

Системный анализ, онтологический синтез и инструментальные средства обработки информации в процессах интеграции профессиональных знаний
На правах рукописи
МИНАКОВ Игорь Александрович
Системный анализ, онтологический синтез
и инструментальные средства обработки информации
в процессах интеграции профессиональных знаний
Специальность 05.13.01 – Системный анализ, управление
и обработка информации (промышленность)
А в т о р е ф е р а т
диссертации на соискание ученой степени
доктора технических наук
Самара – 2007
Работа выполнена в лаборатории анализа и моделирования сложных систем Института проблем управления сложными системами РАН (г. Самара).
Научный консультант: доктор технических наук, профессор
Виттих Владимир Андреевич
Официальные оппоненты:
Заслуженный деятель науки РФ, Дилигенский
доктор технических наук, профессор Николай Владимирович
Лауреат Ленинской премии, Соллогуб
Заслуженный деятель науки и техники РФ, Анатолий Владимирович
доктор технических наук, профессор
Заслуженный деятель науки и техники РФ, Ильясов
член-корреспондент АН РБ, Барый Галеевич
доктор технических наук, профессор
Ведущая организация:
Санкт-Петербургский институт информатики и автоматизации РАН
(г. Санкт-Петербург)
Защита состоится 3 декабря 2007 г. в 10 часов на заседании диссертационного совета Д 212.217.03 ГОУ ВПО «Самарский государственный технический университет» по адресу г. Самара, ул. Галактионовская, 141, корпуса № 6, аудитория 28.
С диссертацией можно ознакомиться в библиотеке ГОУ ВПО «Самарский государственный технический университет» по адресу: ул. Первомайская, 18.
Отзывы на автореферат в 2 экземплярах просим высылать по адресу: 443100, г. Самара-100, ул. Молодогвардейская, 244, ГОУ ВПО «Самарский государственный технический университет», главный корпус на имя ученого секретаря диссертационного совета.
Автореферат разослан «____» _____________ 2007 г.
Ученый секретарь
диссертационного совета Д 212.217.03 Губанов Н.Г.
ОБЩАЯ ХАРАКТЕРИСТИКА ДИССЕРТАЦИИ
Актуальность темы. В современном информационном обществе возникает острая необходимость в методах и средствах, ориентированных на обработку и анализ семантики доступных информационных материалов, для решения таких задач, как поддержка принятия решений при промышленном проектировании (например, образцов новой техники), классификация научно-технической документации, интеграция информационных служб промышленных компаний-партнеров.
В процессе решения подобных задач эксперт - лицо, принимающее решение, осуществляет интеграцию знаний, в рамках которой анализируются и систематизируются разнородные информационные материалы, произведенные другими исследователями, с целью получения знаний об изучаемом объекте, для чего обрабатываются различные электронные ресурсы: проектно-конструкторская документация, статьи научно-технических библиотек, промышленные и бизнес новости, страницы профессионально-ориентированных Интернет-порталов, онлайн-конференции, форумы, блоги.
К сожалению, существующие инструментальные средства обладают рядом ограничений, которые существенно уменьшают область и эффективность их практического применения. Это связано с тем, что имеющиеся поисковые системы и системы документооборота, при наличии множества методов для работы с текстом документов (анализ ключевых слов, морфология, грамматика, шаблоны, таксономия и пр.), практически не способны работать со смыслом текста, не анализируя знания, представленные в текстовой форме, что и является главной неразрешенной проблемой анализа.
В то же время в практических задачах все чаще экспертов не устраивает единый стандартизованный механизм поиска и анализа, доступный на сегодняшний день для обработки электронных документов. Возникает необходимость индивидуализировать процесс анализа, сделав его субъектно-ориентированным, принимая во внимание знания и цели самого эксперта.
Особенно востребована подобного рода задача в научно-промышленных исследованиях при работе с профессиональными знаниями, которые отличает целевая направленность документа, узкоспециализированная предметная область, сжатость и информативность текста.
Для решения задачи интеграции профессиональных знаний необходимы возможность представлять имеющуюся текстовую информацию в формализованном виде, механизмы поиска и сравнения семантики документов, возможность классификации согласно содержащимся в них знаниях, интерактивное взаимодействие с экспертом при построении модели предметной области, и даже механизмы автоматизированного уточнения модели на основе результатов анализа.
В области теории и практики работы со знаниями с помощью вычислительной техники накоплен значительный положительный опыт. Вопросы построения содержательных онтологий для моделирования реальности отражены в трудах отечественных ученых Т.А. Гавриловой, В.В. Девяткова, Г.Б. Евгенева, Г.С. Поспелова, Д.А. Поспелова, В.Ш. Рубашкина, В.А. Виттиха, А.В. Смирнова, С.В. Смирнова, В.Ф. Хорошевского, Г.П. Щедровицкого, а также многих зарубежных специалистов: T.R. Gruber, N. Guarino, J.F. Sowa, M. Uschold, B.J. Wielinga и др.
К работам, характеризующим предысторию развития, современное состояние и тенденции в области обработки естественно-языковых текстов можно отнести фундаментальные исследования Т. Винограда, Н. Хомского, Р. Шенка, В. Гумбгольдта, Ч. Филлмора и др.
Среди российских работ можно выделить труды Ю.Д. Апресяна, Б.Ю. Городецкого, Ю.А. Загорулько, Н.Н. Леонтьевой, Н.В. Лукашевич, М.Г. Мальковского, И.А. Мельчука, А.С. Нариньяни, Г.С. Осипова, Э.В. Попова, В.А. Тузова, С.Д. Шелова и др.
В области кластеризации данных – труды И.З. Батыршина, Ж. Бола, В.Н. Вагина, Б. Дюрана, В.И. Городецкого, Н.Г. Загоруйко, Дж. Вэн Райзина, R. Agrawal, A. Maedche и др.
Необходимо также отметить, что данная диссертационная работа базируется на работах В.А. Виттиха, сформулировавшего принципы онтологического анализа и синтеза, применяемые в процессе познания, и П.О. Скобелева, выработавшего принципы создания открытых мультиагентных систем для поддержки процессов принятия решения в сложных системах.
Но, несмотря на актуальность методов по работе со знаниями и обработке текстов на естественном языке, нужно отметить, что известные публикации в большинстве своем носят либо концептуальный характер и не предлагают конструктивных подходов, либо относятся к частным методам (например, построение тезаурусов, работа с шаблонами, кластеризация числовых полей и др.).
В то же время с точки зрения инструментальных средств ситуация значительно хуже. Не только не существует единой инструментальной среды, обеспечивающей все шаги процесса интеграции и приобретения знаний, но и имеющиеся системы, ориентированные на решение подзадач, обладают целым рядом ограничений, существенно уменьшающих эффективность их практического использования.
Рассматривались такие алгоритмы и системы, как ASUIM, Chameleon, ConExt, DOE, KEA, LTG, OntoLearn, Promethee, SIMER+MIR, SOAT, SubWordNet, SVETLAN, TFIDF, TERMINAE, Welkin для задач автоматизированного построения/поддержки онтологий, HPSG, SFG, LFG, SAM, ПОЭТ, ИВОС, InterBase, KRITON, ТАКТ, DocMiner, Enkata, Intellexer, Inxight, Ontos, Text Analyst, SAS Text Miner, Clearforest, dtSearch, TEMIS, VantagePoint – для анализа текстов на естественном языке, LSA/LSI, STC, Bayesian>
К сожалению, для каждой группы программных систем можно выделить ряд принципиальных недостатков, включая необходимость существенной ручной предобработки данных человеком-экспертом; невозможность анализа всего набора текстов с точки зрения семантики предметной области; зависимость качества результатов от языка документов; отсутствие открытой модели предметной области, позволяющей в полной мере использовать знания эксперта и пополнять ее в процессе работы; ограниченность работы с семантическими сетями; непрозрачность и неинтерактивность алгоритмов; критичность к наличию «мусорной информации»; зависимость качества результатов от изначальной предпосылки – догадки о «правильной структуре»; нетерпимость к наличию неполной или противоречивой информации.
Поэтому задача интеграции знаний по-прежнему является актуальной, и разработка инструментальной системы для интеграции профессиональных научно-технических знаний, представленных на естественном языке, представляется важной задачей для данной диссертационной работы.
Предмет исследования составляют процессы обработки информации, направленные на интеграцию научно-технических знаний.
Цель исследования состоит в разработке теоретических основ и инструментальных программных средств для решения проблемы интеграции научно-технических профессиональных знаний, представленных в виде текстов на естественном языке, в сфере промышленного проектирования и производства.
Для достижения поставленной цели в работе решаются следующие задачи:
- Построить обобщенную логическую модель приобретения научно-технических знаний, позволяющую формализовать и применять знания эксперта с учетом промышленной и производственной специфики; разработать принципы онтологического подхода, позволяющего реализовать все этапы процесса приобретения и интеграции знаний в рамках единой методологии и концептуальной модели (онтологии).
- Разработать метод автоматизированного конструирования начальной онтологии предметной области.
- Разработать метод понимания научно-технических текстов на естественном языке в виде преобразования электронных текстовых документов в семантическую сеть в терминах онтологии предметной области с целью представления семантики документа.
- Разработать методы получения, анализа и обработки научно-технической информации, представленной в виде семантической сети, в том числе механизмы сравнения, поиска, структурирования и классификации с помощью кластерного анализа.
- Разработать метод самокоррекции и саморегуляции системы путем автоматизированного уточнения и пополнения знаний, представленных в терминах онтологии.
- Разработать архитектуру системы и программно-инструментальную среду для работы со знанием, реализующую предложенные методы.
- Выработать критерии оценки и провести исследование параметров и качественных характеристик разработанных методов и средств работы со знаниями, выработать рекомендаций по их применению.
- Оценить эффективность предложенных методов и средств при решении ряда практических задач в сфере промышленного проектирования и производства, и других применениях.
Методы исследования. Использованы теория и методы системного анализа, компьютерной лингвистики, эпистемологии, теории кластерного анализа, методы конструирования онтологий, теории графов, математической статистики, проектирования систем баз данных и знаний, структурного и объектно-ориентированного проектирования и программирования.
Научная новизна выполненных исследований заключается в развитии теоретических основ построения систем извлечения знаний и обработки неструктурированной информации на естественном языке:
- Новизна предложенного онтологического подхода к решению задачи интеграции профессиональных научно-технических знаний состоит в использовании единой методологии, основанной на концептуальной модели эксперта, для реализации всех шагов цикла приобретения и интеграции знаний, что обеспечивает индивидуализацию процесса и учет целей эксперта.
