

На правах рукописи
Бабалова Галина Григорьевна
СИСТЕМНО-АСПЕКТУАЛЬНОЕ ФУНКЦИОНИРОВАНИЕ КОМПЬЮТЕРНОЙ ТЕРМИНОЛОГИИ
Специальность 10.02.19. – Теория языка
А В Т О Р Е Ф Е Р А Т
диссертации на соискание ученой степени
доктора филологических наук
Москва
2009
Работа выполнена на кафедре английского языка факультета информатики
Омского государственного педагогического университета
Научный консультант: доктор филологических наук, профессор
Марчук Юрий Николаевич
Официальные оппоненты: доктор филологических наук, профессор
Татаринов Виктор Андреевич
доктор филологических наук, профессор
Чалкова Елизавета Григорьевна
доктор филологических наук
Попова Татьяна Георгиевна
Ведущая организация: Коломенский государственный педагогический институт
Защита состоится «___ » ________ 2009 года в ___ часов на заседании диссертационного совета Д 212.155.04 по защите диссертаций на соискание учёной степени доктора наук при Московском государственном областном университете по адресу: 105082, г. Москва, Переведеновский пер., д. 5 / 7.
С диссертацией можно ознакомиться в библиотеке Московского государственного областного университета по адресу: 105005, г. Москва, ул. Радио, д. 10 а.
Автореферат разослан «__ » ________ 2009 г.
Ученый секретарь
Диссертационного совета
доктор филологических наук,
профессор Хухуни Георгий Теймуразович
Общая характеристика работы
В настоящее время терминологии оказываются важными факторами научно-технического прогресса, поэтому законы становления и функционирования терминологий и их системная организация оказываются в центре внимания теории языка.
Под системно-аспектуальным функционированием компьютерной терминологии, исходя из названия диссертации, подразумевается её функционирование в трёх аспектах: собственно-терминологическом, переводческом и лексикографическом. Применительно к терминологическим исследованиям, включая данную работу, под системой следует понимать «… целое, в котором элементы взаимосвязаны при помощи ограниченного числа регулярных семантических отношений. Очевидно, что понятие системности теснейшим образом связано с понятием классификации, а системность терминологии – с системностью знания» [Никитина, 1987, с. 55].
Терминология любой области знания составляет семантическое ядро языков для специальных целей (LSP). Семантическим ядром подъязыка информатики является компьютерная терминология, которая представляет собой терминосистему. По существу, любая терминология – это система, состоящая из подсистем и микросистем. Вопрос о системности терминологии не вызывает сомнений. В настоящее время разработаны критерии, с помощью которых можно представлять наиболее значимые характеристики любой терминосистемы [Гринёв, 1993], [Казарина, 1998]. Терминосистемы различных областей знания подвергаются детальному изучению [Анисимова, 1994], [Бушин, 1996], [Гаврилина, 1998], [Дорошенко, 1995], [Евстифеева, 2007], [Егоршина, 1994], [Ивина, 2003], [Лаврова, 1996], [Морщакова, 1997], [Оськина, 2007], [Рудинская, 1997], [Рявкина, 1997], [Стельмак, 1996] и др.
Некоторые исследователи утверждают, что развитие терминосистем в большей мере зависит от экстралингвистических факторов [Липилина, 1998], [Хабирова, 1989], [Шиманская, 1990]. С учётом специфики формирующейся терминосистемы информатики в данной работе предложены экстралингвистические характеристики, которые содержат информацию о возникновении и становлении компьютерной терминологии, eё межпредметных связях, интернациональном характере и проблемах интерференции.
Современное терминоведение переживает новый этап. Всё большей популярностью пользуются комплексно-вариологический и когнитивный подходы в отношении трактования сущности термина [Авербух, 2004], [Зяблова, 2004], [Ивина, 2003], [Новодранова, 1997] и др. Когнитивное терминоведение помогает решать теоретические и прикладные вопросы совершенствования и обогащения специальной лексики. В связи с этим можно предположить, что дискуссии учёных по поводу основных характеристик термина объясняются тем, что наряду с терминами существуют специальные лексические единицы, которые были выделены и описаны: номены [Винокур, 1939], профессионализмы [Кузьмин, 1970], профессиональные арготизмы [Скворцов, 1972], или профессиональные жаргонизмы [Гладкая, 1977], предтермины [Лейчик, 1985] и квазитермины [Лейчик, 1981], терминоиды [Хаютин, 1972], прототермины [Гринёв, 1990].
Вопрос об особенностях функционирования терминов также остаётся дискуссионным. Однако и он теряет свою остроту, поскольку по мере его изучения учёные приходят к выводу о том, что хотя понятие «термин» и невозможно охарактеризовать без учёта выполняемых им функций, нет оснований и ограничиваться этим его свойством [Алексеева, 1998], [Ивина, 2003], [Моисеев, 1970], [Никифоров, 1966]. Тем более, что «функции термина с точки зрения лингвистической идентичны функциям, выполняемым словом общеязыковой сферы использования, а об особой функции термина можно говорить лишь в экстралингвистическом аспекте по отношению к объектам и понятиям профессиональной сферы деятельности» [Авербух 2004, с. 75].
В соответствии с этим в коммуникативных процессах «человек – ЭВМ» выделяют: 1) функцию номинации в информационных языках дискрипторного типа, 2) функцию классификации в информационных языках классификационного типа, 3) функцию управления в информационно-управленческих системах [Головин, Кобрин, 1987]. Кроме того, при составлении специализированных словарей лексикографы прибегают к помощи аппарата лексических функций [Крейдлин, Шмелёв, 1994], логико-семантических функций [Никитина, 1987].
Особое внимание в данной работе уделено проблемам перевода. «Перевод является единственным эффективным средством преодоления языковых барьеров, которые, в свою очередь, являются главным препятствием в распространении научных, технических и прочих знаний и информации, фундирующих прогресс человечества» [Марчук, 2005]. Вопросы достижения эквивалентности перевода занимают умы многих учёных и широко обсуждаются [Виноградов, 2004], [Влахов, 1986], [Казакова, 2002], [Клишин, 2003], [Комиссаров, 1997], [Крупнов, 2005], [Латышев, Семёнов, 2003], [Нелюбин, 2003] и мн. др. Проблемы достижения эквивалентности перевода терминологии имеют первостепенное значение в процессе подготовки (обучения) дополнительной специальности «Переводчик в сфере профессиональной коммуникации», осуществляемой в последние 10 лет в российских вузах. «Профессиональное знание (обучение, подготовка) требует овладения соответствующим подъязыком, основу которого составляет специальная лексика» [Суперанская, Подольская, Васильева, 2003].
Проблемы перевода специальной литературы также не остаются без внимания [Борисова, 2002], [Дмитриева, Кунцевич, Мартинкевич, 2005], [Полякова, 1998], [Пронина, 1973] и др. В связи с включением результатов научных исследований в общее русло культурного развития, научной пропаганды и практики возникает потребность переводимости языка науки на естественный язык с целью популяризации, облегчения понимания. Отсюда появление образной лексики, сравнений, аналогий, конструкций экспрессивного синтаксиса. По этой причине научный текст может и должен анализироваться в строгом терминологическом смысле как дискурс [Чернявская, 2004].
Одной из основных задач терминоведения является обеспечение быстрого поиска необходимой научно-технической информации. Для этой цели создаются автоматизированные банки информации (АБИ), классификация которых осуществляется с различных точек зрения (по режимам функционирования, по назначению и т.д.). В настоящее время сложились основные концепции в построении банков информации: банки документов, банки данных и банки знаний [Полищук, Хон, 1098]. Одна из сторон лингвистического обеспечения вышеназванных интеллектуальных систем обработки с использованием ЭВМ – это создание машинных словарей.
Г.Е. Крейдлин и А.Д. Шмелёв описывают работу машинного тезауруса диалогового процессора, подчёркивая тот факт, что «тезаурусы позволяют сравнительно простыми средствами учесть многозначность основных лексических единиц языка – слов и устойчивых словосочетаний …, а синонимия разрешается либо путём формирования классов условной эквивалентности и присвоения в ЭВМ одинаковых кодов всем ключевым словам одного класса, либо с помощью указателя иерархических отношений. При учёте парадигматических отношений между понятиями, включаемыми в словари-тезаурусы, коды видовых и родовых понятий записываются совместно с кодом рассматриваемого понятия» [Крейдлин, Шмелёв, 1994].
