

Метод компрессии видеоизображений, основанный на использовании априорной информации о структуре кадра
На правах рукописи
Мироненко Евгений Петрович
МЕТОД КОМПРЕССИИ ВИДЕОИЗОБРАЖЕНИЙ, ОСНОВАННЫЙ НА ИСПОЛЬЗОВАНИИ АПРИОРНОЙ ИНФОРМАЦИИ О СТРУКТУРЕ КАДРА
Специальность: 05.13.01
“Системный анализ, управление и обработка информации
(в технике и технологиях)”
Автореферат
диссертации на соискание ученой степени
кандидата технических наук
Санкт-Петербург
2008 г.
Работа выполнена на кафедре информационно-сетевых технологий Государственного образовательного учреждения высшего профессионального образования “Санкт-Петербургский государственный университет аэрокосмического приборостроения” (ГУАП)
Научный руководитель:
доктор технических наук, профессор Красильников Николай Николаевич
Официальные оппоненты:
доктор технических наук, профессор Петров Павел Николаевич
кандидат технических наук, доцент Гласман Константин Францевич
Ведущая организация: ОАО Научно-производственное предприятие "Радар ММС"
Защита состоится “_17__” _февраля_ 2008 г. в __ час. __ мин. на заседании диссертационного совета Д 212.233.02 при Государственном образовательном учреждении высшего профессионального образования “Санкт-Петербургский государственный университет аэрокосмического приборостроения” по адресу: 190000, г. Санкт-Петербург, ул. Большая Морская, д. 67.
С диссертацией можно ознакомиться в библиотеке государственного образовательного учреждения высшего профессионального образования “Санкт-Петербургский государственный университет аэрокосмического приборостроения”
Автореферат разослан “_____” “____________” 2008 г.
Ученый секретарь диссертационного совета доктор технических наук, профессор Л. А. Осипов
ОБЩАЯ ХАРАКТЕРИСТИКА РАБОТЫ
Актуальность темы.
В настоящее время, в связи с широким распространением цифровой техники, быстро растет объем передаваемой и хранимой информации. Особенно это касается данных, относящихся к визуальной информации, наиболее широко используемой в различных сферах человеческой деятельности. Хранение визуальной информации требует больших объёмов памяти, а для ее передачи необходимо наличие каналов с высокой пропускной способностью.
Таким образом, одной из наиболее актуальных задач в области обработки видеоданных становится разработка и совершенствование методов компрессии этих данных.
Особенностью большинства современных алгоритмов компрессии видеоданных является то, что они разработаны для компрессии произвольных изображений. Вместе с тем, если тип изображений, для которых разрабатывается алгоритм компрессии, заранее известен, это обстоятельство может быть использовано для увеличения его эффективности. Другими словами, знание объектов, находящиеся в кадре, и способов их движения, дают возможность получить большую степень компрессии при сохранении необходимого качества изображения.
Таким образом, одним из основных направлений исследований в области компрессии является разработка методов компрессии, согласованных с содержанием видеоконтента с целью повышения эффективности их работы. В области компрессии видеоизображений реальных сцен, при условии обеспечения высокого качества результирующих изображений, процесс компрессии должен учитывать свойства зрительной системы человека как оконечного анализирующего устройства. Поэтому дополнительный интерес представляет детальное изучение работы зрительной системы при восприятии объектов реальных трехмерных сцен, с целью усовершенствования механизмов компрессии при сохранении высокого визуального качества.
Цель работы: целью работы является разработка и исследование алгоритма компрессии видеоданных, основанного на использовании априорной информации о структуре кадра видеоизображения и параметров объектов в кадре. Алгоритм включает в себя распознавание объекта в кадре видеопоследовательности, нахождение его характерных элементов и использование полученной информации для переноса на трёхмерную модель и её дальнейшей анимации в соответствии с движением объекта в исходной видеопоследовательности.
Задачи исследования: для достижения поставленной цели в работе решались следующие основные задачи и вопросы:
- Анализ существующих методов компрессии видеоданных. Выявление недостатков этих методов, в случае компрессии потокового видео с априорно известными объектами в кадре при условии обеспечения малых потерь в качестве и отсутствия эффекта накопления ошибок преобразования при многократной обработке.
- Исследование особенностей визуального восприятия трехмерных объектов и определение допустимых искажений при обеспечении высокого визуального качества.
- Разработка и исследование эффективного алгоритма для компрессии видеоданных на основе использования 3D модели, согласованного со зрительной системой человека.
- Экспериментальное исследование предложенных алгоритмов и оценка их эффективности.