- Новизна предложенного метода автоматизированного построения онтологии предметной области заключается в итеративном анализе строящейся онтологии с помощью предложенного мультиагентного метода понимания текстов на естественном языке с применением базовой онтологии языка и набора предметно-ориентированных текстов, что обеспечивает механизмы самокоррекции и саморегуляции в процессе построения начальной онтологии предметной области.
- Новизна предложенного метода преобразования неструктурированной информации на естественном языке в семантическую сеть в терминах онтологии предметной области заключается в применении механизмов агентного взаимодействия квантов знаний, позволяющих реконструировать смысл предложения и всего документа, что дает возможность представлять смысл научно-технического текста в виде семантических сетей, обеспечивает механизмы уточнения семантики в режиме реального времени по мере поступления новой информации и предоставляет механизмы сравнения семантики связных профессиональных текстов.
- Новизна предложенного метода кластерного анализа состоит в реализации его на основе агентных механизмов переговоров, что обеспечивает механизмы динамической иерархии групп семантически схожих объектов как в пакетном режиме так и в режиме реального времени, а также дает возможность работы с неструктурированными квантами информации, представленными в виде семантических сетей.
- Новизна метода автоматизированного пополнения онтологии состоит в использовании мультиагентного кластерного анализа групп семантически схожих документов для выявления закономерностей, позволяющих уточнять онтологию предметной области, улучшая качество представления, поиска и анализа документов.
- Новым является предложенная архитектура инструментальной среды онтологического анализа и синтеза, основанная на субъектно-ориентированной модели приобретения знания с применением агентных взаимодействий, и заключающаяся в совместном использовании агентных механизмов работы со знанием на естественном языке и мультиагентного кластерного анализа, что обеспечивает полный цикл приобретения и интеграции знаний, необходимый для эффективного и оперативного использования научно-технической информации.
Практическая значимость. Научные результаты работы явились основой создания инструментальной среды онтологического анализа и синтеза, включающей подсистемы формирования, накопления, использования, анализа и пополнения разнородных знаний, необходимые для решения прикладных задач в сфере промышленного производства; предложены адекватные этим целям инструментальные программные средства.
Созданные программные инструментальные средства для реализации методов автоматизированного конструирования онтологий, обработки и представления информации, анализа результатов и пополнения знаний применяются в задачах мониторинга проектно-конструкторской информации в Интернет, логистики, поисковых и метапоисковых системах, системах классификации документооборота, онлайн-анализа и других применениях, поскольку использование созданного инструментария повышает скорость анализа и обработки информации, сокращает стоимость и сроки работ, увеличивает производительность и функциональность используемых систем.
Разработанные инструментальные средства имеют открытую архитектуру, гибкие механизмы импорта\экспорта, прозрачную процедуру настройки на любую предметную область посредством адаптации онтологии без необходимости изменения программного кода, что делает систему доступной экспертам предметных областей и открывает широкие перспективы как интеграции разработанных программных средств с имеющимся инструментарием, так и использования системы в тех научно-технических задачах, где актуальна проблема эффективного и оперативного анализа и приобретения научно-технических знаний, представленных в виде текстов на естественном языке.
Реализация работы. Результаты диссертационной работы нашли применение при выполнении научно-исследовательских работ:
- по Комплексной программе фундаментальных исследований РАН по проблемам машиностроения, механики и процессов управления 2004-2006 гг. (раздел VI, тема «Онтологический анализ и синтез в процессах принятия решений», гос. рег. № 0120.0403300);
- по Комплексной программе фундаментальных исследований РАН по проблемам машиностроения, механики и процессов управления 2000-2003 гг. (раздел III «Управление и автоматизация», тема «Разработка основ теории управления сложными открытыми системами с применением компьютерного представления и обработки знаний», гос. рег. № 0120.0110152);
- по Комплексной программе фундаментальных исследований РАН по проблемам машиностроения, механики и процессов управления 1996-2000 гг. (п. 3.1.2 «Разработка моделей управляемых процессов, методов прогнозирования экономической эффективности и социальных последствий», тема «Разработка методов и средств построения теорий артефактов для компьютерной интеграции знаний и автоматической генерации моделей объектов управления», гос. рег. № 01.9.60002398).
Прикладные разработки, связанные с проведением онтологического анализа и онтологического синтеза систем и созданием предметно-ориентированных пакетов прикладных программ выполнялись как в рамках перечисленных научных программ, так и по договорам с предприятиями на проведение НИОКР:
- с ФГУП ГНПРКЦ «ЦСКБ-ПРОГРЕСС» по созданию системы интеллектуального метапоиска в сети Интернет для оперативного нахождения и мониторинга релевантной информации в области малых космических аппаратов (2007г.);
- с ООО «Научно-производственная компания «Маджента Девелопмент», г. Самара (1999-2007 гг.), при разработке систем извлечения знаний и понимания текстов на естественном языке;
По результатам разработок подготовлен учебный курс «Мультиагентные системы», включающий цикл методических пособий и лабораторных работ, внедренный в учебный процесс в Самарском государственном аэрокосмическом университете и Поволжской государственной академии информатики и телекоммуникаций.
Апробация. Основные положения и результаты работы докладывались и обсуждались на международных и национальных конференциях и семинарах, в том числе: I-IX-ой Международных конференциях по проблемам управления и моделирования сложных систем (Самара, 1999 – 2007), 2-м Международном семинаре «Автономные интеллектуальные системы: извлечение знаний из данных и интеллектуальные агенты» (AIS-ADM 07, Санкт-Петербург), 6-й Международной конференции по телекоммуникациям и информатике (WSEAS TELE_INFO ’07 Даллас, США), 5-й Международной объединенной конференции по автономным агентам и мультиагентным системам (AAMAS-06, Хакодате, Япония), 1-й Международной конференции «Бизнес: информация, организация и менеджмент» (BIOPoM 2006, Лондон, Великобритания), Международной научной конференции «Интеллектуальные системы принятия решений и прикладные аспекты информационных технологий» (ISDMIT'2005, Херсон), Международной конференции «ИТ в бизнесе» (ITIB2005, Санкт-Петербург), Международной конференции по развитию инфраструктуры электронного бизнеса, науки, образования и медицины в Интернет (Аквила, Италия, 2002), 3-м Международном семинаре по новым информационным технологиям (CSIT’2001, Уфа), VII Национальной конференции по искусственному интеллекту (Переславль-Залесский, 2000).
Публикации. По теме диссертации опубликовано самостоятельно и в соавторстве свыше 50 работ, в том числе в перечне, рекомендованном ВАК – 13; а также 3 авторских свидетельства об официальной регистрации программ для ЭВМ. Опубликованные материалы отражают основное содержание диссертации.
Структура и объем работы. Диссертация состоит из введения, пяти разделов, заключения, приложений и списка использованных источников, содержащего 256 наименований. Основная часть работы содержит 332 страницы, включая 111 рисунков и 13 таблиц.
На защиту выносятся следующие положения:
- Онтологический подход в процессах обработки информации в сфере промышленного проектирования и производства, направленный на интеграцию научно-технических знаний, представленных в виде текстов на естественном языке, и использующий субъектно-ориентированную модель приобретения знаний.
- Метод автоматизированного построения начальной онтологии, основанный на ее итеративном анализе с помощью предложенного мультиагентного метода понимания текстов на естественном языке с применением базовой онтологии языка и набора предметно-ориентированных текстов.
- Метод понимания научно-технических текстов на естественном языке, заключающийся в преобразовании электронных текстовых документов в семантическую сеть с помощью агентных переговоров на основе построенных онтологий предметных областей.
- Метод кластеризации информационных объектов на основе агентных механизмов переговоров.
- Метод машинного обучения системы в форме автоматизированного пополнения онтологии новыми знаниями на основе зависимостей, найденных в процессе анализа выявленных групп кластеров.
- Архитектура инструментальной среды онтологического анализа и синтеза.
- Результаты практического применения предлагаемых методов и средств в сфере промышленного проектирования и производства.
СОДЕРЖАНИЕ ДИССЕРТАЦИИ
Во Введении показана актуальность темы диссертации, дан анализ исследуемой проблемы и обоснован применяемый подход к ее решению, определены цели и задачи исследования, охарактеризована научная новизна и практическая значимость результатов, проведен краткий обзор структуры и содержания диссертации, выделены основные положения, выносимые на защиту.
В первом разделе формулируется задача получения знаний об объекте путем анализа существующих информационных материалов, предлагается онтологический подход к решению задачи интеграции знаний, использующий субъектно-ориентированную модель приобретения знаний, что позволяет индивидуализировать процесс получения и анализа научно-технических знаний.
В теории и практике научного познания задаче анализа информационных материалов с целью предоставления эксперту знаний об объекте исследования, к сожалению, посвящено крайне мало работ. Кроме того, до последнего времени не существовало возможностей автоматизировать процесс анализа подобных документов, в первую очередь за неимением подходящих технических средств поддержки.
Особенностью подобного рода исследований является то, что результат ориентирован на конкретного эксперта, и процесс поиска и анализа материалов в общем случае должен им управляться. Результатом анализа становится проекция имеющейся информации на субъективные нужды и интересы, т.е. из одного и того же набора информационных материалов каждый эксперт извлекает свой индивидуальный набор знаний, преломляя имеющиеся материалы через призму собственной модели мира и знаний о предметной области (Рисунок 1).
Знания, исследуемые в данной модели, являются совокупностью проекций моделей \ знаний других исследователей, и по определению будут неформализованными, неполными и противоречивыми. Тем не менее, эти знания необходимо донести до эксперта, т.к. для анализа ему могут потребоваться работы, совпадающие или противоречащие его концепции, что позволит ему лучше осуществить собственное исследование.
При этом специфика таких знаний состоит, если следовать традиционной терминологии эпистемологии, в том, что работа происходит со знаниями, основанными на понимании. Основное отличие их от более распространенных в научных трудах знаний, основанных на объяснении, в том, что, если объяснение сводится к логическому выводу факта из закона или теории, то понимание связано с раскрытием смысла факта, его интерпретации. Этим и объясняется отсутствие формального аппарата для работы с подобным, неформализованным знанием, и данная работа является одним из первых шагов на пути разработки методов и инструментов для работы с подобным знанием.
Попытки формализовать макроструктуру познавательной деятельности предпринимались многими выдающимися учеными и философами, в том числе
 |
| Рисунок 1 – Субъектно-ориентированная модель приобретения знаний |
 |
| Рисунок 2 – Логическая модель цикла приобретения и интеграции знаний |
можно отметить работы И.Канта, Г.В.Ф. Гегеля, Р.Декарта, К.Поппера, С.Н. и Е.Н. Трубецких, В.И. Вернадского, Т. Куна, Г.П. Щедровицкого.