В настоящее время на рынке программного обеспечения имеется чрезвычайно широкий выбор электронных словарей: от самых простейших (например, DIS) до мощных систем, объединяющих в одной программной оболочке несколько лексических баз данных, – специализированных тематических словарей, последовательность которых определяет пользователь. Классификация ЭС может быть проведена по следующим критериям: 1) по используемой операционной системе; 2) по способу загрузки; 3) по количеству подключаемых словарных баз (словарей); 4) по возможностям расширения словарной базы; 5) по режиму перевода [Богданов, 2002]. Основываясь на вышеназванной классификации, а также, принимая во внимание общие и отличительные особенности электронных и бумажных словарей, представляется целесообразным выделить критерии для проведения сопоставительного анализа наиболее популярных ЭС: Лингво, Полиглоссум, Мультилекс и Контекст: принцип морфологичности, удобство и полнота содержания словарной статьи, режим поиска, возможность двухстороннего перевода, возможность перевода словосочетаний и предложений и др.
Таким образом, современное состояние гуманитарной науки, с одной стороны, и объективные условия изменившегося мира – с другой, требуют нового осмысления проблем, как уже известных, так и актуальных для нового времени.
Настоящая работа представляет собой попытку создать соединительный канал между мощными потоками исследований в области языкознания и информатики. Этим и обусловлена её актуальность.
Объектом исследования является функционирование компьютерной терминологии в собственно-терминологическом, переводческом и лексикографическом аспектах.
Предметом исследования избраны термины подъязыка информатики.
Научная новизна работы определяется прежде всего тем, что терминология информатики рассматривается одновременно в трёх аспектах: собственно-терминологическом, переводческом и лексикографическом. Взаимосвязь этих аспектов способствовала составлению «Тезауруса по программированию» (см. Приложение к диссертации). Принципиально новым является выявление параллелизма функционирования компьютерной терминологии в собственно-терминологическом и лексикографическом аспектах. Теоретические предпосылки, постулируемые в диссертации, находят подтверждение в практических исследованиях.
Цель исследования заключается в выявлении закономерностей системно-аспектуального функционирования компьютерной терминологии.
Поставленная цель предполагает решение следующих задач:
1) рассмотреть экстралингвистические аспекты компьютерной терминологии: историю её возникновения и становления, межпредметные связи, интернациональный характер и проблемы интерференции.
2) определить закономерности терминообразования, иначе говоря, средства и способы образования терминов информатики;
3) описать семантические процессы в компьютерной терминологии;
4) дать классификационную характеристику терминов информатики с использованием теории «поля» и метода компонентного анализа;
5) описать способы достижения функциональной эквивалентности перевода компьютерной терминологии;
6) провести сопоставительный анализ электронных словарей Контекст 4.0, Polyglossum 3.2, Lingvo, Мультилекс.
Основная гипотеза диссертации: терминологическая система информатики представляет собой функционально-семантическое единство, элементы которого взаимосвязаны и взаимообусловлены. Единый аппарат логико-семантических функций для собственно-терминологического и лексикографического аспектов свидетельствует о параллелизме функционирования компьютерной терминологии.
Теоретическая значимость исследования определяется тем, что теоретические предпосылки системной организации терминологических единиц предполагают их классификацию по средствам и способам номинации, семантическим процессам, экстралингвистическим аспектам, тематическим полям и лексико-семантическим группам. Системное функционирование терминологии находит отражение в способах построения словарной статьи в терминологическом словаре с использованием формальных методов (логико-семантических функций, моделей и алгоритмов), что, в свою очередь, находит отражение в процессе автоматизации лексикографических работ. Функциональной эквивалентности перевода терминологии можно также достичь, используя формальные методы в предпереводческом анализе научно-технического текста.
Практическая значимость работы обусловлена следующими соображениями:
– выводы и материал диссертации могут быть использованы в практике вузовского преподавания курсов общего языкознания, лексикологии, теоретической грамматики, стилистики, переводоведения; отдельные положения и фрагменты работы могут быть использованы в практике преподавания спецкурсов и спецсеминаров;
– наблюдения над особенностями функционирования терминологии могут быть полезны как для теоретической, так и практической лексикографии, в частности, для составления электронных словарей а также программ машинного перевода (имеется в виду лингвистическое обеспечение с использованием формальных методов).
Методика анализа определялась целью и материалом исследования. Поскольку в работе исследуется современное состояние терминологического функционирования, то это обусловило применение синхронного подхода к исследованию материала с элементами диахронии. Использован комплекс дополняющих друг друга методов: сопоставительный метод, метод комплексного структурно-семантического анализа, метод компонентного анализа, метод дефиниций, метод статистических данных, метод графической презентации исследуемого материала.
Сопоставительный метод нашёл применение при исследовании межпредметных связей, при описании функциональной эквивалентности перевода терминологии, при сопоставительном анализе электронных словарей.
Необходимость отбора материала для исследования продиктована его принадлежностью к научно-техническому стилю: учебники по информатике и вычислительной технике, научные и научно-популярные журналы, лексикографические источники. В качестве дополнительных источников по мере необходимости привлекался и материал Интернета (статьи, чаты и пр.).
Положения, выносимые на защиту:
1). Терминология информатики развивается в сторону интернационализации. Межъязыковая, внутриязыковая и тематическая интерференция подтверждают её экстралингвистическую обусловленность. В свою очередь, тематическая интерференция обусловлена межпредметными связями.
2). Средства номинации компьютерных терминов универсальны и кодифицированы: термины-слова, термины-словосочетания и символо-слова. Классификация терминов-слов может осуществляться в соответствии с морфемной структурой слова: а) непроизводные, б) производные, в) сложные. На наш взгляд, аббревиатуры, причисляемые некоторыми исследователями к сложным словам, следует отнести к терминам-словосочетаниям. Термины-словосочетания образуются по определённым моделям с многокомпонентной структурой. Способы терминологической номинации также универсальны: а) семантический способ, б) аффиксация, в) словосложение, г) аббревиация, д) заимствования.
3). Семантическое единство терминологии чётко прослеживается в процессе изучения её семантических процессов (полисемии, синонимии, антонимии, гипонимии).
4). На основе гипонимии термины информатики последовательно объединяются в тематические группы и поля, что может найти отражение в структуре идеографических словарей, например, в структуре фрагмента тезауруса по программированию (см. Приложение).
5). При переводе компьютерной терминологии с английского языка на русский рекомендуется использование трансформационных методов с целью достижения эквивалентности перевода подлиннику. Наиболее популярными переводческими приёмами являются: транскрибирование с элементами транслитерации, калькирование, конкретизация, генерализация, перевод с помощью эквивалентов и аналогов. Это касается терминов-слов. В отношении терминов-словосочетаний практикуются несколько иные способы перевода, в частности, перевод при помощи фразеологической эквивалентности, фразеологического аналога, описательный метод, однословный метод перевода, калькирование, приём создания индивидуальных эквивалентов, приём стилистического обновления, приём «просветления» фразы и комбинированный метод перевода.
6). Для обеспечения эквивалентности перевода подлиннику представляется возможным пойти по пути формализации, в частности, создания алгоритма предпереводческого анализа. Алгоритм анализа может включать: определение функционального стиля переводимого текста, его весовых коэффициентов, оценочной функции, а также учёт форматирования в электронных документах. Формализация предпереводческого анализа может иметь значение как для человека-переводчика, так и для систем машинного перевода.
