЬСНОГО ПРЕОБРАЗОВАНИЯ ДЛЯ СРАВНЕНИЯ И
КЛАССИФИКАЦИИ ДИСКРЕТНЫХ ДАННЫХ, ЦИРКУЛИРУЮЩИХ В ПРОМЫШЛЕННОМ ПРЕДПРИЯТИИ
Специальность: 05.13.01. – Системный анализ, управление и обработка
информации (промышленность)
АВТОРЕФЕРАТ
диссертации на соискание ученой степени
кандидата технических наук
Самара – 2010
- Работа выполнена на кафедре «Электронные системы и информационная безопасность» Государственного образовательного учреждения высшего профессионального образования «Самарский государственный технический университет»
- Научный руководитель кандидат технических наук, доцент,
- Буканов Федор Федорович
- Официальные оппоненты доктор технических наук, профессор
- Батищев Виталий Иванович
- кандидат технических наук, доцент,
- Крыжановский Анатолий Владиславович
- Ведущая организация ЗАО «НПЦ Инфотранс»,
- г. Самара.
- Защита состоится «28» декабря 2010 г., в 11 час. 00 мин. на заседании диссертационного совета Д 212.217.03 ГОУ ВПО Самарский государственный технический университет (СамГТУ) по адресу: г. Самара, ул. Первомайская, 18, 1 корпус, ауд. №4 (Учебный центр СамГТУ, Электрощит).
- С диссертацией можно ознакомиться в библиотеке Самарского государственного технического университета по адресу: г. Самара, ул. Первомайская, 18
- Отзывы по данной работе в двух экземплярах, заверенные печатью, просим направлять по адресу: 443100, г. Самара, Молодогвардейская ул. 244, СамГТУ, главный корпус, ученому секретарю диссертационного совета Д 212.217.03; факс: (846) 278-44-00; e-mail: [email protected]
- Автореферат разослан 26 ноября 2010 г.
- Ученый секретарь диссертационного
- совета Д 212.217.03 Губанов Н.Г.
ОБЩАЯ ХАРАКТЕРИСТИКА РАБОТЫ
Актуальность работы. В настоящее время продолжается вторичная автоматизация промышленных предприятий, которая заключается в интеграции применяемого программного обеспечения с целью получения единого хранилища данных, циркулирующих внутри предприятия. Помимо сложностей, связанных с разными платформами и программными средами, в которых функционируют различные средства автоматизации, существуют сложности, связанные с разнородностью структуры данных. В свете современной рыночной ситуации от оперативности работы и осведомленности управленческого персонала зависит порой эффективность работы всего предприятия.
Не смотря на то, что активно внедряемые системы ERP (enterprise resource planning, корпоративное планирование ресурсов), предназначенные для интеграции данных о функционировании предприятия, обладают богатыми возможностями, анализ оперативных данных о функционировании предприятия в них затруднен из-за реляционной модели данных.
Рутинной операцией при анализе данных является сравнительный ее анализ. Он сводится обычно к сравнению агрегированных суммовых показателей за период, обычно месяц, что не позволяет судить об изменении показателей внутри периода. Таким образом, сравнительный анализ, и в частности, идентификация по фактическим данным одного из запланированных сценариев развития событий, оказывается затруднительным, так как при схожих трендах математического ожидания показателей на определенном периоде, могут наблюдаться различные варианты распределения данного параметра внутри периода.
Другим важным видом анализа, является ретроспективный анализ изменения показателей, характеризующих определенные аспекты функционирования предприятия, когда требуется идентифицировать функциональный класс принадлежности вариаций показателя на данном интервале. Введение конечного количества классов, позволяет сильно облегчить анализ процессов на предприятии для управляющего персонала предприятия.
Вышеописанные задачи сводятся к классификации дискретных данных, а именно к классификации изменения того или иного показателя во времени на определенном интервале. Вообще говоря, задача классификации дискретных данных актуальна при контроле любых производственно-экономических показателей во времени характеризующих какой-либо процесс, описывающий состояние предприятия или отдельных его частей.
На данный момент широкое распространение получили системы интеллектуального анализа (data mining), которые решают задачи классификации, регрессии и ряд других задач. Эти программные средства на данный момент повсеместно применяются на практике для работы с используемыми на предприятиях СУБД (системами управления базами данных) и фактически не имеют альтернатив.
Широко распространенные и доступные системы интеллектуального анализа данных обычно содержат набор достаточно примитивных алгоритмов (метод ближайших соседей, метод наивного байеса и других), которые работают с небольшим количеством фиксированных признаков, что не позволяет решить поставленную задачу классификации, так как количество анализируемых признаков может быть большим. Кроме того, количество признаков может меняться в зависимости от характера данных. Также, ограничения на применение данных средств накладывает природа анализируемых данных, которая заключаются в присутствии небольших искажений последовательности и неопределенном положении начальной фазы.
Таким образом, актуальной задачей является разработка методов и алгоритмов, которые позволяют без увеличения затрат на более сложные аналитические средства, достигать решения таких сложных задач, как классификация и сравнение дискретных данных, используя стандартные и хорошо апробированные системы интеллектуального анализа данных.
Целью диссертационного исследования является разработка методов и алгоритмов обработки информации на основе сжатия дискретных данных, циркулирующих в промышленном предприятии, для их сравнения и классификации с использованием систем интеллектуального анализа данных.