Из множества имеющихся схем процесса приобретения знаний была выбрана и обобщена схема познавательной деятельности, ориентированная на процесс приобретения знаний, основанных на понимании (Рисунок 2). Эта схема и легла в основу разрабатываемого инструмента.
Таким образом, в цикле приобретения и интеграции знаний можно выделить четыре основных этапа.
1. Осмысление/Абстрагирование – на основе общих знаний о мире и некоторых начальных неформализованных знаний о предмете исследования эксперт пытается построить некоторую структурированную (формализованную) модель знаний (этап абстрагирования), описывающих предмет, используя при этом ряд информационных материалов. Эта модель знаний называется онтологией. В работе сформулированы требования, которые к ней предъявляются (в том числе возможность представления неточной и неполной информации, прозрачность, расширяемость и др.), и выбрана т.н. «модель Аристотеля», которая отвечает всем требованиям и используется как базис для работы со знанием.
2. Восприятие/Отражение – построенная модель знаний используется для представления всех имеющихся информационных материалов в терминах данной модели. На основе предварительно понятой модели знания реконструируется реальный мир путем проекции его на субъектное восприятие мира в терминах модели знания. Здесь каждому информационному ресурсу ставится в соответствие его образ, формализованный в терминах модели знаний.
3. Применение/Верификация – осуществляется проверка качества проведенной проекции – насколько полно описаны имеющиеся информационные ресурсы, насколько точно модель позволяет искать, сравнивать и структурировать материалы, является ли представление тождественным в том смысле, что семантически близкие образы документов отображают реальную семантическую схожесть самих документов.
4. Переосмысление/Пополнение – на данном этапе происходит анализ возможных ошибок и неточностей предыдущего этапа и изменение модели знаний на основе найденных неточностей этапов восприятия и применения. Итогом данного этапа будет перестроенная или пополненная модель знаний, которая позволит точнее сформулировать знания о мире, тем самым полнее понимать его и взаимодействовать с ним.
Для решения задачи интеграции профессиональных научно-технических знаний с целью индивидуализации процесса приобретения знаний в данной работе предлагается инструментальная среда онтологического анализа и синтеза, ориентированная на решение задачи эффективного и оперативного получения и обработки знаний об изучаемом объекте. Данная среда получила название СИНТЕЗ (Система ИНТеграции Знаний).
В ней, согласно схеме приобретения знаний, каждому блоку цикла познания ставится в соответствие программный модуль, реализующий познавательные функции данного блока.
Второй раздел является центральным в диссертации и посвящен разработке основных механизмов работы со знанием, реализуя цикл приобретения и использования знаний. В каждом из подразделов исследуются текущие методы и средства, ориентированные на решение аналогичных задач, выявляются недостатки, описывается и анализируется предлагаемый метод.
1. Осмысление/Абстрагирование – Начальное построение онтологии предметной области – метод автоматизированного построения онтологии предметной области, реализующийся путем итеративного анализа строящейся онтологии с помощью предложенных методов понимания научно-технических текстов на естественном языке с применением базовой онтологии языка и набора предметно-ориентированных текстов на основе алгоритмов мультиагентного взаимодействия и разрешения конфликтов между квантами знаний. Результатом данного этапа становится начальная онтология предметной области.
 |
| Рисунок 3 – Логическая схема построения начальной онтологии предметной области |
В разделе описываются алгоритмы, применяемые на каждом шаге построения, в том числе как лингвистические шаблоны должны преобразовываться в онтологические конструкции, механизмы распознавания значений атрибутов в тексте, эвристические правила, позволяющие реконструировать зависимость между концептами в онтологии и отношения между объектами. Общая схема метода приведена на рисунке 3.
В таблице 1 приведены типовые лингвистические шаблоны, встречающиеся в тексте, и возможные способы их онтологического представления.
Таблица 1 – Автоматизированное построение онтологии – типовые шаблоны
| Лингвистический шаблон | Возможные онтологические трактовки | Пример |
| ( | а) | Satellite launched |
| а) | University designed spectrometer | |
| а) | Battery was broken | |
| 1) | а) | Rocket attempted to stabilize |
| а) | Microsatellite was cubical in shape | |
| а) | To search news | |
| а) | Describing features | |
| а) | Paint against corrosion | |
| 1) | а) | Found with help of search engine |
| а) | Standard sensors | |
| а) | To launch from VAF airbase |
Здесь группа существительного:![]() , где
, где ![]() – начальная форма, существительное в именительном падеже;
– начальная форма, существительное в именительном падеже; ![]() – формы слова в родительном, дательном, винительном, творительном и предложном падежах;
– формы слова в родительном, дательном, винительном, творительном и предложном падежах; ![]() – характеристики (число, лицо и род). Группа глагола (инфинитив, активный залог, пассивный залог, герундий, предлог, характеристики – переходный и непереходный глагол, а также союз):
– характеристики (число, лицо и род). Группа глагола (инфинитив, активный залог, пассивный залог, герундий, предлог, характеристики – переходный и непереходный глагол, а также союз): ![]() ,
, ![]() – онтология, где
– онтология, где ![]() – множество объектов,
– множество объектов, ![]() – отношений,
– отношений, ![]() – множество допустимых атрибутов (задаваемые именем и типом), и
– множество допустимых атрибутов (задаваемые именем и типом), и ![]() – правил вывода,
– правил вывода, ![]() и
и ![]() – субъект и объект отношения,
– субъект и объект отношения, ![]() – отношение наследования.
– отношение наследования.
Особое внимание уделяется этапу проверки онтологии путем построения семантических дескрипторов документов и анализа противоречий, поскольку он является критическим для всей процедуры построения онтологии и представляет основное отличие предлагаемого подхода по сравнению с известными методами, при этом являясь не независимым этапом, а постоянным процессом автоматической коррекции и верификации, запускаемым после каждого из этапов.
Вводится метрика корректности синтаксической ![]() и семантической связи
и семантической связи ![]() , показывающая, насколько корректна построенная связь между концептами
, показывающая, насколько корректна построенная связь между концептами ![]() и
и ![]() , и, соответственно, представляющими их в тексте группами слов
, и, соответственно, представляющими их в тексте группами слов![]() и
и ![]() .
.
Синтаксическая корректность:
![]()
Тогда степень корректности слова![]() :
:
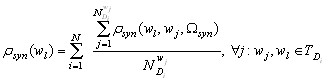 .
.
Общая синтаксическая корректность концепта онтологии:
![]() .
.
Концепт онтологии исключается в случае, когда

![]() ,
, ![]() – число документов, в которых присутствует концепт онтологии. Коэффициенты
– число документов, в которых присутствует концепт онтологии. Коэффициенты ![]() для остальных терминов пересчитываются без учета
для остальных терминов пересчитываются без учета ![]() . В случае нескольких альтернатив термин
. В случае нескольких альтернатив термин ![]() считается надежным, если
считается надежным, если ![]() .
.
Аналогично, семантическая метрика концепта ![]() на основе представляющих его слов
на основе представляющих его слов ![]() вычисляется, как
вычисляется, как
 .
.
Вклад концепта в смысл документа:
 .
.
Термин понят неудовлетворительно и ухудшает общее понимание текста в случае:
![]() .
.
Предлагаемый подход к автоматизированному построению онтологии позволяет добиться следующих основных преимуществ по сравнению с существующими методами:
- Не требуется построение начальной онтологии предметной области человеком-экспертом в качестве базиса для дальнейшей работы.
- Не требуется предобработка человеком-экспертом документов предметной области (включая стандартизацию шаблонов, преобразование форматов, предварительную разметку текста, составление вручную словаря терминов предметной области и пр.).
- Процесс построения онтологии полностью прозрачен для пользователя, обоснования всех принимаемых решений, логика и оценки могут быть прослежены.
- Процесс построения онтологии не зависит от языка документа, за исключением поддержки синтаксических онтологий для разных языков.
- Процесс построения онтологии итеративный, всегда существует обратная связь с возможностью проверить семантику сгенерированной онтологии автоматическим путем, когда уже построенная часть онтологии сама является основой для анализа семантической корректности предлагаемых изменений и дополнений. При этом процесс саморегулирования автоматизирован и может обходиться без человека-эксперта.
- Анализ и вычленение терминов с учетом их семантики происходит в рамках всего корпуса текстов, он не ограничивается анализом индивидуальных предложений.
- Поддерживается возможность работы с множеством документов из нескольких слабосвязанных предметных областей за счет предварительного этапа автоматической предобработки алгоритмом кластеризации.
- Алгоритм может работать как автономно, так и в интерактивном режиме, причем пользователь может повлиять на формирование решения на каждом из этапов работы.
2. Восприятие/Отражение – Представление информационных квантов в терминах онтологии предметной области – метод понимания научно-технических текстов на естественном языке в виде преобразования электронных текстовых документов в семантическую сеть в терминах онтологии предметной
области, основанный на применении механизмов мультиагентного взаимодействия квантов знаний, позволяющих в процессе переговоров реконструировать смысл предложения, и использовании построенных онтологий для хранения межфразового контекста, тем самым дающий возможность представлять смысл связного текста и обеспечивающий механизмы сравнения семантики документов.
Суть предлагаемого подхода состоит в том, что каждому слову языка ставятся в соответствие агенты его смыслов, которые на основе собственных баз знаний (онтологий) конкурируют между собой и кооперируются, договариваясь о том, какой именно конкретный смысл имеет каждое слово в предложении и каков его общий смысл. В результате, основной моделью процесса понимания смысла становится процесс самоорганизации смыслов слов при построении сцены контекста, что принципиально отличает предлагаемый подход от всех на сегодня известных (Рисунок 4).
В процессе синтаксического разбора для каждой пары словосочетаний: ![]() ищутся две синтаксические роли
ищутся две синтаксические роли ![]() ,
,![]() , такие, что
, такие, что ![]() .
.
 |
| Рисунок 4 – Логическая модель процесса анализа ЕЯ текста |
Осуществляются синтаксическое

и морфологическое уточнения:
 .
.
Затем словосочетания объединяются между собой по правилам, приведенным в таблице 2.