Апробация исследования. Основные теоретические положения работы изложены в научных статьях и докладах (36), а также в монографиях: «Лингвистические аспекты информатики (терминология и лексикография)» (Омск, 2004), «Оптимизация функциональной природы подъязыка информатики» (Омск, 2007). Материалы исследования обсуждались на заседаниях кафедры английского языка факультета информатики Омского государственного педагогического университета, кафедры теоретической и прикладной лингвистики Московского государственного областного университета, а также на научных региональных, всероссийских и международных конференциях. Лицензирована дополнительная специальность «Переводчик в сфере профессиональной коммуникации» в Омском государственном педагогическом университете (лицензия А № 001283 от 25.04.2005 г.), в Омском юридическом институте (лицензия А № 255738 от 29.03.2007 г.), зарегистрирована в Учебно-методическом объединении дополнительная специализация «Компьютерная лингвистика», реализуемая в Омском государственном педагогическом университете (№ 101/62 от 14.03.2002 г.), научным руководителем которых является автор.
Основное содержание работы
Первый раздел диссертации, именуемый «Компьютерная терминология в экстралингвистическом и лингвистическом аспектах», содержит 5 глав. В первой главе предлагается общая характеристика языков для специальных целей (LSP) и рассматриваются основные положения терминоведения. Языки для специальных целей как область существования специальной лексики неразрывно связаны с национальным языком. В. П. Даниленко отмечает, что на базе литературного языка формируется язык науки – самостоятельная функциональная подсистема со своим инвентарём средств выражения специальных понятий (знаков), правилами их организации и оценки. Терминологии принадлежит в нём центральное место [Даниленко, 1977, с. 14].
В современном терминоведении терминология рассматривается как терминосистема. «Терминосистема – совокупность единиц специальной номинации некоторой области деятельности, изоморфная системе её понятий и обслуживающая её коммуникативные потребности» [Ивина, 2003, с. 27]. В свою очередь, термин трактуется как элемент терминосистемы. В первой главе диссертации приводится несколько определений термина, его различные характеристики, требования, предъявляемые к термину, основные его признаки. Несмотря на значительные расхождения по этим вопросам, мнения учёных сходятся в том, что для своего правильного понимания термин требует специальной дефиниции (точного научного определения), а определение (собственно дефиниция) термина – это объяснение его понятийного содержания.
Во второй главе первого раздела рассматриваются экстралингвистические предпосылки формирования терминосистемы информатики, к которым, в первую очередь, относится история возникновения и становления информатики. Информатика – сравнительно молодая наука. Она появилась несколько десятилетий назад, а развивалась и развивается в основном на фоне современных достижений науки и техники. Информатика с момента выделения в самостоятельную предметную область стала бурно развиваться во многих странах. Этим объясняется межъязыковая интерференция, которую можно заметить не только как процесс активной ассимиляции заимствований из других языков, но и как процесс адаптации терминов-калек, например: computing system catalog – компьютерный системный каталог, Computer Graphics Interface (CGI) – интерфейс компьютерной графики. Внутриязыковая интерференция обусловлена суборнативным билингвизмом, который выражается в переносе знаний, умений и навыков из родного языка в иностранный. В целях устранения интерференции на лексическом и синтаксическом уровнях разработано педагогическое программное средство [Бабалова, Сердцева, 2002, с. 204-212].
Тематическая интерференция в компьютерной терминологии вызвана межпредметными связями информатики. Исследование показало, что компьютерные термины имеют самые тесные связи с терминами смежных предметных областей (математика, вычислительная техника, радиоэлектроника). Здесь значения терминов практически одинаковы, можно сказать, копируют друг друга. Следует заметить, что межпредметные связи между информатикой и юриспруденцией, информатикой и экономикой, информатикой и медициной и т.д. также достаточно близкие. Мы не можем говорить о полном соответствии, например, медицинских терминов и компьютерных, т.к. имеет место метафорический перенос. Например, термин card присутствует и в словаре компьютерных терминов, и в словарях смежных с информатикой наук, таких как вычислительная техника, физика, математика. Он присутствует также в медицинском и в юридическом словарях. В словарях смежных с информатикой наук значения идентичны: 1) карта, перфокарта, 2) плата. В других предметных областях он употребляется в переносном смысле на основании сходства, аналогии, например: карта (мед.) – небольшой прямоугольный кусок бумаги, картона с напечатанным на нём текстом.
Особое внимание в работе уделено проблематике заимствований.
Таблица 1
Заимствования в компьютерной терминологии
| Разделы информатики | Межъязыковые | Английский | Немецкий | Итальянский | Французский | Исландский | Латинский | Греческий | Фризский | Готский | Датский | Протогерман | Друдгие инндо-европейские языки |
| Л Информация и информационные процессы | 4 | 1 | 2 | 4 | 1 | ||||||||
| Компьютеры | 21 | 12 | 9 | 9 | 5 | 11 | 3 | 4 | 3 | 1 | 3 | 3 | |
| Формализация и моделирование | 6 | 3 | 2 | 1 | 3 | 1 | 4 | 1 | 1 | 1 | 1 | ||
| Алгоритмизация и программирование | 12 | 3 | 1 | 10 | 9 | 2 | 1 | 1 | |||||
| Информационные технологии | 15 | 5 | 4 | 12 | 1 | 10 | 1 | 1 | 1 | 1 | |||
| Представление информации | 6 | 3 | 3 | 3 | |||||||||
| Общее количество заимствований | 27 | 16 | 1 | 39 | 7 | 41 | 8 | 5 | 4 | 2 | 6 | 5 |
Статистические данные свидетельствуют о том, что самыми «активными поставщиками» компьютерной лексики являлись латинский, французский и английский языки. Этимологические данные дают информацию об интернациональном характере компьютерных терминов. Эти термины с уверенностью можно назвать интернационализмами, т.к. они не только совпадают по своей внешней форме в разных языках, но и выражают понятия международного характера.
Исследования показали, что значительная часть компьютерной терминологии (около 80 %) является интернациональной; сюда входят термины-слова, термины-словосочетания. Особую группу интернационализмов представляют графические символы. То же можно сказать в отношении аббревиации. Специалисты разных национальностей понимают эти термины, и даже необязательно специалисты в области информатики.
Заимствованные термины подъязыка информатики можно классифицировать:
1) по источнику заимствований, например термин address заимствован из французского языка (фр. addresser), alphabet – из греческого языка (греч. alphabetos), code – из латинского языка (лат. codex);
2) по аспекту заимствований (по тому, какой аспект слова является новым для принимающего языка):
а) фонетический аспект (общий звуковой комплекс оказывается новым для заимствующего языка), например: montage (франц. яз.), moir (франц. яз), medium (лат. яз.);
б) семантический аспект (заимствование нового значения, часто переносного, к уже имеющемуся слову в языке), например language (лат. lingua). Под компьютерным термином language понимают язык, используемый для написания программ для компьютера;
в) морфологический аспект (заимствование отдельных значащих частей слова: корневых морфем, префиксов, суффиксов), например префиксы латинского происхождения ab-, anti-, non- в терминах: abort, anti-clash, nonprint;
г) переводческий аспект (калькирование, или заимствование в виде буквального перевода иностранного слова или выражения, т. е. в виде точного воспроизведения средствами принимаемого языка с сохранением морфологической структуры и мотивированности, например: index character (лат. яз.), parallel computer (франц. яз.);
3) по степени ассимиляции:
д) полностью ассимилированные (соответствуют всем фонетическим, орфографическим и морфологическим нормам заимствовавшего языка), например: table (франц. яз.), disc (лат. discus), code (лат. codex);
е) частично ассимилированные (оставшиеся иностранными по своему произношению, написанию или грамматической форме), например: moire (франц. яз.), medium (лат. яз.);
ж) безэквивалентные частично ассимилированные (связанные с чужеземной национальной культурой и не имеющие эквивалентов в принимающем языке), например: Hangeul – письменный язык в Корее, Hanja – китайские буквы, используемые в корейском языке.
Средства терминологической номинации в информатике неоднородны. Обычно выделяют два типа терминов: термины-слова (термины-лексемы), например code, disk, display и термины-словосочетания (термины-фраземы), например abstract data type (абстрактный тип данных), initial program loader (начальный загрузчик программ). В.П. Даниленко предлагает ещё один тип терминов – это символо-слова: «особый комбинированный структурный тип терминологической номинации, в состав которой наряду со словесными знаками входят символы (литеры, цифры, графические знаки: (включение), | (выводимость) и др.» [Даниленко, 1977, с. 37].