В ходе достижения цели решались следующие задачи:
- анализ проблем, возникающих при исследовании дискретных данных, циркулирующих в промышленном предприятии с целью определения наиболее перспективных методов преобразования для облегчения их сравнения и классификации;
- разработка метода сжатия дискретных данных с помощью спектрального импульсного преобразования;
- разработка алгоритма сравнения дискретных данных;
- разработка алгоритма классификации дискретных данных с использованием сжатия и метода наивного байеса;
- оценка трудоемкости метода сжатия дискретных данных и его сравнение с широко используемыми методами;
- проведение численных экспериментов с целью изучения свойств разработанных алгоритмов;
- разработка программного обеспечения, реализующего разработанные методы и алгоритмы для решения задач сравнительного анализа бюджетов и ретроспективного анализа финансовых показателей предприятия.
Методы исследования базируются на комплексном применении системного анализа, теории реляционных баз данных, теории вероятностей, теории спектрального представления данных, методах интеллектуального анализа данных.
Научная новизна и значимость работы заключается в следующих полученных результатах:
- разработан метод сжатия дискретных данных на основе спектрального импульсного преобразования, который в отличие от других методов инвариантен к положению начальной фазы дискретной последовательности данных, и малочувствителен к незначительным изменениям данных;
- разработан алгоритм сравнения дискретных данных, который основан на анализе евклидова расстояния между значениями гармоник спектра, полученных в результате предварительного сжатия данных, и который в отличие от других алгоритмов позволяет сравнивать дискретные последовательности с неопределенным положением начальной фазы;
- разработан алгоритм классификации дискретных данных, использующий в качестве признаков значения гармоник спектра, полученного в результате предварительного сжатия данных, который за счет уменьшения признаков имеет меньшую трудоемкость в отличие от других алгоритмов, а так же позволяет проводить классификацию дискретных последовательностей с разным положением начальной фазы.
Практическую значимость работы составляют следующие положения:
- разработанный метод сжатия дискретных данных на основе спектрального импульсного преобразования, а также алгоритмы сравнения и классификации могут использоваться для построения информационно-аналитических систем на базе промышленных СУБД с использованием стандартной функциональности;
- разработан комплекс прикладных программ, автоматизирующий процесс сравнительного анализа бюджетов, а также ретроспективного анализа изменения финансовых коэффициентов;
- разработанные методы и алгоритмы могут служить основой для создания информационно-аналитических систем для анализа произвольных дискретных данных, характеризующих процессы, описывающие состояние предприятия.
Внедрение результатов работы. Разработанная информационно-аналитическая система, в части разработанных методов и алгоритмов внедрена в ЗАО «УР БО», ЗАО «Тюменский судостроительный завод», ООО «Парус-Самара», ООО «Системы управления бизнесом» и используются в практической деятельности, что подтверждено актами о внедрении.
Апробация работы. Основные результаты работы докладывались и обсуждались на всероссийских научно-технических конференциях «Наука. Технологии. Инновации» (г.Новосибирск, 2005г.), «Приоритетные направления развития науки, технологий и техники» (г.Москва, 2008 г.).
Публикации. Основное содержание диссертации изложено в 11 публикациях, в том числе в 2 статьях в журналах рекомендованных ВАК.
Структура и объем диссертации. Диссертация состоит из введения, четырех глав, заключения, списка литературы. Она изложена на 154 страницах, содержит 57 рисунков, 14 таблиц и библиографический список из 110 наименований.
На защиту выносятся следующие основные научные положения:
- метод сжатия дискретных данных на основе спектрального импульсного преобразования;
- алгоритм сравнения дискретных данных, основанный на анализе евклидова расстояния спектральных значений, полученных при предварительном сжатии;
- алгоритм классификации дискретных данных на основе спектрального импульсного преобразования и метода наивного байеса.
ОСНОВНОЕ СОДЕРЖАНИЕ РАБОТЫ
Введение содержит общую характеристику работы, определены цели и задачи исследования. Сформулированы научная новизна и практическая ценность, а также основные научные положения, выносимые на защиту. Приведены сведения о внедрении результатов, публикациях, структуре и объеме работы.
Первая глава посвящена проблеме представления и анализа дискретных данных. Проведено исследование проблем сравнения и классификации дискретных данных, циркулирующих в промышленном предприятии, сформулированы требования для решения этих проблем. Произведенные исследования позволили сделать вывод о необходимости совершенствования методов анализа дискретных данных, с возможностью реализации методов анализа на уровне применяемых в промышленности систем управления базами данных. Проведен анализ лингвистических, статистических методов анализа данных, а так же методов линейных преобразований данных. Приведены достоинства и недостатки данных методов.
Примером дискретных данных в системах общественных процессов, являются данные, характеризующие различные финансовые показатели и представляющие собой последовательность дельта-функций, показывающих значение того или иного показателя во времени. Различные варианты таких последовательностей можно наблюдать в ERP-системах, SFA (sales force automation systems, системы автоматизации продаж), SCM (supply chain management, системы управления цепями поставок), CRM (customer relationship management system, система управления взаимодействием с клиентами) и многих подобных им системах.