Таблица 2 – Создание словосочетаний (на примере союзов)
| Вариант объединения | Требуемые условия |
| Субъектное объединение союзов |  - объединение двух слов союзом - объединение двух слов союзом |
| Союзы могут соединяться с другими союзами | 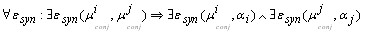 - оба союза должны присоединить к себе хотя бы одно другое слово - оба союза должны присоединить к себе хотя бы одно другое слово  - только прямая связь - только прямая связь |
Субъектное объединение элементов перечисления с другими словами –  |  - союз присоединил уже как минимум два слова с использованием предыдущего типа объединения - союз присоединил уже как минимум два слова с использованием предыдущего типа объединения |
| Объектное объединение союзов | Союзное словосочетание является либо одиночным словом, либо объединением союза и предлога |
Алгоритм синтаксического разбора заканчивается в одном из двух случаев:
1. Найден вариант корректного синтаксического разбора предложений ![]() .
.
2. Рассмотрены все возможные пары слов для объединения и в результате не было найдено ни одного варианта разбора: ![]() .
.
На этапе семантического разбора проверяется непротиворечивость, осуществляется дополнение и уточнение семантического дескриптора. Для каждой пары объектов осуществляется оценка возможности связи. Допустимы следующие случаи:
1. ![]() .
.
2. ![]() .
.
3.  .
.
Возможные противоречия выявляются на основе следующих правил:
 ;
; ;
;-
 .
.
В случае возникновения противоречия или требуемого уточнения алгоритм возвращается на стадию синтаксического разбора. В противном случае формируется общий семантический дескриптор документа посредством слияния имеющейся сцены и сцены, дополненной концептами данного предложения.
Объекты считаются совместимыми, если выполняется:
 .
.
Отношения считаются совместимыми, если
 .
.
Предлагаемый подход позволяет добиться следующих основных преимуществ по сравнению с существующими методами:
- Возможность представления смыслового контекста связного текста за счет использования механизмов представления и обработки знаний, с поддержкой уточнений, разрешением противоречий и пр.
- Возможность построения углубленного межфразового контекста, с возможностями «многократного прочтения» и обработки информации, поступающей онлайн, когда пришедшая позже фраза меняет смысл предыдущих, и требуется заново пересмотреть понимание текста с учетом вновь полученной информации.
- Использование открытой модели предметной области, что дает возможность в полной мере использовать знания эксперта, давая ему мощный инструмент настройки и пополнения онтологии знаниями о предметной области в процессе работы.
- Создание прагматически-ориентированных сценариев работы с полученными знаниями, что позволяет обрабатывать информацию согласно нуждам пользователя и обеспечивает субъектно-ориентированное извлечение и анализ знаний.
3. Применение/Верификация – Механизмы поиска, сравнения, классификации и кластеризации информационных объектов на основе семантических дескрипторов – метод кластерного анализа, реализованный на основе агентного взаимодействия, что обеспечивает механизмы динамической иерархии групп семантически схожих объектов как в пошаговом, так и в пакетном режимах, а также дает возможность работы с неструктурированными квантами информации, тем самым предоставляя механизм поиска, анализа и классификации знаний, содержащихся в неструктурированных текстах.
В предлагаемом подходе в соответствие каждому элементу системы – каждой записи и кластеру, ставится программный агент, представляющий их интересы. Процесс работы системы состоит в переговорах агентов, направленных на улучшение их состояния согласно критериям оценки качества. Вместо централизованной последовательной обработки осуществляется распределенная обработка, в которой каждая запись и каждый кластер самостоятельно и на основе некоторых заданных стратегий в достаточно узко ограниченном контексте принимают решения о вхождении в кластер или выходе из него, расширении или сужении кластера или его удалении, представляя текущий локальный баланс интересов конкретных записей и кластеров. В итоге процесс кластеризации осуществляется путем самоорганизации агентов, формирующих иерархическую кластерную структуру.
В разделе описываются типовые стратегии записи и кластера, поддерживаемые типы полей, возможные способы представления структуры кластеров, вычисления расстояний между записями и кластерами, формулы ценности для кластера и записи, принципы точной и интервальной кластеризации, преобразование и нормирование атрибутов, параметры микроэкономики, в том числе назначение начального количества денег (энергии), механизмы поиска вариантов, вхождения в кластер, распределения денег между кластерами, выход из кластера и налоги.
Целью записи ![]() является максимизация своей ценности
является максимизация своей ценности ![]() . Цель кластера С – максимизация ценности
. Цель кластера С – максимизация ценности
![]() ,
,
где ![]() , k1,k2,k3 – регулирующие коэффициенты.
, k1,k2,k3 – регулирующие коэффициенты.
Начальное назначение денег записи задается как ![]() , где F – эвристическая функция ценности записи. Формула ценности кластера вычисляется следующим образом:
, где F – эвристическая функция ценности записи. Формула ценности кластера вычисляется следующим образом:
![]() ,
,
где Nrec – число записей в кластере, Nall – общее число записей в пространстве D, М – число полей, по которым образован кластер.
Число полей, по которым образуется кластер, определяется следующим образом – вычисляется Difi – степень совпадения атрибута i
 .
.
Затем вычисляется Infi – степень влияния атрибута на общую формулу ![]() , здесь
, здесь ![]() – коэффициент поощрения похожести атрибута.
– коэффициент поощрения похожести атрибута.
Число полей (кластер формируется по атрибутам ![]() ) –
) –
![]()
Оценка возможности создания кластера между точками X и Y:
![]() .
.
Формула оплаты за вхождение в кластер:

Распределение денег между кластерами для записи:
![]() .
.
Предлагаемый подход к кластеризации информации, основанный на агентном взаимодействии, позволяет добиться следующих основных преимуществ по сравнению с существующими методами:
- Возможность работы с семантическими сетями, что позволяет кластеризовывать сложные информационные объекты (образы, тексты).
- Алгоритм не требует предобработки данных экспертом предметной области, не требует участия человека в процессе работы, но может использовать взаимодействие с экспертом для повышения качества результатов.
- Алгоритм способен работать в неэвклидовом пространстве, где мера близости может существовать только для каждой пары объектов, а правило треугольника не соблюдается.
- Создание значимых кластеров в любом подпространстве исследуемого пространства решений, алгоритм учитывает любые комбинации параметров, позволяя находить зависимости между любым поднабором атрибутов.
- Прозрачность принимаемых решений и описание кластера в терминах онтологии, что дает возможность удобного анализа результатов, описание кластера в виде правил вида «если – то».
- Возможность создания сложной иерархической структуры кластеров, где каждая запись и кластер способны входить во множество других кластеров, тем самым учитывая и отображая все найденные семантические зависимости.
4. Переосмысление/Пополнение – Алгоритм машинного обучения системы в форме автоматизированного пополнения онтологии новыми знаниями на основе зависимостей, найденных в процессе анализа выявленных групп кластеров информационных объектов – метод автоматизированного пополнения онтологии новыми знаниями на основе анализа семантических групп, найденных на этапе кластеризации, и применения ряда эвристических правил, позволяющих уточнить и пополнить онтологию предметной области, тем самым улучшая качество представления, поиска и анализа документов.
Модуль автоматизированного пополнения онтологии позволяет на основе найденных групп семантически близких дескрипторов «выращивать» новые связи между существующими в онтологии квантами знаний.
Пополнение и уточнение онтологии основано на гипотезе взаимодействия: «если концепты онтологии всегда встречаются вместе в определенной ситуации, значит, они семантически связаны между собой, причем характер связи определяется ситуацией». Методы модуля позволяют проанализировать получившуюся структуру и дескрипторы кластеров, выделить необнаруженные ранее зависимости между концептами онтологии.
После того, как документы получили семантические дескрипторы и кластеризованы по семантической близости, происходит процесс кластеризации созданных ранее кластеров. Теперь анализируются те зависимости, по которым были объединены документы в различных группах. Подобный процесс позволяет подняться над уровнем документов и исследовать уже саму предметную область, анализируя те концепты, которые встречаются в различных семантически близких группах, и установить возможные взаимосвязи между ними.
Варианты зависимостей и возможных изменений онтологии приведены в таблице 3.
Таблица 3 – Типы зависимостей для пополнения онтологии предметной области
| Тип зависимости | Возможные изменения онтологии |
| Два несвязанных объекта | 1. Данные объекты должны быть связаны между собой отношением, которое присутствует в онтологии, но их не связывает |
| Два объекта, связанные определенным отношением | 1. Отношение делится на два различных отношения, связывающие объекты  2. Родственные отношения 2. Родственные отношения  |
Два объекта, всегда связанные двумя конкретными отношениями  | 1. Синонимы для одного и того же отношения |
| Объект плюс другой объект, связанный определенным отношением с различными третьими объектами | 1. Объекты должны быть связаны данным отношением |
| Объект связан отношениями одного и того же типа с двумя объектами разных типов | 1. Объекты родственны |
| Объект плюс атрибут, встречаемый у других различных объектов | 1. Атрибут принадлежит данному объекту |
| Объект плюс атрибут, всегда наличествующий у другого объекта | 1. Атрибут ошибочно приписан другому объекту |
| Объект плюс отношение, не связанные ни с каким объектом | 1. Новый объект в онтологии |
| Два атрибута, встречающиеся у одного и того же объекта | 1. Допустимо объединение атрибутов |
| Один атрибут, встречающийся одновременно у нескольких разных объектов (в случае устойчивой комбинации) | 1. Одному из объектов атрибут приписан ошибочно |
В результате по итогам анализа семантики кластеров для каждой группы (кластера кластеров) определяется ряд возможных пополнений \ изменений в онтологию. При этом для каждого из вариантов изменения, аналогично этапу построения, считается степень его корректности путем временного изменения онтологии и анализа числа корректных \ некорректных использований измененной части онтологии на имеющемся наборе документов. Все варианты и их степень корректности предлагаются пользователю, и в интерактивном режиме можно изменить и уточнить предложенные гипотезы для окончательного утверждения и пополнения онтологии.
Предлагаемый подход к автоматизированному пополнению онтологии позволяет добиться следующих основных преимуществ по сравнению с существующими методами:
- Процесс пополнения онтологии полностью прозрачен для пользователя, обоснования всех принимаемых решений, логика и оценки могут быть прослежены.
- В процессе анализа и пополнения онтологии в полной мере учитывается семантика, построенная онтология является основой для анализа семантической корректности предлагаемых изменений.
- Алгоритм ориентирован на пополнение всех существующих типов связей в онтологии, включая принадлежность атрибутов и корректность отношений.
- Поддерживается возможность уточнения имеющейся онтологии с учетом ее потенциальной начальной некорректности.
- Допустима работа с множеством документов из нескольких слабосвязанных предметных областей.
- Алгоритм может работать как автономно, так и в интерактивном режиме, причем пользователь может повлиять на формирование решения на каждом из этапов работы.