Классификация терминов-слов осуществляется в соответствии с морфемной структурой слова: а) непроизводные; б) производные; в) сложные. В ходе исследования выделено семь типовых форм образования терминологических словосочетаний (с подтипами). Способы терминологической номинации в информатике также разнообразны. К ним относятся: семантический способ, аффиксация, словосложение, аббревиация и заимствования.
Исследования показали, что в подъязыке информатики происходят те же лексико-семантические процессы и явления, что и в общелитературном языке, в частности, полисемия (cell – 1) основная единица в электронных таблицах; 2) прямоугольник в месте пересечения строки и столбца; 3) ячейка памяти); синонимия (diskette, floppy disk, flexible disk – дискета), омонимия (argument – 1) довод, аргумент; 2) независимая переменная), антонимия (start – end, internal – external).
Наблюдения за семантическими процессами в компьютерной терминологии показали, что здесь имеет место и такое явление как гипонимия. Проиллюстрируем примером из компьютерной терминологии. Термин subdirectorie (субдиректория, подкаталог) является гиперонимом по отношению к таким терминам (гипонимам) как bin (каталог внешних команд), user (каталог, содержащий отдельные подкаталоги для всех пользователей системы), accounts (каталог, содержащий информацию счёта), programs (каталог программы), memos (каталог текстовых файлов). В приведённом примере находит отражение многоуровневая структура понятия субдиректории (или подкаталога). На основе гипонимии взаимосвязанные лексические единицы последовательно объединяются в тематические и лексико-семантические группы, подклассы и классы, семантические поля и семантические сферы, что находит отражение в структуре идеографических словарей.
Для терминологических единиц любой предметной области, в том числе и информатики, свойственна системность. Теория «поля», метод компонентного анализа (МКА) и группировки терминологических единиц может найти применение в области исследования компьютерной терминологии. В данной работе в основу распределения компьютерных терминов по лексико-грамматическим полям положена их идентификация отдельными лексемами, словосочетаниями или развёрнутыми описаниями в лексикографических источниках, а также наличие интегрирующих элементов их семантики. На основе анализа компонентов семантики компьютерных терминов представляется возможным выделить лексико-грамматические поля (ЛГП): ЛГП с родовым понятием «программное обеспечение», ЛГП с родовым понятием «языки и методы программирования», ЛГП с родовым понятием «теоретические основы информатики», ЛГП с родовым понятием «архитектура ЭВМ» и др.
Наибольшее количество терминов в сфере информатики и вычислительной техники входит в ЛГП «языки и методы программирования». Компьютерные термины, относящиеся к этой области, составляют часто употребительную и типичную серию терминов и различаются развитой системой значений, образов и средств выражения. Наиболее часто в данном ЛГП встречаются конституенты, объединённые таким понятием как команда (Command). Они являются основой создания различных приложений как аппаратного, так и программного обеспечения компьютера. Следовательно, конституенты микрополя Command представляют собой концептуальный материал для исследования.
Микрополе команд можно представить в виде схемы:
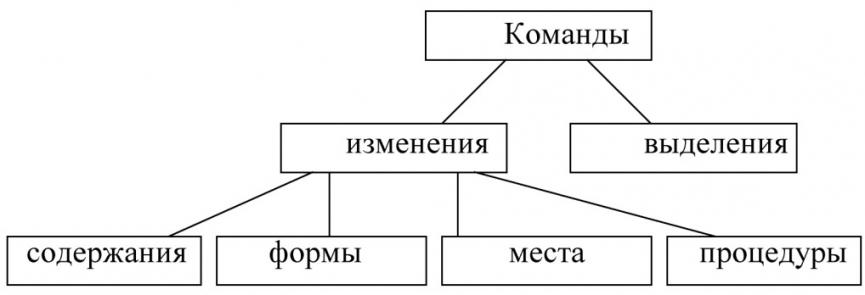
Распределение языковых средств (терминов) по группам и подгруппам может происходить неравномерно: одна группа включает большое количество терминоединиц, другая – относительно малое. Например, группа терминов выделения, по нашим подсчётам, включает 7 терминов: select, unselect, mark out, search, find, choose, locate. В неё входят глаголы, обладающие общим семантическим признаком «выделение объекта» (или группы объектов) из класса объектов.
Проведённое исследование намечает один из возможных путей изучения компьютерной терминологии. При этом раскрываются центральные и периферийные, грамматические и лексические средства, передающие определённое коммуникативное содержание. Описанное микрополе команд представляет лишь часть системы языковых отношений компьютерных терминов. Задачей дальнейшего исследования в этой области может быть полное изучение всех элементов системы.
Предпринята также попытка тематической классификации компьютерной терминологии. При составлении классификации были использованы учебники по базовому курсу информатики [Могилёв, 1999], [Шафрин, 2000].
Таблица 2
Логико-семантические признаки компьютерных терминов раздела
«Информация и информационные процессы»
| Тема раздела | Логико-семантические признаки компьютерных терминов | |||||||||
| Объект | Назначение/ функция | Инструментал ьность | Действие/ процесс | Адресность/ фамильность | Идентификатор | Счисление/сист ема счисления | Устойчивость | Квантитатив ность | Сходство | |
| Единицы измерения информации | + | – | – | – | – | + | + | – | – | – |
| Процессы хранения, обработки и передачи информации | + | + | – | + | + | + | + | + | – | + |
В основу классификации положено распределение терминов по тематическим разделам курса информатики (информация и информационные процессы; представление информации; моделирование и формализация; алгоритмы и исполнители; информационные технологии) с учётом логико-семантических признаков этих терминов. В качестве компонентов внутренней структуры термина выделено 10 логико-семантических признаков (или логико-семантических функций). (См. табл. 2). Во фрагменте тезауруса по программированию в Приложении к диссертации представлен тот же аппарат логико-семантических функций. Теория «поля», метод компонентного анализа и группировки терминологических единиц может найти применение в лексикографии.
Раздел II (4 главы) посвящен проблемам функциональной эквивалентности перевода терминологии, проблемам профессионально-ориентированного перевода.
При переводе терминов следует учитывать, что многие термины многозначны, т. е. имеют различные значения не только в разных областях науки и техники, но даже в одной и той же области. Примером тому может послужить терминология подъязыка информатики. Наличие независимо работающих коллективов разработчиков вычислительных систем определённой фирмы или архитектуры обусловило независимое развитие разных терминологических «диалектов», отражающих одну и ту же предметную область. Одно и то же понятие иногда обозначается разными терминами, а один и тот же термин используется в разных значениях. Поэтому при переводе текстов необходимо осмыслить, правильно истолковать термин и правильно подобрать русский эквивалент. Например, transaction может означать «трансакция», «обработка запроса», т. е. в диалоговых системах – приём порций данных от пользователя, их обработка и выдача ответного сообщения. Этот же термин в этом же подъязыке может означать «запрос, запись файла изменений». Вместо track density, термина, обозначающего плотность записи на дисковом запоминающем устройстве, используется акроним TPI, т. е. единица измерения плотности записи.
Перевод терминов-аббревиатур представляет большую трудность по причине многозначности и отсутствия прецедента их использования ранее. Например, PC имеет всем известный английский эквивалент Personal Сomputer. Однако он имеет и другие эквиваленты: potential controller – регулятор потенциала; printed circuit – печатная схема; process control – управление (технологическим) процессом; programmabal control – программное управление (ПУ); propulsive coefficient – пропульсивный коэффициент. И это далеко не полный перечень омонимов. Лишь глубокое знание предмета может помочь правильно понять термин. Если же сокращения используются вне контекста (спецификации, прилагающиеся к технической документации, таблицы, перечень запасных частей), то необходимы консультации специалистов, работа с всемирной сетью, большая компаративная работа с несколькими идентичными текстами, в которых могут встретиться такие термины и быть декодированы по контексту.