Исследование показало, что большинство методов анализа дискретных данных сформировались на основе решений задач, связанных с системами передачи данных и представляют такие данные в виде дискретных сигналов. Технически, методы преобразования и фильтрации таких данных реализованы в виде программно-аппаратных систем, которые обычно совмещают в себе устройства регистрации и обработки данных с помощью узкого набора алгоритмов. Данные систем более сложной организации принципиально не могут иметь такую структуру, так как непосредственно регистрация данных в таких системах возложена на человека.
Данные о процессах, протекающих в системах можно представить как сигнал ![]() . Причем, такой сигнал является случайным, то есть каждый отсчет
. Причем, такой сигнал является случайным, то есть каждый отсчет ![]() принимает некоторые значения с определенной вероятностью. Сигнал является данными о случайном процессе, и получаемая последовательность отсчетов будет зависеть от конкретной реализации случайного процесса. Реализация такого сигнала может быть записана как
принимает некоторые значения с определенной вероятностью. Сигнал является данными о случайном процессе, и получаемая последовательность отсчетов будет зависеть от конкретной реализации случайного процесса. Реализация такого сигнала может быть записана как ![]() , где
, где ![]() - амплитуда,
- амплитуда, ![]() - частота,
- частота, ![]() - случайная начальная фаза, кратная периоду дискретизации отсчетов. Нужно отметить, что использования времени
- случайная начальная фаза, кратная периоду дискретизации отсчетов. Нужно отметить, что использования времени ![]() весьма условно, и вместо него могут использоваться другие характеристики сигнала. Кроме того, такие сигналы являются финитными. Важным свойством сигналов является то, что сигнал изначально имеет цифровой характер, то есть он квантован по частоте и по уровню. Основной сложностью при анализе таких данных является характер этой зависимости. Условие эргодичности и стационарности сигналов в системах сложной организации обычно не соблюдается, то есть характеристики, полученные усреднением по ансамблю выборок и по времени не совпадают. Это связано с тем, что случайный характер имеют не только значения каждого отсчета
весьма условно, и вместо него могут использоваться другие характеристики сигнала. Кроме того, такие сигналы являются финитными. Важным свойством сигналов является то, что сигнал изначально имеет цифровой характер, то есть он квантован по частоте и по уровню. Основной сложностью при анализе таких данных является характер этой зависимости. Условие эргодичности и стационарности сигналов в системах сложной организации обычно не соблюдается, то есть характеристики, полученные усреднением по ансамблю выборок и по времени не совпадают. Это связано с тем, что случайный характер имеют не только значения каждого отсчета ![]() , но и его начальная фаза
, но и его начальная фаза ![]() , кроме того характер распределения шумовой составляющей не удается однозначно установить. На рисунке 1 такие данные изображены на примере разреза производственного бюджета затрат в суммовом выражении, который представлен двумя реализациями, плановой и фактической, с разной начальной фазой, при этом качественная характеристика реализаций одна и та же.
, кроме того характер распределения шумовой составляющей не удается однозначно установить. На рисунке 1 такие данные изображены на примере разреза производственного бюджета затрат в суммовом выражении, который представлен двумя реализациями, плановой и фактической, с разной начальной фазой, при этом качественная характеристика реализаций одна и та же.


В общем случае, бюджет предприятия можно изобразить в виде куба, изображенного на рисунке 2. Данный куб имеет несколько основных измерений, на пересечении которых извлекается целевое значение, представляющее собой ту или иную информацию о деятельности предприятия обычно в суммовом или количественном виде. Кроме того, основное измерение «Статья» может иметь несколько подизмерений для ее детализации.
Лавинообразное увеличение данных о процессах, протекающих в различных системах в последние десятилетия, привело к созданию систем управления базами данных (СУБД). Для автоматизации процесса бюджетирования (управления бюджетом) были разработаны специальные программные средства, входящие, как правило, в состав ERP-систем. Но, не смотря на автоматизацию части процессов, анализ бюджетов по-прежнему осложнен, главным образом из-за большого объема данных. На рисунке 3 изображен типичный


интерфейс подобного модуля.
Как видно из рисунка 3, в рамках реляционной модели сложно представить такой большой объем данных, особенно для их анализа. Типичной задачей при анализе бюджетов является сравнительный анализ, когда на основе фактических данных за период времени определяется наиболее похожая плановая версия, т.е. осуществляется решение задачи классификации без учителя. Данный вид анализа позволяет быстро оценить эффективность работы предприятия. Но из-за недостатков интерфейсного представления таких систем, данный вид анализа превращается в последовательность рутинных операций. Анализ осложняется тем, что для удобства, измерение «Время» укрупняется до месяцев и кварталов, но при этом у различных плановых измерений средние значения показателей могут быть близки. Очевидно, что задача может быть решена с помощью методов сравнения дискретных данных, которые позволят решать задачу в автоматическом режиме.
Другой важной задачей является ретроспективный анализ показателей, например некоторых финансовых коэффициентов, определенных разрезов бюджета или ключевых показателей эффективности, когда по определенной последовательности показателей требуется отнести ее к какому-либо классу на основе прошлых значений показателя. Классы могут определяться на основании значений других параметров, таким образом, можно отследить их взаимосвязь.