Третий раздел посвящен разработке инструментальной среды онтологического анализа и синтеза для решения задач извлечения знаний и понимания текста на естественном языке, исследованию реализационных характеристик разработанных средств, оценке эффективности их работы и качества результатов.
Предлагаемый подход к интеграции знаний, основанный на агентных взаимодействиях и заключающийся в совместном использовании агентных механизмов работы со знанием на естественном языке и мультиагентного кластерного анализа, позволил создать архитектуру работы со знанием для реализации предложенных методов автоматизированного конструирования онтологий, представления и обработки информации, анализа результатов и пополнения знаний, обеспечивая цикл приобретения и интеграции знаний, необходимый для эффективного и оперативного использования научно-технической информации в сфере промышленного проектирования и производства и других областях.
Разработанная среда включает в себя несколько программных комплексов: инструментарий инженерии знаний, предназначенный для создания онтологий предметной области и логики принятия решений агентов, и программный инструментарий, ориентированный на представление, анализ и обработку знаний, представленных в виде текста на естественном языке (Рисунок 5).
 |
| Рисунок 5 – Общая логическая архитектура системы |
Инструментарий инженерии знаний включает в себя конструктор онтологий, автоматизированную систему построения онтологий, систему понимания научно-технического текста на естественном языке, систему извлечения знаний, модуль пополнения онтологических знаний и ряд дополнительных модулей, в том числе отладочную систему, интерфейсы работы с базами данных и внешними приложениями.
Для создания специализированных программных компонент приложения предлагается инструментарий программиста, состоящий из расширяемого набора библиотек программ и позволяющий настроить инструментальную среду для обработки информации в исследуемой предметной области.
Основу всего комплекса составляет исполняющая система, реализованная в двух версиях на основе наиболее распространенных сред объектно-ориентированного программирования Object Pascal и C++ в операционной системе Windows.
В разделе описываются реализационные характеристики отдельных модулей и всей инструментальной среды в целом, в частности, поддерживаемые операционные системы Win 98, 2000, NT, XP, Vista, механизмы интеграции с базами данных BDE, ODBC, ADO и MTS, поддержка COM/CORBA, поддержка XML и периферийных устройств (SMS, E-mail, fax etc), а также характеристики системы по производительности.
В разделе приводится ряд экспериментальных оценок параметров производительности основных модулей и алгоритмов, входящих в структуру предлагаемой системы интеграции знаний, а также обсуждаются возможные способы улучшения производительности и качества результатов.
Анализ проводился независимо по нескольким предметным областям (в том числе малые космические аппараты, логистика, страхование, биология), исследуемым в рамках решения реальных прикладных задач в сфере промышленного проектирования и производства, и других областях. В каждой области была построена онтология, взяты наборы реальных документов из практики (две группы – исходная и тестовая выборки, в каждой порядка 5000 документов). Все замеры делались на разных типах и объемах данных, затем соответствующие результаты усреднялись по количеству запусков и выводились для анализа.
Исследование производительности, эффективности и качества
результатов для каждого из анализируемых модулей
А. Автоматизированное построение онтологии
Исследуемые характеристики:
1. Зависимость скорости работы системы от объема задачи (число слов в документах).
2. Требуемое количество агентов (среднее/пиковое) – объем задачи.
3. Число выделяемых терминов – объем задачи.
4. Сложность онтологии: количество порождаемых концептов (объекты, отношения, атрибуты) – объем задачи.
5. Требуемый уровень доработки онтологии (%) от объема автоматически построенной онтологии
6. Тип доработок (%), требуемых от человека-эксперта для уточнения автоматически построенной онтологии.
Основные результаты и выводы:
1. В среднем в тексте алгоритм выделяет порядка 20% слов как значимые, которые затем преобразуются в термины.
2. Для качественного построения начальной онтологии необходим анализ порядка 35 тысяч слов (около 300-400 типовых научно-технических документов) для выявления основных терминов, используемых в предметной области. Для минимально корректного реконструирования набора терминов рекомендуется брать не менее 12-15 тыс. слов.
3. При построении концептов онтологии из терминов наблюдается соотношение 4:1 – т.е. из четырех найденных терминов формируется один концепт.
4. При построении онтологии наблюдается пропорция 4:1:20, т.е. в среднем на 4 объекта приходится 1 отношение и 20 атрибутов.
5. По оценкам экспертов предметную область можно покрыть на основе порядка 2500-3000 концептов. Наши оценки показали чуть большие объемы – порядка 4000 концептов для начального покрытия предметной области (без учета добавлений человека-эксперта), и порядка 5000 после уточнений эксперта.
6. Уже простая онтология на 250 концептов требует не менее 15% дополнительных работ человека-эксперта, который уточняет и изменяет автоматически построенную онтологию. Показано, что процесс сходящийся, и даже в случае серьезных возрастаний объемов онтологии требуется не более 40% дополнительных настроек для получения окончательной работоспособной онтологии.
B. Понимание текста на естественном языке – построение семантических дескрипторов
Исследуемые характеристики:
1. Зависимость скорости работы системы от объема задачи (для всех этапов разбора – морфология, синтаксис, семантика, прагматика).
2. Среднее требуемое время на этап разбора (%).
3. Среднее/пиковое число агентов при обработке одного предложения – объем задачи (число слов, тыс.).
4. Среднее число изменений\дополнений в семантический дескриптор (т.е. перестройка структуры системы при разборе нового предложения) в зависимости от объема задачи.
5. Среднее время сравнения семантических дескрипторов – сложность дескриптора (число концептов и связей).
Основные результаты и выводы:
1. Время на морфологию растет линейно – на данном этапе почти не осуществляется рассуждений.
2. Аналогичным образом линейна часть, связанная с прагматикой – т.к. она зависит только от сложности окончательно сформированного дескриптора.
3. Часть, связанная с синтаксисом, растет квадратично – связано с использованием агентных переговоров и множественностью вариантов разбора.
4. Наиболее сильно, хотя и по-прежнему квадратично, растет время, требуемое на семантический этап. Это согласуется с логикой алгоритма – большее число ветвей понимания предложения, уточнения смысла и пересмотра ранее распознанной сцены, что подразумевает возврат и повторный анализ предыдущих предложений.
5. При оценке пикового числа агентов выяснилось, что вне зависимости от объемов задачи, оно примерно совпадает, что противоречит теоретическим выводам. Таким образом, согласно нашим алгоритмам всегда есть некая «допустимая глубина перестройки», далее которой система не позволяет изменять смысл всего текста – ограничение текущей версии алгоритма.
6. Среднее число изменений и дополнений в семантический дескриптор растет с ростом размерности задачи, т.к. изменения не уходят «в глубину», а затрагивают непосредственно концепты, чей смысл изменяется с новой информацией.
7. В среднем новый объект в сцене обновляет 4-5 связей \ значений атрибутов, при этом глубина обновлений достигает 3 уровней (уровень – появление объекта \ уточнение значения).
С. Кластеризация и извлечение знаний
Исследуемые характеристики:
1. Зависимость скорости работы системы от объема задачи (точная кластеризация, кластеризация по диапазону, кластеризация семантических дескрипторов)
2. Среднее/пиковое число агентов при обработке одной записи – объем задачи (число записей).
3. Количество порождаемых кластеров – объем задачи (однокластерный и многокластерный случаи).
4. Уровень иерархии и размерность кластеров – объем задачи.
5. Среднее число изменений связей в зависимости от шага кластеризации.
6. Количество «значимых» кластеров в зависимости от объема задачи
Основные результаты и выводы:
1. Среднее число агентов (и, соответственно, время) на обработку одной записи растет медленно и линейно с ростом размерности задачи, при этом пиковое время растет квадратично.
2. По мере возрастания числа записей, рост числа кластеров и в однокластерном, и особенно в многокластерном варианте начинает затухать. Это означает, что система приходит к динамическому равновесию.
3. Среднее число изменений связей при приходе новой записи коррелирует со средним числом задействованных агентов (в среднем изменение решения одного агента влечет за собой пересмотр 4-5 связей) и тоже возрастает по линейному закону. Но в случае «пика», т.е. прихода записи, которая повлекла за собой серьезную перестройку структуры, данный график коррелирует с пиковой нагрузкой по агентам, и возрастает по полиномиальному закону.
4. Вне зависимости от объема задачи, число значимых правил составляет порядка 20-25 % от общего числа найденных правил, из них тривиальными (т.е. сразу очевидными эксперту за счет дополнительных знаний о предметной области), является порядка 60%
D. Автоматизированное пополнение онтологии
Исследуемые характеристики:
1. Скорость работы системы от объема задачи (число концептов).
2. Требуемое количество агентов (среднее/пиковое) – объем задачи.
3. Типы комбинаций концептов онтологии (%).
4. Количество комбинаций определенного типа для онтологии порядка 1000 концептов, и набора документов порядка 10000 штук.
5. Распределение для каждой комбинации встречающихся вариантов изменения онтологии.
6. Причины возникновения некорректных гипотез.
Основные результаты и выводы:
1. Учет затрат времени человека-эксперта примерно в 4 раза увеличивает общее время работы системы. (При этом качество результатов, оценочно возрастает примерно на 55%).
2. В результате предложенных изменений, которые принимались экспертом-онтологом, онтология выросла примерно на треть (32%).
3. С помощью данных алгоритмов даже с учетом работы эксперта можно успеть качественно пополнить онтологию примерно за 1-2 рабочих дня. В случае, если б работа полностью осуществлялась вручную, по оценкам это в среднем занимает от одной до полутора недель.
4. Наиболее частыми комбинациями, встречающимися при кластеризации и нахождении зависимостей, стали «два несвязанных объекта», «объект плюс отношение», «два объекта, связанные отношением», «два атрибута одного объекта» и «объект плюс чужой атрибут». На их долю пришлось порядка 74% от общего числа найденных комбинаций.
5. Наилучшие результаты, почти всегда ведущие к пополнению онтологии, показали такие типы комбинаций, как наличие двух несвязных объектов (требуют связи отношением) – 14% погрешности, объект с «повисшим» отношением (требует новый объект в онтологию) – 26% погрешности.
В четвертом разделе рассматривается типовая прикладная задача в сфере интеграции профессиональных знаний - задача мониторинга релевантной информации в Интернете в области малых космических аппаратов с целью поддержки принятия решений в промышленном проектировании образцов новой техники.
Анализ тенденций развития космических технологий показывает, что одним из наиболее перспективных путей их совершенствования является применение малых космических аппаратов (МКА) и систем на их основе. Побудительным мотивом для перехода от создания и использования крупных универсальных спутников к МКА стал прорыв в электронике, двигателестроении, в области создания новых конструкционных материалов и др. областях, что позволило получить такие преимущества, как низкая стоимость и малый срок создания, что ведет к уменьшению финансовых рисков и возможности использования МКА как «полигона обкатки» новых космических технологий.