Однако по-настоящему профессиональную консультацию в этом отношении могут предложить терминологические базы знания в КНТ РАН, о которых пишут С. Д. Шелов и Ю. И. Крюков: «В Комитете научной терминологии в области фундаментальных наук (КНТ РАН) разработана экспериментальная компьютерная терминологическая база знаний (ТБЗ). Её основное назначение – соединить в себе компьютерный терминологический банк данных с возможностями компьютерного представления знания, т. е. служить программным продуктом, который содержит информацию не только о терминах (т. е. в конечном итоге – о единицах языка), но и о понятиях и объектах, которые стоят за этими языковыми единицами» [Шелов, Крюков, 2006, с. 195].
Как уже было упомянуто, дополнительная специальность «Переводчик в сфере профессиональной коммуникации», реализуемая в российских вузах, пользуется социальным спросом, однако в силу своей новизны она ещё недостаточно оснащена методическими материалами. Поскольку специалисты различных областей имеют собственную терминологию, то следует акцентировать внимание на взаимосвязи перевода и специальной терминологии, более того, письменный перевод нужно предпочесть устному, т. к. в плане восприятия оригинала он проще. Дело в том, что курс перевода, естественным образом основываясь на языковых курсах (родного и иностранного языков), усложняет языковую деятельность студентов. «Чтение текстов проще аудирования, однако письменный перевод уже сложнее даже аудирования, поскольку требует не просто свободного восприятия и некой реакции на предъявляемый текст, а его определённого рода обработки и воспроизведения на ином языке» [Тюленев, 2004, с. 307]. При любом виде письменного перевода анализ материала (его осмысление) выполняется переводчиком полностью. Виды перевода отличаются не этапом анализа, а синтезом, т.е. способом изложения осмысленной информации.
В. Е. Чернявская классифицирует тексты в сфере научной коммуникации в соответствии с доминирующей текстовой функцией следующим образом:
1) академические (научно-теоретические), реализующие собственно исследовательские цели и вербализирующие новое научное знание;
2) научно-информационные;
3) научно-критические;
4) научно-популярные, создаваемые с целью массового распространения, популяризации определённых научных сведений;
5) научно-учебные, связанные с дидактическими целеустановлениями, т. е. создаваемые специально для учебных целей [Чернявская, 2004, с. 38–39].
В учебном плане подготовки переводчиков важное место занимает курс общей теории перевода, который служит основой для становления всех видов переводческой деятельности. «Базовый курс перевода, складывающийся из двух частей – оснащения студентов (1) необходимыми теоретическими знаниями и (2) практическими навыками, – должен, например, в отличие от курса лекций по теории перевода, ставить перед собой задачу «проложить мост» между этими двумя частями, что определяет подход к выбору рекомендуемой студентам литературы по введению в предмет перевода. Она может быть не слишком специализированной и в то же время давать основополагающие сведения о специфике переводческой деятельности. Пособия такого рода можно назвать условно-теоретическими, поскольку в них собственно теория перевода представлена минимально, зато немало внимания уделяется практическому её применению, приводятся примеры из переводческого опыта самих авторов, что заметно оживляет подачу переводческих проблем ещё малоподготовленной к их восприятию читательской аудитории» [Тюленев, 2004, с. 306–307].
Наглядным примером тому может служить «Новый словарь-справочник активного типа. Научная речь на английском языке» [Рябцева, 1999]. Справочник построен на представительном материале оригинальных английских научных текстов и содержит системно упорядоченные выражения, словосочетания, обороты и примеры, характерные для английского научного стиля и позволяющие просто, чётко и ясно излагать свои мысли на английском языке и связывать их в единое целое – резюме, тезисы, доклад, статью, рецензию.
На современном этапе лингвистика описывает роль языка в общественной практике, учитывая как его системные свойства, так и его социально-прагматический аспект. Такой коммуникативно-социально-прагматический подход к решению вопросов речевой деятельности обусловлен как необходимостью углубить понимание процессов познания, так и практической потребностью в выработке средств максимального влияния на сознательное поведение людей в условиях массовой коммуникации и межличностного общения.
Отсюда следует, что факт существования интернациональной лексики и, главным образом, понимание условий её функционирования, её системно-структурных отношений может способствовать оптимизации познавательных процессов в любой сфере человеческой деятельности. Интернациональная лексика как продукт истории и как лингвистический феномен занимает умы многих учёных. Однако нельзя сказать, что существующие вузовские учебники по языкознанию, лексикологии, теории и практике перевода изобилуют разнообразием материала по тематике интернационализмов. К сожалению, следует констатировать факт единообразия в подаче информационного материала по вопросам интернационализмов. По этой причине предпринята попытка классифицировать интернациональную лексику по степени соответствия в русском и английском языках. Классификация проведена на материале более 250 интернационализмов, зафиксированных в словарях: [Апресян, 1990], [Зенович, 1998], [ЛЭС, 1990], [Палажченко, 2004], [Пахотин, 2003].
Интернациональная лексика может быть классифицирована на три вида: полные соответствия; интернациональные слова, частично совпадающие по значению; интернациональные слова, полностью не совпадающие по значению. В основу данного деления интернационализмов положены параметры различий в семантической структуре. Различия могут охватывать число значений, семантическую иерархию, понятийное содержание, реалии, стилистические характеристики, различия в коннотации, лексическую сочетаемость. На практике эти различия часто переплетаются.
Полные соответствия. К данной группе интернационализмов относятся лексические единицы, совпадающие не только графически и фонетически, но и в семантическом плане. Полные соответствия, как правило, стилистически маркированы как книжно-литературные. Их основу составляют различного рода международные термины (научная, общественно-политическая лексика). В последние годы мы всё чаще стали сталкиваться с американизмами в русской речи. Слово дилер укоренилось в русском языке и даже вошло в словари.
Ask your dealer for details – За деталями обратитесь к вашему дилеру.
Интернациональные слова, частично совпадающие по значению. В эту группу входит достаточно большое число интернационализмов, которые совпадают в одном значении, но остальные значения различны. Слово cluster переводится как кластер только тогда, когда оно встречается в научно-технической литературе, и оно означает: а) в системах хранения данных – рассматриваемая как единое целое часть диска, состоящая из фиксированного числа секторов, используемых операционной системой для чтения и записи данных; б) в высокопроизводительных многопроцессорных системах – способ объединения группы процессоров.
Disk has invalid cluster [Полякова, 1998, с. 99]. На диске имеется недействительный кластер [Полякова, 1998, с. 154].
Однако если речь не идёт о компьютерах, слово cluster имеет другие значения: 1) кисть, пучок, гроздь, куст; 2) совокупность особей, индивидуумов, предметов; 3) перен. скопление, концентрация;
Что касается различий в понятийном содержании описываемого пласта лексики, то в данном типе расхождений сказывается своеобразие классификаций явлений, свойств и отношений объективного мира, характерных для семантики каждого языка.
No room for system on destination disk [Полякова, 1998, с. 46]. Нет места для системных файлов на диске, на который ведётся копирование [Полякова, 1998, с. 50].
Немаловажную роль играют обычаи словоупотребления, иногда (но не всегда) связанные с расхождениями реалий. Особый интерес вызывают случаи употребления реалий в русском компьютерном сленге, например, блины – диски у винчестера и другие разновидности дисков; Емеля – адрес E-mail; самовар – программа, написанная по принципу Shareware.
Расхождения в эмоционально-оценочном значении могут проявляться в оценочных, эмоционально-экспрессивных окрасках. Важнейшей функцией компьютерного сленга является выражение эмоций, оценочного отношения, например, пренебрежительное бутявка – загрузочная дискета (от англ. boot – загрузка).
Многие английские термины в любом контексте соответствуют определённым русским терминам, и основная масса научно-технической терминологии не входит в состав общелитературного языка, оставаясь понятной лишь специалистам данной отрасли знания. Тем не менее, роль контекста чрезвычайно велика, так как значительное количество терминов – это общеупотребительные английские слова, взятые в специальном значении. Контекст помогает выявить следующее: а) употреблено ли слово в своём обычном значении или в специальном, б) в каком из своих значений употреблён многозначный термин в данном конкретном случае.
No target drive specified – Не указан дисковод, который ведёт запись [Полякова, 1998, с. 114].
Интернациональные слова, полностью не совпадающие по значению, называют «ложными друзьями переводчика». Эта группа интернациональной лексики представляет особую сложность в процессе осуществления межкультурной коммуникации. Слова такого типа имеют разные денотативные, дефинирующие, коннотативные значения и могут иметь разную стилистическую соотнесённость.