Несмотря на высокую техническую оснащенность современных СУБД, существующих уже четыре десятка лет, активное развитие систем анализа данных, происходит лишь в последнее десятилетие. Такие системы получили название систем интеллектуального анализа данных (data mining). Системы интеллектуального анализа данных решают такие задачи как классификация, регрессия, поиск ассоциативных правил и других. Данные системы состоят из набора прикладных средств фильтрации и представления данных и набора алгоритмов, который осуществляет непосредственно анализ данных. Однако современные системы интеллектуального анализа данных используют простые алгоритмы и методы, что осложняет их применение для анализа дискретных данных, главным образом из-за сложности работы с большим количеством признаков. Очевидно, что для использования алгоритмов классификации, в том числе в системах интеллектуального анализа данных, возникает задача уменьшения количества признаков. Поэтому первостепенной задачей является разработка метода обработки данных, который ввиду сжатия уменьшал бы количество признаков анализируемых данных и при этом обладал бы инвариантностью к сдвигам и небольшим изменениям сигнала. Кроме того, разрабатываемые методы и методики должны обладать малой трудоемкостью, что актуально при анализе большого объема данных в реальном времени, а так же иметь возможность работы с последовательностями качественных значений, что актуально при работе, например с ключевыми показателями эффективности.
Проведен обзор известных методов обработки данных для решения поставленной задачи. Результаты их сравнительного анализа представлены в таблице 1. Обзор показал, что все из них обладают определенными преимуществами и недостатками. Особенностью данных методов является то, что каждый из них решает узкий круг задач, но в целом они удачно дополняют друг друга. Недостатком является то, что перенос данных методов в другую область является труднодостижимым.
На основе произведенного анализа можно сделать вывод, что наиболее перспективным подходом являются спектральные методы преобразования, так как они хорошо апробированы на анализе сигналов и имеют простой математический аппарат, хорошо реализуемый программно.
Во второй главе разработан метод сжатия дискретных данных на основе спектрального импульсного преобразования, осуществляющий сжатие информации. Разработанный метод обладает свойством инвариантности к положению начальной фазы сигналов и малой чувствительностью к незначительным изменениям сигнала. На основе разработанного алгоритма предложен метод сравнения данных, который заключается в оценке евклидова расстояния между полученными в результате сжатия значениями спектра. Разработан алгоритм классификации данных использующий метод наивного байеса с предварительным сжатием информации.
Как известно, идея спектрального анализа сигналов сводится к их представлению в виде обобщенного ряда Фурье: ![]() , где
, где ![]() -
- ![]() - я
- я
Таблица 1 - Сравнительные характеристики методов преобразования
| Наименование | Достоинства | Недостатки | |
| Методы попарного выравнивания | Лингвистические | Высокая эффективность при выявлении связи между зашумленными сигналами | Высокая сложность программной реализации, высокая вычислительная трудоемкость. Сложность реализации для анализа количественных данных. |
| Методы нечетких дубликатов | Низкая сложность программной реализации, высокая эффективность при выявлении связи между зашумленными сигналами на примере естественных текстов | Сложность реализации для анализа числовых данных, жесткое ориентирование на естественные тексты. | |
| Метод поиска максимального правдоподобия | Статистические | Высокая эффективность, легкая интерпретация результатов | Сложность использования большого числа признаков а так же, ориентация на качественные признаки |
| Метод весовой матрицы | Низкая вычислительная сложность, высокая эффективность при выявлении связи между зашумленными сигналами | Сложность реализации для анализа числовых данных, возрастающая сложность при возрастании количества элементов алфавита, низкая чувствительность при разной размерности данных | |
| Метод марковских цепей | Высокая эффективность при выявлении связи между зашумленными сигналами, низкая вычислительная сложность | Сложность интерпретации при анализе числовых данных, необходимость наличия большого количества данных разных реализаций | |
| Метод дискретного преобразования Фурье | Спектральные | Простота программной реализации, легкость интерпретации при анализе числовых данных | Большая вычислительная сложность, большое количество выходных признаков |
| Метод быстрого преобразования Фурье | Низкая вычислительная сложность, простота программной реализации, легкость интерпретации при анализе числовых данных | Большое количество выходных признаков, при уменьшении которых теряется информация о резких всплесках сигнала | |
| Метод дискретного косинус-преобразования | Простота реализации, легкость интерпретации при анализе числовых данных | Большая вычислительная сложность из-за вычисления тригонометрических функций | |
| Метод преобразования Уолша | Низкая вычислительная сложность | Зависимость от начальной фазы сигнала | |
| Метод вейвлет – преобразования | Простота программной реализации, легкость интерпретации при анализе числовых данных | Большая вычислительная сложность | |
базисная функция, ![]() - весовой коэффициент,
- весовой коэффициент, ![]() - число членов ряда. Базис
- число членов ряда. Базис ![]() является фиксированной системой функций. Простейшая система базисных функций – прямоугольные импульсы единичной амплитуды длительностью
является фиксированной системой функций. Простейшая система базисных функций – прямоугольные импульсы единичной амплитуды длительностью ![]() , где
, где ![]() - число импульсов. Но по системе прямоугольных импульсов можно разложить лишь сигнал ступенчатой формы. Чтобы привести данную систему к полной, для произвольного непрерывного сигнала необходимо перейти к пределу при
- число импульсов. Но по системе прямоугольных импульсов можно разложить лишь сигнал ступенчатой формы. Чтобы привести данную систему к полной, для произвольного непрерывного сигнала необходимо перейти к пределу при ![]() . При этом, можно перейти от прямоугольных импульсов к единичным импульсам
. При этом, можно перейти от прямоугольных импульсов к единичным импульсам ![]() , положение которых определяется сдвигом во времени на величину
, положение которых определяется сдвигом во времени на величину ![]() . Система единичных импульсов
. Система единичных импульсов ![]() является полной ортогональной системой, на любом интервале времени. Кроме того, из-за бесконечно малой ширины единичного импульса
является полной ортогональной системой, на любом интервале времени. Кроме того, из-за бесконечно малой ширины единичного импульса ![]() , он хорошо подходит для локализации минимальных изменений сигнала. При использовании базисных функций
, он хорошо подходит для локализации минимальных изменений сигнала. При использовании базисных функций ![]() , где
, где ![]() - номер импульса, спектр сигнала можно определить как:
- номер импульса, спектр сигнала можно определить как:  . Полученный спектр зависит только от сдвига одиночного импульса и частотная информация отсутствует.