Методы исследования: для достижения поставленной цели в диссертационной работе использовались методы системного анализа, методы цифровой обработки сигналов, теория дискретных сигналов, теория информации, математическая статистика и методы компьютерного моделирования.
Научная новизна:
- Разработан и исследован метод компрессии видеоданных, основанный на замене изображений объектов в кадре их трехмерными моделями.
- Проведен анализ эффективности применения современных методов компрессии видеоданных при обеспечении высокого визуального качества результирующих изображений.
- Проведено экспериментальное исследование эффективности зрительной системы человека в условиях распознавания трехмерных тестовых объектов, алфавит которых задан и ограничен.
- Определен уровень допустимых погрешностей для основных характеристик трехмерных объектов при их наблюдении.
Практическая ценность работы определяется тем, что предложенный алгоритм компрессии для видеоизображений с заранее определенными объектами в кадре позволяет получить больший выигрыш по сжатию, чем те, которые обеспечиваются известными методами компрессии движущихся изображений.
Основные положения, выносимые на защиту:
- Метод компрессии видеоданных, основанный на замене изображений объектов в кадре их трехмерными моделями.
- Алгоритм нахождения и определения параметров объектов в кадре видеоизображения
- Алгоритм адаптации шаблонной трехмерной модели объекта к параметрам визуального объекта в кадре видеоизображения
- Результаты исследования восприятия трехмерных объектов наблюдателем
Внедрение результатов работы: в учебном процессе Санкт-Петербургского государственного университета аэрокосмического приборостроения.
Апробация результатов работы. Основные положения и результаты диссертации докладывались и обсуждались на VIII, IX, X научных сессиях ГУАП (г. Санкт-Петербург 2005, 2006, 2007), IV Международной конференции “Телевидение: передача и обработка изображений” ЛЭТИ (г. Санкт-Петербург 2005), IV Межвузовской конференции молодых учёных ИТМО (г. Санкт-Петербург 2007), ECVP (Европейская конференция зрительного восприятия) (2005).
Публикации. По теме диссертации опубликовано 8 печатных работ, из них 3 в журналах, входящих в список ВАК.
Структура работы. Диссертационная работа изложена на 148 страницах и состоит из введения, 4-х разделов, заключения, списка использованных источников литературы, включающего 78 наименований. Основное содержание работы включает 49 рисунков и 13 таблиц.
СОДЕРЖАНИЕ РАБОТЫ
Во введении обоснована актуальность темы диссертации, сформулированы цели диссертационной работы и основные задачи, приведены основные положения, выносимые на защиту.
В первом разделе диссертационной работы ставится задача компрессии видеоизображения с обеспечением высокого качества восстановленной копии.
В первой части раздела производится обзор и анализ существующих алгоритмов, рассматриваются их достоинства и недостатки в применении к мультимедиа данным (в частности к компрессии видеоинформации).
Традиционные методы компрессии видеоданных «без потерь», основанные на статистических характеристиках изображений, не учитывают в достаточной степени специфику структуры кадра кодируемых видеопоследовательностей, что приводит в ряде случаев к существенному снижению коэффициентов компрессии. Увеличение эффективности работы таких методов можно получить за счет использования свойств внутрикадровой структуры (контекста) видеоизображения.
Методы компрессии изображений «с потерями», позволяют получать существенные коэффициенты сжатия, однако при возрастании величины коэффициента компрессии эти методы вносят в изображения дополнительные артефакты, например, регулярные структуры, изначально отсутствующие в оригинальном изображении, появление которых обусловлено доменным представлением изображения. Улучшение качества компрессии возможно за счет согласования структуры объектов исходного изображения и методов их преобразования. Для увеличения величины коэффициента компрессии изображений в случае алгоритмов компрессии с потерями информации помимо свойств источника информации, т.е. самого изображения, используются свойства приемника, которым в случае видеоизображений обычно является зрительная система человека.
В задачах компрессии видеоданных оригинальное изображение, поступающее на вход видеокомпрессора, рассматривается как массив данных отсчетов яркости для трех цветовых каналов![]() ,
, ![]() ,
, ![]() . По типу используемых преобразований, применяемых к оригинальным изображениям, современные алгоритмы компрессии можно разделить на две группы:
. По типу используемых преобразований, применяемых к оригинальным изображениям, современные алгоритмы компрессии можно разделить на две группы:
- Алгоритмы, основанные на представлении оригинального изображения в виде регулярной доменной структуры. Осуществляют компрессию за счет перераспределения энергии изображения внутри доменов (на основе дискретного косинусного преобразования (ДКП), на основе вейвлет преобразования (ДВП)) и адаптивное квантование на различное число уровней в зависимости от энергии каждой компоненты, а также кодирования межкадровой разности на основе данных движения каждого домена.