Компьютерная терминология не является исключением. Здесь встречаются такие термины, как data – данные, colon – двоеточие, fabric – инфраструктурный, invalid – дефектный, major – основной, Scheme – название языка программирования.
В теории и практике перевода оперируют такими сходными понятиями, как эквивалентность, адекватность и тождественность. В широком плане эквивалентность понимается как нечто равноценное, равнозначное чему-либо, адекватность – как нечто вполне равное, а тождество – как нечто обладающее полным совпадением, сходством с чем-либо.
В переводоведении нередко встречается тезис о том, что главным определяющим принципом эквивалентности текста является коммуникативно-функциональный признак, который складывается из равенства коммуникативного эффекта, производимого на реципиентов оригинального и переводного текстов. В идеале сам переводчик не должен привносить в текст сообщения элемент своего собственного восприятия, отличного от восприятия сообщения тем получателем, которому оно было адресовано.
«Перевод связного текста предполагает комплексное использование переводческих методов и приёмов с учётом того, что текст представляет собой единое целое в смысловом и структурном планах. Исходя из структуры и содержания текста, переводчик решает, следует ли использовать тот или иной приём и каким образом это лучше сделать. Особенности конкретного текста могут в той или иной степени модифицировать способ применения переводческого приёма или заставить переводчика отказаться от использования стандартных методов перевода и попытаться найти новый, ранее неиспользованный путь» [Комиссаров, 1997, c. 73].
При сравнении исходных текстов и их переводов было отмечено, что научно-технические тексты отличаются строгой ясностью изложения, чёткостью определений, лаконичностью форм. Они насыщены терминологической лексикой, которая даёт возможность наиболее точно, чётко и экономно излагать содержание данного предмета и обеспечить правильное понимание существа трактуемого вопроса. Тем не менее, несмотря на чёткость и ясность, нужно прибегать к различным лексическим и грамматическим трансформациям. Очень часто именно при переводе лексики возникают трудности, так как научно-технические тексты имеют свою специфику и не всегда понятны широкому кругу читателей. В данной работе рассматриваются лексические трансформации, используемые при переводе научно-технических текстов по компьютерной тематике.
Результаты исследования показали, что самым распространённым методом перевода терминов-лексем является калькирование, далее следует транскрибирование с элементами транслитерации. Нередко в процессе перевода транскрипция, транслитерация и калькирование используются одновременно: milimicrosecond – милимикросекунда, microprogramming – микропрограммирование, service program – сервисная программа.
Такие переводческие приёмы, как конкретизация, эквивалентный перевод используются реже: reader – считывающее устройство (конкретизация); Software program – компьютерная программа (перевод с помощью эквивалентов). И совсем редки случаи использования генерализации: Never leave the Walkman in the car parked in the sun. – Никогда не оставляйте аппарат в автомобиле, если он стоит на солнце.
Одним из доминирующих методов перевода терминов-словосочетаний (терминов-фразем) является перевод при помощи фразеологического эквивалента (artificial life – искусственная жизнь, computer out of law – компьютер преступник). Вторым доминирующим переводческим приёмом является фразеологический аналог: Address bus – адресная шина. Этот термин обозначает набор линий в системной шине, используемой для передачи сигналов, с помощью которой определяется ячейка памяти. Использование методов подбора фразеологического эквивалента и фразеологического аналога в 44 % случаев позволяет нам сделать вывод о том, что авторы словаря [Заморин, Марков, 1987] при выборе метода перевода исходили из основного требования перевода: «фразеологизм переводится фразеологизмом».
Значительное количество терминов переведено при помощи описательного метода перевода (Business-to-business – электронная коммерция по схеме «бизнес-бизнес» (предприятие – предприятие) – схема оптовой торговли, по которой осуществляются сделки через Интернет). Не менее популярен однословный метод перевода (follow-me-forwarding – переадресация). Термин описывает функцию перенаправления вызова на другой телефонный номер. Однословный перевод вполне обоснован, на наш взгляд, особенно в тех случаях, где описательные глагольные выражения лишены экспрессии и метафоричности.
Приём калькирования фразеологических единиц также популярен (Bare metal – «голое железо»). Термин подразумевает новые аппаратные средства компьютера или неподдержанные никаким программным обеспечением. Гораздо реже используется приём создания индивидуальных эквивалентов, например: lost in the noise – пренебрежимо малая величина. Кроме того, авторы использовали приём стилистического обновления фразы, например: back end – северная часть приложения; full backup – полное страховое копирование; open ended – не ограниченный временем.
Применяется также переводческий приём «просветление» фразы, например: add-on-card – плата расширения; multi-drop – многоабонентская линия; brief case computer – портативный компьютер.
Комбинированный метод перевода: hinged clam-shell construction – конструкция (квадратный ЭВМ), типа «складень»; hot-add – устанавливаемое на ходу (без остановки компьютера); low end PC – младшие (обычно недорогие модели ПК).
В главе 4 второго раздела (п. 2.4.3) предлагается описание опыта машинного перевода текста компьютерной направленности “Enterprise-Level Project Management from Microsoft” [Seymour, 2001, p. 85-86], выполненного электронным переводчиком PROMT XT Office. Во многих случаях перевод далёк от совершенства, однако можно понять, о чём идёт речь. Вполнее естественно, что перевод нуждается в постредактировании, под которым понимается использование переводческих приёмов.
Применение переводческих трансформаций для достижения функциональной эквивалентности при переводе терминологии обусловлено объективными и субъективными причинами. Разноструктурность английского и русского языков – объективный фактор. Наличие образной лексики и конструкций экспрессивного синтаксиса в научно-популярной литературе – субъективный фактор. Тем самым возрастает роль переводчика при передаче и донесении до читателей информации.
Отдельный пункт четвёртой главы второго раздела посвящён лингвистическим проблемам систем машинного перевода, к которым относятся: омоморфия, неоднозначность слов, лексические и структурные несоответствия, устойчивые словосочетания, идиомы, терминология, особенности словообразования. Здесь высказаны некоторые соображения по поводу алгоритмизации переводческого процесса, основанные на концепциях учёных, занимающихся данной проблемой [Брандес, Провоторов, 2001], [Васильева, 2004], [Nord, 1989], [Протасов, 2003], [Узуев, 2005]. Можно попытаться с помощью ЭВМ сделать анализ текста и выявить те его особенности, на основе которых переводчик определяет стилистическую окраску, выбирает лексические единицы из ряда синонимов, омонимов и т.д. Наиболее трудной задачей является разработка системы отнесённости лексем и словосочетаний к определённой области знания.
Предпереводческий анализ текста призван направить внимание переводчика на наиболее значимые моменты в коммуникативной и предметной ситуации исходного текста, а также на существенные характеристики самого текста.
Признание значимости данного этапа для перевода послужило основанием для разработки обучающих моделей анализа текста для людей-переводчиков. Основная задача этих моделей состоит в том, чтобы научить переводчика находить релевантные для перевода, качественно отличные характеристики исходного и целевого дискурсов, определять обусловленные этими различиями переводческие проблемы и намечать пути их преодоления, т. е. переводческие стратегии.
Проводя аналогию между работой человека-переводчика и системой машинного перевода, можно предположить, что предпереводческий анализ текста также имеет определенное значение и для системы МП. Если в случае с человеком анализ призван направить внимание переводчика на наиболее значимые моменты в коммуникативной и предметной ситуации исходного текста, его существенные характеристики, то для системы МП, очевидно, целью предварительного анализа будет определение некоторых параметров текста. Эти параметры выбираются в зависимости от используемой модели перевода, подготавливают текст к обработке (делают возможной работу алгоритмов МП), а также по возможности упрощают анализ текста.
Выбор последовательности изложения темы (т. е. композиции), отбор лексики, грамматических и риторических возможностей определяются не только общей целенаправленностью исходного текста и его жанровой принадлежностью, но и соблюдением тех норм, которые существуют для соответствующей разновидности текстов в языке перевода. Представляется возможным пойти по пути формализации. Алгоритм анализа текста может включать: определение функционального стиля текста, весовых коэффициентов, оценочной функции, учет форматирования переводимого текста в электронных документах.