. Полученный спектр зависит только от сдвига одиночного импульса и частотная информация отсутствует.
С другой стороны, в теории спектрального анализа используется комплексная экспоненциальная система базисных функций:  , где
, где ![]() ;
; ![]() - номер базисной функции;
- номер базисной функции; ![]() - угловая частота
- угловая частота ![]() . Данная система функций также является полной ортогональной системой на интервале
. Данная система функций также является полной ортогональной системой на интервале ![]() . Если рассматривать сигнал как периодический и несинусоидальный и отвечающий условиям Дирихле, то его можно представить рядом Фурье как суперпозицию конечного или бесконечного числа базисных экспоненциальных функций. Тогда спектральный состав разложения характеризуется дискретной спектральной функцией:
. Если рассматривать сигнал как периодический и несинусоидальный и отвечающий условиям Дирихле, то его можно представить рядом Фурье как суперпозицию конечного или бесконечного числа базисных экспоненциальных функций. Тогда спектральный состав разложения характеризуется дискретной спектральной функцией:  . Если
. Если ![]() , то
, то ![]() , спектр можно записать как:
, спектр можно записать как:  . Для дискретных сигналов данное соотношение преобразуется в
. Для дискретных сигналов данное соотношение преобразуется в ![]() , где
, где ![]() . Важным для экспоненциальной системы базисных функций является свойство инвариантности к сдвигам сигнала. Переход в частотную область дает множество преимуществ для анализа сигналов. Но данный подход имеет ряд недостатков, а именно отсутствие в явном виде структурной информации о сигнале. Из-за интегральности взаимной энергии между сигналом
. Важным для экспоненциальной системы базисных функций является свойство инвариантности к сдвигам сигнала. Переход в частотную область дает множество преимуществ для анализа сигналов. Но данный подход имеет ряд недостатков, а именно отсутствие в явном виде структурной информации о сигнале. Из-за интегральности взаимной энергии между сигналом ![]() и k-й базисной функцией значения соответствующих взаимных энергий могут быть одинаковыми для сигналов различной формы. То есть, при использовании экспоненциального базиса отсутствует информация о локальных особенностях сигнала, например о резких всплесках. Следует отметить также, что преобразования в экспоненциальном базисе обладают высокой трудоемкостью вычислений. Эта проблема приобретает особую актуальность при обработке больших массивов цифровых данных.
и k-й базисной функцией значения соответствующих взаимных энергий могут быть одинаковыми для сигналов различной формы. То есть, при использовании экспоненциального базиса отсутствует информация о локальных особенностях сигнала, например о резких всплесках. Следует отметить также, что преобразования в экспоненциальном базисе обладают высокой трудоемкостью вычислений. Эта проблема приобретает особую актуальность при обработке больших массивов цифровых данных.
Для достижения компромисса между двумя подходами предложено использовать базисную комплексную систему импульсных функций, которая определяется на множестве ![]() , и имеет вид
, и имеет вид ![]() , где
, где ![]() - номер гармоники анализируемого сигнала. Функции
- номер гармоники анализируемого сигнала. Функции ![]() и
и ![]() определяются как:
определяются как: ![]() для нулевой гармоники
для нулевой гармоники ![]() . В случае, если
. В случае, если ![]() и изменяется от 0 до
и изменяется от 0 до ![]() с шагом
с шагом ![]() , функции можно записать как:
, функции можно записать как: ![]() ,
, ![]() , где
, где ![]() .
.
При практической реализации метода, предложено вместо вычисления тригонометрических функций синуса и косинуса использовать матрицу заранее вычисленных значений. Для выражения ![]() такая матрица записывается как:
такая матрица записывается как:
 ,
,
Для выражения ![]() матрица записывается как:
матрица записывается как:
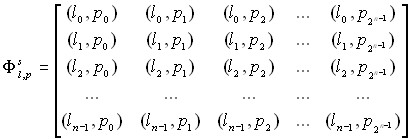 .
.
Таким образом, импульсные функции запишутся как: ![]() ,
, ![]() .
.
Реализация данного подхода позволяет отказаться от вычисления значений тригонометрических функций, что значительно ускоряет процедуру вычисления. Для каждой гармоники множество ![]() делится на
делится на ![]() интервалов, в каждом из которых происходит сдвиг импульсных функций на
интервалов, в каждом из которых происходит сдвиг импульсных функций на ![]() подинтервалов. Сдвигаемые импульсные функции формируются на основе вспомогательных функций
подинтервалов. Сдвигаемые импульсные функции формируются на основе вспомогательных функций ![]() и
и ![]() , их можно записать как:
, их можно записать как: ![]() и
и ![]() . Количество сдвигов можно определить как
. Количество сдвигов можно определить как
![]() , где
, где ![]() - позиция первого подинтервала, с которого начинается сдвиг.