В силу перспективности МКА для космической промышленности России в рамках анализа существующих и планируемых решений, имеющихся на мировом рынке и предлагаемых странами-партнерами и конкурентами, становится необходимым постоянный мониторинг имеющейся и появляющейся информации, и особенно, в связи с все возрастающей популярностью Интернета, анализ электронных документов – новостных лент, специализированных порталов, блогов.
Имеющиеся на текущий момент технологии поиска и метапоиска, включая поиск по ключевым словам, поиск с использованием операндов булевой алгебры, поиск с расстоянием, построение нового запроса на базе предыдущего, поиск в определенных полях html-документа и морфологический поиск все равно не обеспечивают основного – они не дают возможность проанализировать семантику документа, выявить его реальный смысл (который зачастую противоречит указанным в нем ключевым словам, т.к., например, они были указаны с целью занятия более высокого положения в поисковых системах) и определить актуальность предлагаемой информации.
Была разработана метапоисковая система, позволяющая в удобной форме специфицировать интересующую предметную область (в данном случае – космические технологии и МКА), наполнить ее предметно-ориентированными знаниями и получить возможность анализировать возвращаемые поисковыми системами тексты с точки зрения семантики, отделяя релевантные тексты от ошибочных, анализируя степень релевантности текста запросу, осуществлять мониторинг сайтов.
С помощью методов автоматизированного построения онтологий на основе набора текстов, выданных поисковыми системами по популярным запросам в данной области, создана онтология малых космических аппаратов. Выделены классы МКА – мини, микро, нано, пико, фемто. Для каждого из классов найден набор имен существующих спутников (в частности, для класса мини это наши спутники класса COSMOS (2337-39, 2390-1 (2002), 2384-6 (2001) и пр.) и GONETS (12-14 (2001), D1-1-3 (1996) и пр.), американские SORCE (2003), RHESSI, серия GLOBALSTAR M, японский MDS-1 и т.д.).
Выделены параметры малых спутников, в том числе масса, полезная нагрузка, габариты, форма, бортовая и полезная емкость, тип орбиты, источники питания, каналы связи, типы двигателей \ горючего, датчики, стабилизация, тип оборудования, тип миссии и пр.,
Для каждого из параметров выделены возможные значения, например, для propulsion возможные значения – chemical rocket, bipropellant, air-breathing engine, monopropellant, resistojet, electric propulsion, ion thruster, solar sail, aerobraking, nuclear reactor и пр. (более 30 значений)
Также выделены типы ракетоносителей и их названия (например, для heavy lift launch vehicles – Ariane 5, Protone D1, Titan III-IV, Zenith Sealauncher и пр.), наземных баз, организаций.
Также в онтологию добавлен ряд типовых названий (имена стран, названия фирм, организаций и университетов, конференции, ученые и пр.).
Всего в системе порядка 2000 концептов, из них ~15 отношений, ~300 объектов. С учетом всех значений атрибутов и синонимов, общее количество слов в тезаурусе порядка 15 тысяч.
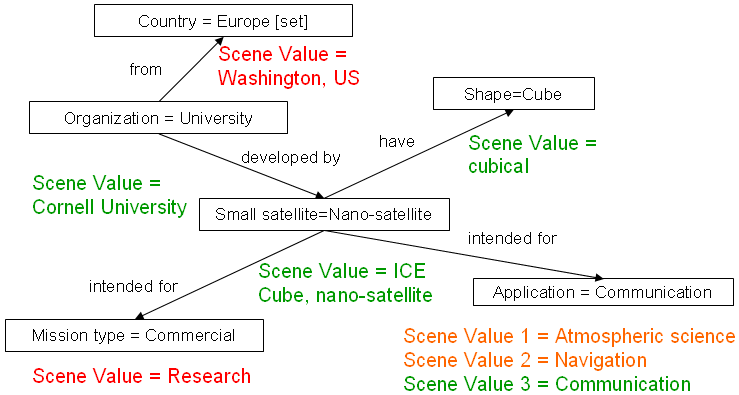
Для импортируемых документов из поисковых систем по набору запросов-критериев на основе онтологии предметной области создаются семантические дескрипторы, отражающие смысл сайта.
Далее происходит сравнение семантических дескрипторов критериев отбора и документов на основе онтологии предметной области (Рисунок 6). По степени соответствия выставляется рейтинг, который используется для отсечения нерелевантных документов.
 |  |
 | |
| Рисунок 6 – Представление сайта в виде семантического дескриптора и онтологическое сравнение с поисковым запросом | |
В процессе экспертного сравнения качества результатов на наборе тестовых выборок, проанализированных вручную, показано, что степень отбора релевантных документов достигает 85-90%, во всех исследованных примерах разработанная система позволяла существенно улучшить результаты с точки зрения семантики сайтов \ документов, интересующих пользователя, четко разделяла релевантные и нерелевантные сайты и корректно упорядочивала релевантные сайты по степени соответствия пользовательскому запросу
Предложенная система, в которой сочетаются разработки в области систем понимания текста на естественном языке и извлечения знаний, является уникальным примером процесса интеграции знаний, ориентированным на конкретного пользователя, предоставляя механизмы для формализации и структурирования предметных областей, интеллектуального поиска, анализа и классификации сайтов и документов. В сочетании с предлагаемыми методами анализа и формирования знания, система способна решать основные проблемы, стоящие в текущий момент перед Интернет-сообществом, и может служить основой для общеинтеграционной платформы систематизации, обобщения и анализа научно-технических и производственных знаний в самых разных предметных областях.
В пятом разделе рассматривается ряд прикладных задач в сфере промышленного производства и других областях, решенных с использованием предлагаемых методов и средств, а также проводится сравнение с имеющимися аналогами.
Проблема автоматической обработки, преобразования и коррекции логистических сообщений стандартных форматов обмена бизнес-данными. С целью интеграции информационных служб промышленных компаний-партнеров используются стандартные форматы обмена бизнес-данными (ANSI X12, EDIFACT, XML и пр.). Проблема перевода сообщений между различными форматами решается путем ручного конструирования схемы преобразования форматов с помощью некоторой программы интеграции приложений (например, BizTalk). Сложность такого решения состоит в том, что требуется серьезный предварительный экспертный анализ, помогающий выяснить семантические соответствия полей различных форматов. В случае же, если формат был адаптирован под нужды фирмы, или в рамках стандартного формата происходит интерпретация полей, специфичная только для данного клиента, процесс выявления соответствий может быть очень сложен и долог. На текущий день, по оценкам экспертов, построение соответствия одного раздела формата в рамках пакета стандартов занимает около недели. На то, чтобы полностью интегрировать информационные службы двух компаний, уходит не менее полугода, что является очень дорогостоящим решением, к тому же не отвечающим предъявляемым рынком требованиям к динамике и скорости реакции.
Основной идеей предложенного подхода является введение «промежуточного» уровня – онтологии, хранящей знания о предметной области, т.н. нейтрального формата. Таким образом, знания, представленные в любом формате, хранятся в специальной внутренней структуре, не зависящей ни от структуры формата, ни от платформы. Подобная архитектура позволяет осуществлять перевод из формата в формат естественным образом – как только построено соответствие между новым форматом и онтологией, обеспечивается возможность коммуникации между всеми уже зарегистрированными форматами.
Предложенные в диссертации методы помогли автоматизировано построить начальную версию онтологии нейтрального формата, покрывающую семантику различных форматов данных. В дальнейшем использование эвристических правил исправления на основе онтологии предметной области с поддержкой методов понимания текстов на естественном языке позволило подстраиваться под вариации имеющегося формата, определяя по контексту смысл неизвестного поля в процессе регистрации нового формата. А алгоритмы кластеризации, объединяя типовые значения полей и давая возможные корректные варианты и их вероятность, позволили осуществлять автоматизированное исправление значений в поступающих сообщениях в режиме онлайн.
Задача классификации профессиональных, деловых, и научно-технических документов. У крупной страховой компании возникла задача классифицировать группы семантически схожих документов (страховых договоров), для построения на их базе документа-образца (например, необходимо все договора по страхованию автомобиля автоматически разделить на группы, т.к. условия сильно отличаются в зависимости от клиента – возраст, пол, история вождения, доход и пр., учесть аналогичные договора конкурирующих фирм, и для каждой группы схожих страховых договоров сформировать шаблон типового договора, включающий наиболее удачные пункты документов группы).
Для решения данной задачи был предложен подход, основанный на разрабатываемых в работе методах – а именно: на основе выборки документов была автоматизированным образом построена онтология предметной области. Далее все документы получили семантические дескрипторы. Затем с помощью алгоритма кластеризации была сформирована иерархия групп документов. Для каждой группы, на основе эвристических правил, заданных в онтологии и статистики частности использования терминов и ключевых абзацев, формировался документ-шаблон.
При анализе качества результатов приведем реальные цифры, выявленные при решении данной задачи для страховой компании. Имелось 25 000 различных договоров и соглашений в области страхования. В среднем один документ в формате MS Word имел объем порядка 30 страниц. По предварительным оценкам фирмы заказчика, на решение задачи классификации и формирования шаблонов групп документов им должно было потребоваться порядка 16 человеко-лет. С помощью разработанной программы задачу удалось решить в 30 человеко-месяцев – 6.5 раз быстрее.
Разработанные в диссертации методы, в том числе метод понимания текста, обеспечивающий поиск и классификацию документов, и метод кластерного анализа, использующийся для извлечения знаний и нахождения зависимостей, достаточно универсальны и применимы в различных предметных областях, причем настройка осуществляется путем изменения онтологии предметной области, не затрагивая алгоритмы. Поэтому они способны решать задачи и вне сферы промышленного производства, характерными примерами чего могут служить проблема семантико-ориентированного поиска и проблема анализа действий пользователя в рамках Интернет-портала, рассмотренные ниже.
Проблема семантико-ориентированного поиска в информационно-поисковой системе MEDLINE. Доступная в Интернете БД MEDLINE ежегодно пополняется более чем миллионом статей, посвященных современным проблемам биологии, химии, медицины. Для нахождения рефератов используется механизм поиска по ключевым словам, который, как показала практика, является поверхностным и весьма неточным, в изобилии предлагающим пользователю избыточную информацию и зачастую пропускающим необходимую. Становится востребованным другой механизм поиска, ориентированный на семантику предметной области и допускающий запросы вида: «Нас интересуют результаты экспериментов класса «А», причем только такие, в которых воздействию подвергался объект «Б», имеющий свойства «В» и «Г», при этом длительность этого процесса не превышала «Д»».