Прежде чем компьютерная программа сможет выдавать приемлемый перевод, предстоит решить еще множество проблем, как лингвистических, так и проблем реализации на ЭВМ. Практически все существующие программные разработки имеют недостатки одной из этих областей. Учёт форматирования переводимого текста указывает на то, что помимо улучшения собственно алгоритмов перевода, существуют способы, больше связанные с технической стороной дела. Так как эффективность моделей, предложенных лингвистами, напрямую зависит от их реализации разработчиками программ, то, возможно, стоит уделять внимание тем технологиям, на основе которых создаются электронные переводчики и тексты, которые они обрабатывают.
Третий раздел диссертации посвящён компьютерной лексикографии. Представление терминологической лексики в сфере фиксации в отраслевых словарях всегда являлось одной из основных проблем в научно-технической лексикографии. Особую значимость эта проблема приобрела в последние годы для терминографов, создающих специальные словари разных типов в связи с всё возрастающим потоком научно-технической информации и в связи с необходимостью совершенствования систем передачи и обработки информации.
К современным специальным словарям, как к традиционным отраслевым, так и к словарям автоматизированных систем, имеющим разное назначение и решающим разные задачи, предъявляется общее требование: они должны адекватно и достаточно полно описывать функционирующую терминологию той или иной предметной области. Общепризнанным является тот факт, что для адекватного описания терминология должна быть представлена в словаре не как случайный набор зафиксированных в тексте терминов, но как терминологическая система, обладающая своей определённой, характерной для данной отрасли знания структурой.
Нельзя не согласиться с В.М. Лейчиком, который полагает, что «терминосистемой (терминологической системой) можно назвать только упорядоченную (кодифицированную) терминологическую лексику с явно выраженными и зафиксированными в словарях и классификационных схемах отношениями» [Лейчик, 1980, с. 39].
Понимая необходимость системного лексикографического описания научной терминологии, составители специальных словарей стараются использовать наиболее, на их взгляд, удобную и приемлемую методику в своей работе. Лексикографов подстерегает много трудностей, в частности, проблема расположения терминов в словаре таким образом, чтобы в нём была эксплицитно отображена терминосистема. Трудности обусловлены также одновременной принадлежностью термина к двум системам: к понятийной системе отрасли знания (в плане содержания) и к языковой системе (в плане выражения).
В современной лексикографии существуют три способа организации лексических единиц в словаре: 1) алфавитный, 2) алфавитно-гнездовой, 3) идеографический (или понятийно-семантический). Последний – представляется наиболее приемлемым. Идеографический способ расположения терминологических единиц даёт возможность показать системные отношения в подъязыке какой-либо специальности, логико-понятийную структуру терминологии, а через неё – систему понятий данной конкретной области знания и их классификационные (иерархические) связи. Метод экспертного анализа, заключающийся в обязательном участии специалистов данной области знания в построении логико-понятийной схемы, помогает с достаточной степенью точности и объективности отразить логический строй науки и перспективные направления её развития.
В конце 1980-х гг. начали издавать словари компьютерной терминологии в нашей стране. В Америке они появились гораздо раньше. Например, IBM Dictionary of Computing под ред. Джорджа МакДаниэла [1994] пережил 10-е издание в августе 1994 г., т. е. около 20 лет после того, как он был издан впервые. Краткий анализ терминологических словарей по информатике и вычислительной технике, предложенный во втором разделе (п. 3.1.3) содержит неполный их перечень. Рассматривались только некоторые словари, предназначенные для широкого круга пользователей ЭВМ. Однако даже такой поверхностный анализ позволяет сделать вывод о том, что в основном составители словарей пользуются алфавитным или алфавитно-гнездовым способом составления словарей. Тезаурусный метод всё-таки остаётся ещё на периферии лексикографической практики. И это понятно, так как он требует очень тесного сотрудничества специалистов предметной области и лингвистов.
Для успешной реализации современных требований лексикографы прибегают к помощи математической и лексической символик, аппарата лексических и логико-семантических функций. Интересным с лингвистической точки зрения вопросом является вопрос о близости функций тезауруса к лексическим функциям в модели «СмыслТекст». Как и стандартные ЛФ, тезаурусные связи выделяются только тогда, когда данное отношение устанавливается между многими парами слов. Однако основой для введения в тезаурус логико-семантических связей служит выделение отношений между понятиями, т. е. понятийная сочетаемость, которая может выражаться лексически свободными словосочетаниями. ЛФ же отражают, главным образом, несвободную лексическую сочетаемость и обусловлены требованиями синтаксического перифразирования, по которым могут выделяться функции, лишённые семантики (например, Oper ?). К тому же каждая научная терминология имеет свой набор связей, тогда как ЛФ вырабатывются для всей лексики в целом [Никитина, 1978, с. 48].
Важную роль играет моделирование, предполагающее алгоритмическую реализацию. Использование математических методов в лексикографии подтверждает наличие межпредметных связей: математика - информатика – филология. Лингвистика стремится к формализации языка.
Принципиально важным является тот факт, что с точки зрения лексики любой информационно-поисковый язык (ИПЯ) – язык терминологический: элементами такого информационного языка являются термины естественного языка, выражающие информацию о тематическом содержании документов. «Если тематическое содержание статьи, главы в книге, технического отчёта, управленческого документа обозначить набором информативных для этого документа терминов, т. е. таких терминов, которые выражают темы и подтемы, получим терминологическую аннотацию документа, чтение которой даст специалисту возможность предварительно решать, следует ли ему знакомиться с этим документом» [Головин, Кобрин, 1987, с. 41].
Одной из основных задач терминоведения является правильное научно обоснованное составление терминологической аннотации с учётом синонимических, омонимических, родо-видовых, ассоциативных связей, связей по признаку «часть – целое», «объект – признак» и т. д. Это позволяет оптимально организовать работу информационной системы.
Интеллектуальные системы обработки информации с использованием ЭВМ имеют в качестве двух составляющих лингвистическое и математическое обеспечение. Одна из сторон лингвистического обеспечения – это создание электронных словарей. Всю совокупность электронных словарей можно подразделить по следующим критериям [Богданов, 2002]:
1. По используемой операционной системе. Наиболее простые электронные словари (DIC) работают под управлением OC MS-DOS, начиная с версий 2.21 и 3.30, что позволяет их использовать практически на любых IBM-совместимых персональных компьютерах, включая ХТ, АТ-286. Наиболее сложные многооконные и многофункциональные электронные словари (ЭС), позволяющие в одной оболочке подключать различные тематические базы данных, работают под управлением OC WINDOWS 3.11, WINDOWS NT, WINDOWS 95 и т. д. Естественно, что для их успешного функционирования необходим более мощный компьютер (типа АТ-486DX) с оперативной памятью не менее 8 МБ.
2. По способу загрузки. ЭС можно подразделить на нерезидентные и резидентные. К первым относятся простейшие программы (например, подстрочечный словарь DIC), которые работают только в собственной среде и не вызываются из других оболочек, например из текстовых редакторов. В большинстве случаев они функционируют в режиме автоматического (пакетного) перевода. Вторые загружают своё ядро в оперативную память компьютера (например, LINGVO for DOS) и могут быть вызваны в любой момент работы компьютера, из любого текстового редактора при помощи нажатия комбинации горячих клавиш – клавиш оперативного вызова. Эти словари обеспечивают работу переводчика в интерактивном режиме.
3. По количеству подключаемых словарных баз (словарей). Ранние версии ЭС позволяли подключать только один словарь. Современные программы, например Система электронных словарей LINGVO, независимо от того, в какой ОС они работают, позволяют подключать до нескольких десятков словарных баз и устанавливать приоритет последних.
4. По возможностям расширения словарной базы. Устаревшие ЭС не имели возможности расширения словарных баз пользователем. Современные версии, например LINGVO 4.6, имеют утилиты для создания пользователем собственных и расширения существующих словарей.