- позиция первого подинтервала, с которого начинается сдвиг.
Формирование обобщенного амплитудно-частотного спектра анализируемого сигнала ![]() осуществляется в соответствии с выражением
осуществляется в соответствии с выражением ![]() , где
, где ![]() . На рисунке 4 изображены значения вектора
. На рисунке 4 изображены значения вектора ![]() для показателей бюджета, представленных на рисунке 1.
для показателей бюджета, представленных на рисунке 1.


Выражение ![]() представляет собой суперпозицию значений:
представляет собой суперпозицию значений: ![]() , где:
, где:  ,
,  ,
, ![]() - значение анализируемого сигнала в точке
- значение анализируемого сигнала в точке ![]() , где
, где ![]() . То есть, на каждой гармонике спектр представляет собой суперпозицию значений сигнала умноженного на значения опорных импульсных функций, которые подвергаются сдвигу на значение
. То есть, на каждой гармонике спектр представляет собой суперпозицию значений сигнала умноженного на значения опорных импульсных функций, которые подвергаются сдвигу на значение ![]() подинтервалов внутри каждого интервала. Использованное понятие гармоники не имеет отношения к гармоническому спектру. В работе под гармоникой формируемого обобщенного спектра понимается номер подинтервала
подинтервалов внутри каждого интервала. Использованное понятие гармоники не имеет отношения к гармоническому спектру. В работе под гармоникой формируемого обобщенного спектра понимается номер подинтервала ![]() , значениями которого являются
, значениями которого являются ![]() . С учетом произведенных изменений спектр
. С учетом произведенных изменений спектр ![]() запишем как:
запишем как:
 .
.
Учитывая преимущества предложенного метода, предложено использовать его при сравнении данных. Алгоритм сравнения состоит из четырех этапов, изображенных на рисунке 5. Здесь под расстоянием подразумевается выражение 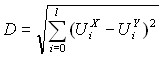 , где
, где ![]() и
и ![]() вектора спектров двух последовательностей, описывающих реализации X и Y анализируемого сигнала соответственно,
вектора спектров двух последовательностей, описывающих реализации X и Y анализируемого сигнала соответственно, ![]() - номер гармоники, который соответствует измерению вектора.
- номер гармоники, который соответствует измерению вектора.
В инструментах интеллектуального анализа данных для решения задачи классификации широкое распространение получили классификационные правила, главным образом из-за наглядности получаемых результатов.
Классификационные правила состоят из двух частей: условия и заключения: если (условие) то (заключение). Условием является проверка одной или нескольких независимых переменных. Заключением является значение независимой переменной или
распределение ее вероятностей по классам. Идея алгоритмов классификации на основе классификационных правил состоит в том, что для любого возможного значения независимой переменной формируется правило, которое классифицирует объекты из обучающей выборки. При этом в заключающей части правила указывается значение зависимой переменной, которое наиболее часто встречается у объектов с выбранным значением независимой переменной. Наиболее широкое распространение для решения задачи классификации на практике получил метод наивного байеса (naive bayes). Он позволяет выполнить задачу классификации с помощью расчета вероятности формулой байеса.
Суть разработанного алгоритма классификации в том, что в качестве признака для классификации используется длина ![]() вектора
вектора ![]() , то есть расстояние между вектором
, то есть расстояние между вектором ![]() и началом координат. На основе полученных значений
и началом координат. На основе полученных значений ![]() производится классификация методом наивного байеса. Алгоритм классификации состоит из пяти этапов, изображенных на рисунке 6.
производится классификация методом наивного байеса. Алгоритм классификации состоит из пяти этапов, изображенных на рисунке 6.
В третьей главе изучаются свойства разработанного метода и алгоритмов. Разработана программная реализация предложенных метода и алгоритмов. Произведена оценка трудоемкости метода сжатия дискретных данных. В качестве объекта анализа предложены база данных операционного бюджета производственных затрат промышленного машиностроительного предприятия в натуральном выражении. Исследованы результаты использования разработанных алгоритмов. Принимая во внимание, что умножения значений анализируемого сигнала на значения ![]() и
и ![]() тривиальны и эквивалентны смене знака, то трудоемкость алгоритма близка к
тривиальны и эквивалентны смене знака, то трудоемкость алгоритма близка к ![]() , что выше, чем у импульсного линейного преобразования Уолша и ему подобных, но меньше, чем у дискретного преобразования Фурье и вейвлет-преобразования и находится на уровне трудоемкости быстрого преобразования Фурье.
, что выше, чем у импульсного линейного преобразования Уолша и ему подобных, но меньше, чем у дискретного преобразования Фурье и вейвлет-преобразования и находится на уровне трудоемкости быстрого преобразования Фурье.
Для проведения численных экспериментов было разработано программное обеспечение, состоящее из нескольких блоков. Исходные данные для анализа содержатся в реляционном виде в СУБД Oracle. Блоки метода представления данных и сравнения данных реализован в виде набора хранимых процедур и функций на языке PL/SQL. Для разработки блока классификации был использован пакет интеллектуального анализа данных Oracle Data Mining, который входит в состав СУБД Oracle. Этапы вычислительного эксперимента, используемые программные средства и результаты, а так же исходные, выходные и промежуточные данные схематично представлены на рисунке 7.