Для решения проблемы был предложен новый подход, основанный на механизмах понимания текстов на естественном языке. В данном подходе посредством начального анализа текстов предметной области была построена онтология молекулярной биологии, которая затем валидировалась экспертом. На основе данной онтологии каждому документу, получаемому по исходному запросу к БД, ставился в соответствии семантический дескриптор, и далее система позволяла определить степень релевантности статьи запросу на основе сравнения дескрипторов с помощью онтологии.
Сравнивая результаты системы со статьями, вручную проверенными и отобранными экспертами, было показано, что подобный подход позволяет добиться точности от 82 до 90% в отборе правильных рефератов (зависит от типа запроса), и порядка 5-8 % ошибки в процессе отсечения неправильных.
На выполнение конкретного практического задания заказчиков-биологов по оценке вручную требовалось порядка 4 человеко-лет, с помощью разработанной системы удалось решить задачу за 8 человеко-месяцев, т.е. более, чем в 6 раз быстрее, тем самым высвободив ценные человеческие ресурсы и сэкономив значительные средства.
Система онлайн анализа пользователей Интернет-портала по продаже «горящих» авиационных билетов. Ключевой возможностью портала фирмы-заказчика была идея учета индивидуальных предпочтений пользователя для интегрированного предложения различных сервисов, например, выбора гостиницы, кросс-продажи билетов на культурные события, бронирования ресторанов, сдача в аренду машин и пр.
Для решения этой задачи использовался предложенный модуль кластерного анализа, позволивший проанализировать предпочтения пользователей, приходящих на сайт (как явные, задаваемые матрицей на сайте, так и неявные, следующие из выбора опций), выявить группы пользователей со сходными интересами, а также проанализировать качество предлагаемых услуг, сравнивая получаемые результаты на соответствие ожиданиям пользователя.
Тем самым, была достигнута индивидуализация в общении с пользователями – каждому предлагались целенаправленно сервисы, интересующие его согласно предпочтениям, и повышено общее качество обслуживания.
Предложенная система способна подключаться к любому Интернет-порталу со специфицированным форматом хранения данных с целью выявления правил, описывающих типы пользователей и их интересы, что позволяет повысить качество взаимодействия с клиентами за счет индивидуализации подхода.
ЗАКЛЮЧЕНИЕ
В диссертации решена научная проблема разработки и развития теоретических основ и инструментальных программных средств для решения проблемы интеграции профессиональных научно-технических знаний, представленных в виде текстов на естественном языке, с целью индивидуализации процесса приобретения и анализа знаний.
Сущность предложенной методики состоит в использовании единого онтологического подхода в рамках субъектно-ориентированной модели приобретения знаний для индивидуализации процесса представления и анализа знаний для эксперта предметной области, и использовании мультиагентного подхода для реализации основных блоков инструментальной среды онтологического анализа и синтеза.
Основные научные и практические результаты работы состоят в следующем:
1. Предложен онтологический подход к задаче интеграции профессиональных научно-технических знаний, ориентированный на субъекта исследования и реализуемый на основе использования онтологии предметной области, индивидуально подстраиваемой под субъекта и автоматизировано сконструированной с помощью имеющихся материалов и знаний эксперта о предметной области, что обеспечивает полный цикл приобретения и интеграции научно-технических знаний, необходимый для эффективного и оперативного использования информации и поддержки принятия решений в сфере промышленного проектирования и производства, а также других областях.
2. Предложен метод автоматизированного построения начальной онтологии, реализующийся путем итеративного анализа строящейся онтологии с помощью предложенного мультиагентного метода понимания научно-технических текстов на естественном языке с применением базовой онтологии языка и набора предметно-ориентированных текстов, позволяющий оперативно получать начальное формализованное знание о предметной области.
3. Предложен метод преобразования неструктурированной информации на естественном языке в семантическую сеть в терминах онтологии предметной области, заключающийся в применении механизмов агентного взаимодействия квантов знаний, позволяющих реконструировать смысл предложения, и использовании построенных онтологий для хранения межфразового контекста.
4. Предложен метод кластерного анализа, реализованный на основе агентного взаимодействия, что обеспечивает механизмы динамической иерархии групп семантически схожих объектов как в пошаговом, так и в пакетном режимах, а также дает возможность работы с неструктурированными квантами информации.
5. Предложен метод машинного обучения системы в форме автоматизированного пополнения онтологии новыми знаниями на основе зависимостей, найденных в процессе анализа выявленных групп кластеров, что дает возможность уточнять знания о предметной области, улучшая качество представления, поиска и анализа документов.
6. Разработана и реализована инструментальная среда онтологического анализа и синтеза, где инструментарий инженерии знаний включает в себя конструктор онтологий, автоматизированную систему построения онтологий, систему понимания текста на естественном языке, систему извлечения знаний, модуль пополнения онтологических знаний и ряд дополнительных модулей, в том числе отладочную систему, интерфейсы работы с базами данных и внешними приложениями.
7. Выработаны критерии оценки и проведены экспериментальные исследования реализационных характеристик разработанных методов и средств, получено порядка 50 оценок и рекомендаций по применению предлагаемых алгоритмов. Исследования подтвердили эффективность предлагаемых методов, в частности было показано, что начальное автоматизированное построение онтологии позволяет сконструировать от 60 до 85% онтологии, представление текста в виде семантического дескриптора остается корректным примерно в 85-90% случаев, кластерное извлечение знаний формулирует до 22-27% значимых правил, при этом порядка 10-12% являются неизвестными для экспертов предметных областей, а пополнение онтологий позволяет дополнительно расширить начальную онтологию до 32% от первоначального объема.
8. На основе разработанных методов и средств создан ряд прикладных промышленных систем для применения в задачах мониторинга информации в области малых космических аппаратов, логистики, поисковых и метапоисковых системах, системах классификации профессионального и научно-технического документооборота, семантическом анализе действий пользователя в режиме онлайн, электронной коммерции и других. Полученный опыт свидетельствует, что разработанные методы и средства позволяют эффективно решать задачи анализа и извлечения знаний из естественно-языковых текстов, а использование созданного инструментария повышает производительность труда, сокращает стоимость и сроки разработки, а также упрощает процессы интеграции и сопровождения рассматриваемых промышленных систем.
Основные результаты диссертации отражены в следующих работах:
Статьи, опубликованные в реферируемых журналах из Перечня ВАК:
- Минаков И.А. Онлайн-анализ пользователей Интернет-портала продажи «горящих» авиабилетов // Информационные технологии, 2006. № 1. С.62-68.
- Андреев В., Виттих В., Батищев С., Ивкушкин К., Минаков И., Ржевский Г., Сафронов А., Скобелев П. Методы и средства создания открытых мультиагентных систем для поддержки процессов принятия решений // Изв. РАН. Теория и системы управления, 2003. № 1. С.126-137.
- Минаков И.А. Система интеллектуального метапоиска в сети Интернет для оперативного нахождения и мониторинга релевантной информации в области малых космических аппаратов // Вестник Самарского гос. техн. ун-та. Серия «Технические науки», 2007. № 1(19). С.28-35.
- Минаков И.А. Интеграция профессиональных знаний, представленных в виде текстов на естественном языке // Вестник Самарского гос. техн. ун-та. Серия «Технические науки». Самара: СамГТУ, 2006. Вып. 41. С. 18-25.
- Минаков И.А. Кластеризация неструктурированной информации, представленной в виде текстов на естественном языке // Вестник Самарского гос. техн. ун-та. Серия «Технические науки». Самара: СамГТУ, 2006. Вып. 40. С. 15-22.
- Минаков И.А. Анализ эффективности и выработка рекомендаций для повышения качества алгоритмов кластеризации и текстопонимания в онтологической модели приобретения знаний // Вестник Самарского гос. техн. ун-та. Серия «Технические науки». Самара: СамГТУ, 2005. Вып. 39. С. 10-17.
- Минаков И.А. Архитектура инструментальной среды, ориентированной на решение задач извлечения знаний и понимания текста на естественном языке //Вестник Самар. гос. техн. ун-та. Серия «Технические науки», Самара: СамГТУ, 2005. Вып. 32. С. 12-19.
- Минаков И.А. Автоматизированное пополнение онтологии на основе знаний, извлеченных в процессе кластеризации // Вестник Самар. гос. техн. ун-та. Серия «Технические науки». Самара: СамГТУ, 2005. Вып. 33. С. 321-326.
- Минаков И.А. Разработка автоматизированной системы построения онтологии предметной области на основе анализа текстов на естественном языке // Вестник Самар. гос. техн. ун-та. Серия «Технические науки». Самара: СамГТУ, 2004. Вып. 20. С. 44-48.
- Батищев С.В., Лахин О.И., Минаков И.А., Ржевский Г.А., Скобелев П.О. Разработка мультиагентной системы дистанционного обучения для Интернет-портала «Оптик-сити» // Изв. СНЦ РАН. – 2003. – Т.5, №1. – С.91-95.
- Батищев С., Ивкушкин К., Минаков И., Ржевский Г., Скобелев П. Открытые мультиагентные системы для поддержки процессов принятия решений при управлении предприятиями // Изв. СНЦ РАН, Январь – Июнь 2001. Самара: СНЦ РАН, 2001. С.71-79.
- Батищев С.В., Лахин О.И., Минаков И.А., Ржевский Г.А., Скобелев П.О. Разработка инструментальной системы для создания мультиагентных приложений в сети Интернет // Изв. СНЦ РАН. Самара: СНЦ РАН, 2001. Т.3, №1. С.131-135.
- Минаков И.А. Сравнительный анализ некоторых методов случайного поиска и оптимизации // Изв. СНЦ РАН. Самара: СНЦ РАН, № 2. 1999. С.286-293.
Статьи, опубликованные в материалах конференций и других журналах
- Виттих В.А., Минаков И.А. Интеграция профессиональных знаний: основные положения подхода // Проблемы управления и моделирования в сложных системах: Тр. IХ Междунар. конф., Самара, 22 июня – 29 июня 2007. Самара: СНЦ РАН, 2007. С.191-197.
- Минаков И.А. Интеграция профессиональных знаний: методы и средства // Проблемы управления и моделирования в сложных системах: Тр. IХ Междунар. конф., Самара, 22 июня – 29 июня 2007. Самара: СНЦ РАН, 2007. С. 498-510.