5. По режиму перевода. Можно выделить два основных режима перевода: автоматический пакетный (подстрочечный) и интерактивный (режим «запрос – ответ»).
Наиболее популярными в настоящее время на рынке словарной продукции являются такие электронные словари, как Лингво, Полиглоссум, Мультилекс и Контекст. Основываясь на вышеприведённой классификации, а также принимая во внимание общие и отличительные особенности электронных и бумажных словарей, целесообразно выделить следующие критерии для проведения сопоставительного анализа ЭС:
* принцип морфологичности,
* удобство и полнота содержания словарной статьи,
* режим поиска,
* возможность двухстороннего перевода,
* возможность перевода словосочетаний и предложений,
* возможность подключения и выбора приоритетности словарей,
* возможность создания собственных словарей,
* удобство пользования интерфейсом,
* качество и полнота лексической базы,
* основные категории пользователей,
* объем словарей,
* наличие дополнительных справочников (грамматических, фонетических и др.).
В ходе проведённого исследования удалось выявить преимущества и недостатки вышеназванных электронных словарей. Сопоставительный анализ ЭС позволяет прийти к выводу: все представленные словари отвечают данным критериям в той или иной степени.
Основными преимуществами словаря Lingvo являются следующие: уникальный грамматический справочник, фонетическая программа, наличие парадигмы практически для всех слов, что делает возможным перевод не только словосочетаний, но и целых предложений. Главным недостатком можно назвать недостаточно высокое качество лексической базы.
Polyglossum включает наибольшее количество специализированных словарей, занимает минимум места на жестком диске и совместим со всеми версиями операционной системы Windows. Одновременно с этим он является наименее удобным в представлении информации (отсутствует наглядность).
МультиЛекс является точной копией авторитетных бумажных изданий, что гарантирует его качество. К достоинствам словаря можно отнести наличие транскрипции, проставленное в русских и английских словах ударение, стилевые пометы и подробную разработку значений. Необходимо отметить тот факт, что МультиЛекс заметно дороже других программ.
Основными достоинствами Контекста, с точки зрения перевода, можно считать достаточно большой набор тематических словарей, поиск словосочетаний в любой форме и возможность показать список переводов всех фраз с интересующим словом в словаре. Однако отсутствие в Контексте синонимов и антонимов, а также неозвученность можно рассматривать как его недостатки.
К сожалению, ЭС несовершенны из-за отсутствия в них человеко-ориентированной информации. Главной проблемой является рассеяние сведений и функций в различных словарях. Решение проблемы видится в создании единого универсального ЭС, объединяющего все наличествующие типы лингвистической информации о каждом отдельном слове. Он обеспечит разнообразие способов доступа к информации как для других программных средств, так и для человека-пользователя. Мощные поисковые возможности позволят использовать его как универсальный источник сведений для решения задач перевода, обработки текстов, обучения языку и т. п.
Все описанные словари в большой степени универсальны, но вместе с тем каждый из них тяготеет к определённой нише. Большая часть усилий издателей коммерческих электронных словарей сфокусирована на английском языке, получившем широкое распространение в России, в том числе с косвенной государственной поддержкой. В меньшей степени популярен немецкий язык, а вот выбор словарей испанского, итальянского и даже французского языков можно назвать скудным. Огромной редкостью у нас оказываются электронные переводные словари языков восточной Европы и остального мира.
Вполне естественно, что разработчикам ещё есть над чем потрудиться: подлежат совершенствованию системы морфологического анализа слов, словарные базы, необходимо пополнять программы новыми словарями специализированных терминов.
Общие выводы
Результаты исследований позволяют прийти к следующим выводам:
1). Терминология информатики развивается в сторону интернационализации. Данное обстоятельство обусловливает экстралингвистические процессы, имеющие место в компьютерной терминологии: межпредметные связи и интерференцию (внутриязыковую, межъязыковую и тематическую). В свою очередь, тематическая интерференция обусловлена межпредметными связями.
2). Средства номинации компьютерных терминов универсальны и кодифицированы: термины-слова, термины-словосочетания и символо-слова. Классификация терминов-слов осуществляется в соответствии с морфемной структурой слова: а) непроизводные, б) производные, в) сложные. Термины-словосочетания образованы по определённым моделям. В работе выделено семь типов моделей с многокомпонентной структурой. Способы терминологической номинации также универсальны: а) семантический способ, б) аффиксация, в) словосложение, г) аббревиация, д) заимствования.
3). Предметная область информатики содержит понятия, номинируемые в основном терминами-словами и терминами-словосочетаниями. По мере возможности все понятия интерпретируются в справочной литературе. Патентная литература, различные периодические и непериодические издания предназначены для обмена научно-технической информацией. По этой причине возникает необходимость перевода с одного языка на другой. При переводе с английского языка на русский рекомендуется использование трансформационных методов с целью достижения эквивалентности перевода подлиннику. Анализ переводов показал, что наиболее популярны такие переводческие приёмы как транскрибирование с элементами транслитерации, калькирование, конкретизация, генерализация, перевод с помощью эквивалентов и аналогов. Это касается терминов-слов. В отношении терминов-словосочетаний практикуются несколько иные способы перевода, в частности, перевод при помощи фразеологической эквивалентности, фразеологического аналога, описательный метод, однословный метод перевода, калькирование, приём создания индивидуальных эквивалентов, приём стилистического обновления, приём «просветления» фразы и комбинированный метод перевода.
4). Для обеспечения эквивалентности перевода подлиннику представляется возможным пойти по пути формализации, в частности, создания алгоритма предпереводческого анализа. Алгоритм анализа может включать: определение функционального стиля переводимого текста, его весовых коэффициентов, оценочной функции, а также учёт форматирования в электронных документах. Формализация предпереводческого анализа может иметь значение как для человека-переводчика, так и для систем машинного перевода.
5). Семантические процессы, имеющие место в компьютерной терминологии (полисемия, омонимия, синонимия, антонимия, гипонимия), указывают на семантическое единство терминологии, её системный характер. Системность терминологии тесно связана с системностью знания.
6). Термины информатики, как и любой другой области знаний, представляется возможным классифицировать по тематическому принципу (имеется в виду распределение терминов по тематическим группам). В данной работе в основу классификации положены разделы базового курса информатики. Такой принцип классификации терминов с привлечением аппарата логико-семантических признаков (функций) может найти применение в терминографии при составлении идеографических словарей. Моделирование и алгоритмизация языковых процессов в терминографии способствует более полному отражению предметной области.
Результаты проведённого исследования подтверждают основную гипотезу диссертации: терминологическая система информатики представляет собой функционально-семантическое единство, элементы которого взаимосвязаны и взаимообусловлены. Единый аппарат логико-семантических функций для собственно-терминологического и лексикографического аспектов свидетельствует о параллелизме функционирования компьютерной терминологии. Данный аппарат включает следующие логико-семантические функции: объект, назначение/функция, инструментальность, действие/процесс, адресность/фамильность, идентификатор, счисление/система счисления, устойчивость, квантитативность, сходство. При описании внутренней структуры термина (имеется в виду собственно-терминологический аспект) выделены вышеназванные логико-семантические функции (табл. 2, 3, 4, 5, 6, 7 в диссертации). В свою очередь, в Приложении к диссертации представлен фрагмент тезауруса по программированию, который содержит тот же аппарат логико-семантических функций.
Здесь намечена перспектива составления тезауруса, включающего все тематические разделы курса информатики, более того, любой области знания, возможно, с некоторыми модификациями с учётом специфики предметной области. Отсюда следует, что функционирование терминологий, их системная организация оказываются в центре внимания теории языка.
Основные положения работы отражены в следующих публикациях:
1. Использование компьютерных программ в обучении английским предлогам // Информационные технологии в образовании. Сборник научных трудов. Вып. 3. / Отв. ред. М.П. Лапчик. – Омск: Изд-во ОмГПУ, 1999. – С. 14-17.
2. Межпредметные связи в развитии сравнительного и международного образования: филология и информатика // Международные отношения в развитии социально-экономических процессов в странах СНГ. Материалы Международной научно-практической конференции 14-15 июня 2001 г. – Омск: Изд-во ОмГПУ, 2001. - С. 276-277.