Первый этап эксперимента состоял в исследовании разработанного алгоритма сравнения. Было использовано 30 реализаций двух баз экспериментальных данных. Базы данных представляют собой базу данных значений бюджета затрат на производство в натуральном выражении, характеризующих запланированный выпуск определенного вида продукции.
Все исследованные реализации случайных сигналов имеют одно и то же функциональное назначение, определенное методом экспертной оценки и различаются особенностями, которые выражаются в незначительных изменениях начальной фазы и амплитуды сигналов, что связано с изменением внешней среды, т.е. при сравнении таких данных должна наблюдаться высокая связь. Была произведена оценка 435 взаимных сочетаний исследуемых реализаций, которое равно ![]() , где
, где ![]() - количество исследуемых реализаций. На рисунке 8 изображены значения векторов первой базы данных для
- количество исследуемых реализаций. На рисунке 8 изображены значения векторов первой базы данных для ![]() .
.
На рисунке 9 изображены значения расстояния ![]() для всех сочетаний реализаций
для всех сочетаний реализаций


первой базы данных, ![]() . На рисунке 1 представлен вектор с близким к среднему значением. При более похожей форме сигналов, расстояние пропорционально уменьшается.
. На рисунке 1 представлен вектор с близким к среднему значением. При более похожей форме сигналов, расстояние пропорционально уменьшается.


На рисунке 10 представлены значения расстояний ![]() по каждому измерению, где
по каждому измерению, где ![]() - номер измерения. Видно, что на последних гармониках наблюдается больший разброс значений.
- номер измерения. Видно, что на последних гармониках наблюдается больший разброс значений.


Второй этап эксперимента состоял в оценке эффективности разработанного алгоритма классификации.
С помощью метода экспертной оценки был выделен класс «Не норма» аномальных конфигураций значений, приводящих к ненормативному выпуску продукции и класс «Норма», характеризующийся нормальным протеканием процесса производства.
С помощью разработанного алгоритма классификации был построен байесовский классификатор для значения ![]() . Значения для выделенных интервалов представлены в таблице 2.
. Значения для выделенных интервалов представлены в таблице 2.
С помощью полученного классификатора проведен анализ 100 реализаций случайного сигнала каждого класса. На рисунке 11 представлены значения длин векторов ![]() . Под средним значением подразумевается арифметическое среднее значений класса «Норма». Матрицу потерь
. Под средним значением подразумевается арифметическое среднее значений класса «Норма». Матрицу потерь ![]() можно записать как:
можно записать как:  , где
, где ![]() ,
, ![]() - гипотезы о принадлежности к соответствующим классам, а
- гипотезы о принадлежности к соответствующим классам, а ![]() ,
, ![]() - решения о принадлежности к соответствующим классам. Функцию потерь можно определить как
- решения о принадлежности к соответствующим классам. Функцию потерь можно определить как ![]() , где
, где
Таблица 2 - Данные байесовского классификатора
| Класс | Интервал значений | Отношение длины интервала к общей длине интервалов | Всего реализаций | Всего реализаций класса | Вероятность попадания в интервал |
| Норма | 1438-2364 | 0,283267 | 63 | 33 | 0,52381 |
| 2365-2459 | 0,028755 | 41 | 34 | 0,829268 | |
| 2460-2780 | 0,097889 | 48 | 32 | 0,666667 | |
| 2781-4707 | 0,589171 | 48 | 1 | 0,020833 | |
| Не норма | 1438-2377 | 0,287244 | 67 | 32 | 0,477612 |
| 2378-2579 | 0,061487 | 67 | 11 | 0,164179 | |
| 2580-3814 | 0,377485 | 38 | 29 | 0,763158 | |
| 3815-4707 | 0,272866 | 28 | 28 | 1 |
 .
.
Другими словами ошибочное решение принимается, если отклонение от среднего значения больше среднего отклонения от среднего значения соответствующего класса. Для исследуемых реализаций матрица потерь принимает значение ![]() . Видно, что ошибка отнесения класса «Норма» к классу «Не норма»
. Видно, что ошибка отнесения класса «Норма» к классу «Не норма»
наблюдалась 14 раз. Обратная ситуация наблюдалась 97 раз, что можно объяснить


отсутствием устойчивого кластера для второго класса.
Четвертая глава содержит описание проектирования системы. Разработана архитектура информационно-аналитической системы сравнительного анализа и ретроспективного анализа финансовых показателей. Определены основные требования к компонентам системы, проведен анализ существующих программных решений и платформ, произведен выбор платформы в соответствии со сформулированными требованиями. Разработана архитектура построения модуля сравнительного анализа, а так же требования к структуре входных и выходных данных. Схематично структура модуля изображена на рисунке 12. Разработан интерфейс пользователя с помощью программной среды Oracle Application Express.