- Igor Minakov, George Rzevski, Petr Skobelev, Simon Volman “Automatic Extraction of Business Rules to Improve Quality in Planning and Consolidation in Transport Logistics Basing on Multi-Agent Clustering”. Proceedings of the 2nd International Workshop - Autonomous Intelligent Systems: Agents and Data Mining (AIS-ADM-07), St. Petersburg, Russia, June 3-5, 2007, LNAI 4476, pp. 124-137.
- Marat Kanteev, Igor Minakov, George Rzevski, Petr Skobelev, Simon Volman “Multi-Agent Meta-Search Engine Based on Domain Ontology“. Proceedings of the 2nd International Workshop - Autonomous Intelligent Systems: Agents and Data Mining (AIS-ADM-07), St. Petersburg, Russia, June 3-5, 2007, LNAI 4476, pp. 269-274.
- Igor Minakov, George Rzevski, Petr Skobelev, and Semen Volman “Dynamic Pattern Discovery using Multi-Agent Technology”. Proceedings of the 6th WSEAS International Conference on Telecommunications and Informatics (TELE-INFO ’07), Dallas, Texas, USA, March 22-24, 2007, 75-81.
- Минаков И.А. Скобелев П.О. Томин М.С. Мультиагентная система интеллектуальной обработки факсов, используемых для обмена бизнес-данными // Проблемы управления и моделирования в сложных системах: Тр. VIII Междунар. конф., Самара, 24 июня – 28 июня 2006. Самара: СНЦ РАН, 2006. С.510-515.
- Вольман С.И., Минаков И.А. Применение методов извлечения знаний в задачах транспортной логистики // Проблемы управления и моделирования в сложных системах: Тр. VIII Междунар. конф., Самара, 24 июня – 28 июня 2006. – Самара: СНЦ РАН, 2006. С.516-521.
- Minakov Igor, Rzevski George, Skobelev Petr, Volman Semen. Automatic Generation of Business Rules for Logistics Company using Multi-agent clustering // 1st International Conference on Business Information, Organisation and Process Management (BIOPoM 2006), Westminster Business School, University of Westminster London, June, 2006. http://www.wmin.ac.uk/wbs/pdf/BIOPoM_2006_Final_Programme2.pdf
- Minakov I., Tomin M., Volman S. Development of Multiagent Internet Meta-Search Engine // Международная конференция «ИТ в бизнесе» (ITIB), Санкт-Петербург, 14-17 июня 2005 г. http://itib.finec.ru/ru/05/
- Вольман С.И., Минаков И.А., Томин М.С. Мультиагентная система интеллектуального анализа содержимого Интернет-страниц // Проблемы управления и моделирования в сложных системах: Тр. VII Междунар. конф., Самара, 27 июня – 1 июля 2005. – Самара: СНЦ РАН, 2005. С.403-408.
- Вольман С.И., Карягин Д.В., Минаков И.А., Скобелев П.О. Разработка системы нахождения бизнес-правил с использованием кластеризации на примере данных логистической компании // Проблемы управления и моделирования в сложных системах: Тр. VII Междунар. конф. Самара, 27 июня – 1 июля 2005. – Самара: СНЦ РАН, 2005. С.409-413.
- Вольман С.И., Минаков И.А., Томин М.С. Увеличение эффективности поиска информации в Интернете с использованием формальных семантических дескрипторов текста // Интеллектуальные системы принятия решений и прикладные аспекты информационных технологий (ISDMIT'2005): Тр. Междунар. научной конф., Херсон, 18-21 мая 2005. – Херсон: Изд-во Херсонского морского ин-та, 2005. Т. 4. С. 102-105.
- Алексеев А., Вольман С., Минаков И., Орлов А., Томин М. Создание мультиагентной системы автоматической обработки, преобразования и коррекции логистических сообщений стандартных форматов обмена бизнес-данными // Проблемы управления и моделирования в сложных системах: Тр. VI Междунар. конф.Самара, 14-17 июня 2004. – Самара: СНЦ РАН, 2004. С.270-276.
- Андреев В., Лахин О., Минаков И., Сальков А., Скобелев П. Развитие элементов самоорганизации и эволюции в мультиагентном портале социокультурных ресурсов Самарской области // Проблемы управления и моделирования в сложных системах: Тр. VI Междунар. конф. Самара, 14-17 июня 2004. – Самара: СНЦ РАН, 2004. С.277-281.
- Андреев В., Ивкушкин К., Минаков И., Ржевский Г., Сафонов А., Скобелев П. Основные компоненты внутреннего устройства мультиагентной системы // Проблемы управления и моделирования в сложных системах: Тр. V Междунар. конф. Самара, 17-21 июня 2003. – Самара: СНЦ РАН, 2003. С. 304-316.
- Андреев В., Вольман С., Ивкушкин К., Карягин Д., Минаков И., Пименов А., Скобелев П., Томин М. Разработка мультиагентной системы интеллектуальной обработки и классификации документов // Проблемы управления и моделирования в сложных системах: Тр. V Междунар. конф. Самара, 17-21 июня 2003. – Самара: СНЦ РАН, 2003. С.317-323.
- Andrejev V., Batishchev S., Ivkushkin K., Minakov I., Rzevski G., Safronov A., Skobelev P. MagentA Multi-Agent Engines for Decision Making Support // International Conference on Advanced Infrastructure for Electronic Business, Science, Education and Medicine on the Internet (ISBN 88-85280-63-3), 29 July – 4 August 2002, L’Aquila, Italy, pp. 64-76.
- Андреев В., Батищев С., Ивкушкин К., Минаков И., Ржевский Г., Сафронов А., Скобелев П., Шамашов М. Принципы построения открытых мультиагентных систем для поддержки процессов принятия решений // Проблемы управления и моделирования в сложных системах: Тр. IV Междунар. конф. Самара, 17-24 июня 2002. С. 127 - 140.
- Андреев В., Гельфанд М., Ивкушкин К., Казаков А., Новичков П., Томин М., Вольман С., Минаков И., Скобелев П. Разработка мультиагентной системы интеллектуального поиска информации в области современных биотехнологий // Проблемы управления и моделирования в сложных системах: Тр. IV Междунар. конф. Самара, 17-24 июня 2002. – Самара: СНЦ РАН, 2002. С. 338 - 345.
- Batishev S.V., Ivkushkin C.V., Minakov I.A., Rzevski G.A., Skobelev P.O. MagentA Multi-Agent Systems: Engines, Ontologies and Applications // Proc. of the 3rd Intern. Workshop on Computer Science and Information Technologies CSIT’2001, Ufa, Russia, 21-26 September, 2001. – Ufa State Aviation Technical University – Institute JurInfoR-MSU, Vol. 1: Regular Papers, 2001, pp. 73-80.
- Ивкушкин К.В., Минаков Г.А., Ржевский Г.А., Скобелев П.О., Шамашов М.А. Транспортная логистика на основе мультиагентных систем // В кн.: Системная логистика и центр консолидации грузопотоков на международных трассах: Тр. 1-ой Междунар. научн.-практ. конф.. Вып. 1. - Самара, 2001. С. 120-129.
- Андреев В.В., Волхонцев Д.В., Ивкушкин К.В., Карягин Д.В., Минаков И.А., Ржевский Г.А., Скобелев П.О. Мультиагентная система извлечения знаний // Проблемы управления и моделирования в сложных системах: Тр. III Междунар. конф. Самара, 4-9 сентября 2001. – Самара: СНЦ РАН, 2001. С. 206 – 212.
- Андреев В.В., Ивкушкин К.В., Карягин Д.В., Минаков И.А., Ржевский Г.А., Скобелев П.О., Томин М.С. Разработка мультиагентной системы понимания текста // Проблемы управления и моделирования в сложных системах: Тр. III Междунар. конф. Самара, 4-9 сентября 2001. – Самара: СНЦ РАН, 2001. С. 489 - 495.
- Ivkushkin K., Minakov I., Rzevski G., Skobelev P. MA DAE: MagentA Multi-Agent Desktop Application Engine // Proceedings of the 3rd International Workshop on Computer Science and Information Technologies CSIT’2001, Ufa, Russia, 21-26 September, 2001. – Ufa State Aviation Technical University – Institute JurInfoR-MSU, Vol. 1: Regular Papers, 2001, pp. 81-89.
- Batishev S.V., Ivkushkin C.V., Minakov I.A., Rzevski G.A., Skobelev P.O. A Multi-Agent Simulation of Car Manufacturing and Distribution Logistics // Proc. of the II International Conference "Complex Systems: Control and Modelling Problems", Samara, Russia, June 20-23, 2000, pp. 100-104.
- Ивкушкин К.В., Минаков И.А., Ржевский Г.А., Скобелев П.О. Мультиагентная система для решения задач логистики // Тр. 7-й Национальной конф. по искусственному интеллекту с международным участием ИИ-2000, 24-27 октября 2000, Переславль-Залесский, Россия – М.: Физматлит, 2000, т. 2, с. 789-798.
- Кораблин М.А., Минаков И.А. Эволюционные алгоритмы в имитационном моделировании //Проблемы управления и моделирования в сложных системах: Тр. междунар. конф. Самара: СНЦ РАН, 1999. С. 45-50.
- Андреев В.В., Ивкушкин К.В., Карягин Д.В., Минаков И.А., Ржевский Г.А., Пшеничников В.В., Симонова Е.В., Скобелев П.О. Основы построения мультиагентных систем. Ч. I. Уч. пособие // Самара: ПГАТИ, 2005. 114 с.
Свидетельства о регистрации программ
- Свидетельство о регистрации программы № 2004610968 от 20 апреля 2004 г. Инструментальная система конструирования мультиагентных систем для десктопных приложений //В.В. Андреев, К.В. Ивкушкин, И.А. Минаков, Г.А. Ржевский, А.В. Сафронов, П.О. Скобелев.
- Свидетельство о регистрации программы № 2004610970 от 20 апреля 2004 г. Мультиагентная система понимания текстов на естественном языке //В.В. Андреев, И.А. Минаков, Г.А. Ржевский, П.О. Скобелев, М.С. Томин.
- Свидетельство о регистрации программы № 2004610966 от 20 апреля 2004 г. Мультиагентная система извлечения знаний методом кластеризации // С.И. Вольман, Д.В. Карягин, И.А. Минаков, Г.А. Ржевский П.О. Скобелев.
Автореферат отпечатан с разрешения диссертационного совета
Д212.217.03 (протокол № 10 от « 2 » июля 2007 г.)
Заказ № Тираж 100 экз.
Отпечатано в типографии ГОУ ВПО «Самарский государственный
технический университет»
443100, г. Самара, ул. Молодогвардейская, 244. Корпус № 8.