Фрагмент формы интерфейса приведен на рисунке 13. Разработана программная реализация модуля преобразования последовательностей на базе разработанного алгоритма с помощью хранимых процедур и функций СУБД Oracle. Разработанная структура модуля ретроспективного анализа финансовых показателей изображена на рисунке 14. На рисунке 14, блок преобразования последовательностей выполнен в виде хранимой PL/SQL процедуры. Формирование классификатора и процедура классификации реализована с помощью хранимых PL/SQL пакетов системы Oracle Data Mining. Интерфейс пользователя разработан с помощью программной среды Oracle Application Express. Фрагмент формы интерфейса приведен на рисунке 15.
Элементы разработанной информационно-аналитической системы, а так же разработанные алгоритм и методики внедрены в ЗАО «УР БО», ЗАО «Тюменский судостроительный завод», ООО «Парус-Самара», ООО «Системы управления бизнесом» и используются в практической деятельности.
В заключении перечислены основные результаты, полученные в диссертационной работе:
- проанализированы проблемы анализа дискретных данных, циркулирующих в промышленном предприятии, возникающие при их сравнении и классификации, в качестве наиболее перспективных предложено считать спектральные методы представления информации;
- разработан метод сжатия дискретных данных на основе спектрального импульсного преобразования, который инвариантен к сдвигу сигнала и нечувствителен к незначительным изменениям сигнала, не влияющим на его функциональные характеристики;




- разработан алгоритм сравнения дискретных данных, который основан на анализе евклидова расстояния векторов спектров, полученных в результате предварительного сжатия данных;
- разработан алгоритм классификации дискретных данных, который использует в качестве признаков значения гармоник спектра, полученного в результате предварительного сжатия, что позволяет применять такие простые алгоритмы интеллектуального анализа данных, как метод наивного байеса;
- проведена оценка трудоемкости разработанного метода сжатия дискретных данных, которая близка к трудоемкости БПФ
- проведены численные эксперименты для изучения свойств разработанных алгоритмов, которые показали, что использование евклидова расстояния векторов спектров, полученных в результате предварительного сжатия данных, целесообразно использовать в качестве признака классификации и меры сравнения;
- разработано программное обеспечение, использующее разработанные методы и алгоритмы для решения задач сравнительного анализа бюджетов и ретроспективного анализа финансовых показателей предприятия.
Список опубликованных работ по теме диссертации
- Тверетин А.А. Методы представления генетической информации [Текст] / Л.С. Бекасов, А.А. Тверетин // Научно-информационный межвузовский журнал «Вестник Самар. гос. техн. ун-та. Сер. Физико-математические науки». – Самара, 2007. – №1 (14). - С. 129-134.
- Тверетин А.А. Исследование идентификации информационных компонент генов методом спектрального и временного анализа [Текст] / Л.С. Бекасов, А.А. Тверетин, Ф.Ф. Буканов // Научно-информационный межвузовский журнал «Вестник Самар. гос. ун-та. Сер. Технические науки». – Самара, 2008. – №3. - С. 324-330.
- Тверетин А.А. Метод формализации нуклеотидной последовательности в молекуле ДНК [Текст] / А.А. Тверетин // Тез. Докл. VII Всероссийской научно-практической конференции «Наука. Технологии. Инновации». – Новосибирск, 2006. – С. 87-88.
- Тверетин А.А. Аналоговое представление элементарных звеньев ДНК [Текст] / В.М. Подолян, А.А. Тверетин // Успехи современного естествознания. – Москва, 2008. - №4. – C. 127-128.
- Тверетин А.А. Оценка корреляции генетических текстов с помощью их спектральных характеристик [Текст] / А.А. Тверетин // Современные наукоемкие технологии. – Москва, 2008. - №6. – C. 96-97.
- Тверетин А.А. Сравнение конкатенированных данных на основе их спектральных характеристик [Текст] / Л.С. Бекасов, А.А. Тверетин // Современные наукоемкие технологии. – Москва, 2008. - №6. – C. 34-39.
- Тверетин А.А. Сравнение массивов дискретных данных на основе сжатия информации [Текст] / А.А. Тверетин // Журнал научных публикаций аспирантов и докторантов. – Курск, 2010. - №7. – C. 110-112.
- Тверетин А.А. Методика классификации массивов дискретных данных большой длины [Текст] / А.А. Тверетин // Журнал научных публикаций аспирантов и докторантов. – Курск, 2010. - №8. – C. 115-117.
- Тверетин А.А. Методика сравнения дискетных данных на основе сжатия информации [Текст] / А.А. Тверетин // Молодой ученый. – Чита, 2010. - №8(19). – C. 133-136.
- Тверетин А.А. Разработка системы сравнения бюджетов на основе информационного сжатия дискретных данных [Текст] / А.А. Тверетин // Актуальные проблемы гуманитарных и естественных наук. – Москва, 2010. - №8. – C. 83-85.
- Тверетин А.А. Разработка методики классификации дискретных последовательностей на основе сжатия информации и ее применение в системах глубинного анализа данных [Текст] / А.А. Тверетин // Информационные технологии моделирования и управления. – Воронеж, 2010. - №4(63). – C. 497-504.
Разрешено к печати диссертационным советом Д 212.217.03.
Протокол № 15 от 22 ноября 2010 г.
Заказ № 99. Формат 6084 1/16. Бумага тип. №1.
Печать офсетная. Уч.-изд. л. 1,0. Тираж 110 экз.
Самарский государственный технический университет.
Типография СамГТУ.
443100, г. Самара, Молодогвардейская ул. 244, Главный корпус