- Алгоритмы, использующие представление оригинального изображения в виде набора отдельных эталонных фрагментов, адаптированных к соответствующим объектам, составляющим кадр изображения. В данном случае компрессия может осуществляться за счет кодирования межкадровой разности набором фиксированных преобразований над моделями объектов, требующих для своего представления меньшего объема данных.
Методы компрессии второй группы позволяют более полно учитывать свойства изображения и получать большую степень компрессии при сохранении визуального качества восстановленного изображения. Однако, применение данных методов к любому типу изображений часто затрудняется наличием большого количества разнообразных объектов, составляющих структуру кадра. Таким образом, для компрессии параметров межкадровой разности требуется наличие большой базы данных возможных шаблонов объектов в кадре, а также разработки алгоритмов высокой сложности, позволяющих определить тип объекта в кадре и провести адаптацию шаблона к свойствам объекта в кадре изображения.
В качестве пути улучшения работы алгоритмов компрессии видеоизображений в работе рассматривается сегментация кадра изображения с целью группировки пикселей по признаку их принадлежности к объектам кадрового пространства и использование априорно известных параметров каждой группы для повышения эффективности предсказания локальных смещений и кодирования межкадровых различий в частности с использованием трехмерных моделей для представления объектов в кадре.
Вторая часть раздела посвящена вопросам эффективности восприятия трехмерных объектов зрительной системой человека. Необходимость детального анализа свойств зрительной системы обусловлена тем, что в рассматриваемой в диссертационной работе области применения декодированных изображений, последние предназначены для визуального восприятия человеком. В разделе представлен анализ свойств зрительной системы человека при восприятии изображений трехмерных сцен и её сравнение с моделью идеального наблюдателя, реализованной в виде компьютерной программы. Анализ проводился на основе экспериментальных данных, полученных в результате измерения коэффициента эффективности зрительной системы человека, который определяется следующим образом:
![]() ,
,
где ![]() ,
, ![]() - пороговые значения энергии изображения для идеального наблюдателя и человека-наблюдателя соответственно, которые обеспечивают правильное опознавание изображения с одной и той же вероятностью
- пороговые значения энергии изображения для идеального наблюдателя и человека-наблюдателя соответственно, которые обеспечивают правильное опознавание изображения с одной и той же вероятностью ![]() .
.
Результаты исследований, полученные в экспериментах, показали то, что отсутствие априорной информации о ракурсе предъявляемого для опознавания объекта, заметно снижает величину коэффициента эффективности, и что с увеличением уровня шума коэффициент эффективности уменьшается. Кроме того, было найдено, что при наблюдении изображений объектов, легко запоминающихся зрителю, коэффициент эффективности оказывается выше, чем в случае наблюдения сложных трудно запоминающихся в деталях объектов.
По результатам экспериментов было установлено, что коэффициент эффективности зрительной системы представляет собой очень малую величину, что указывает на то, что зрительная система очень неполно использует информацию, заложенную в изображении. За счет устранения неиспользуемой зрительной системой информации существует возможность более эффективной компрессии оригинального изображения без потери визуального качества.
Наиболее значимыми факторами при восприятии трехмерных объектов являются искажения формы и текстуры. Для определения точности их представления нами была проведена серия экспериментальных исследований.
В процессе экспериментального исследования восприятия формы трехмерных объектов зрительной системы были получены параметры пороговых значений для искажений формы трехмерных моделей различного характера, наиболее важными с точки зрения компрессии среди которых является искажение, обусловленное разряжением плотности полигональной сетки. Установлены пороговые значения границ для величины плотности сетки на примере модели человеческой головы.
В зависимости от вида искажений выявляется существенное различие между значениями пороговых относительных среднеквадратичных расстояний между оболочками искаженного и неискаженного объектов. Исследования, при которых в трехмерные объекты вносились как распределенные по поверхности объекта искажения, так и локальные, позволили прояснить природу этого феномена, заключающуюся в том, что зрительная система намного более чувствительна к локальным искажениям объекта, чем к распределенным искажениям.
Ряд экспериментов, позволяющих выявить степень влияния конкретной реализации текстуры опознаваемого объекта на величину коэффициента эффективности показал, что при опознавании реальных трехмерных объектов, как правило, имеющих текстуру, зрительная система человека не использует информацию, заключенную в конкретной реализации рисунка текстуры. Полученный результат говорит о том, что зрительная система при опознавании трехмерных объектов не использует информацию, заключенную в конкретной реализации рисунка текстуры. Но, как следует из проведенных дополнительных экспериментов, она использует такие ее статистические характеристики, как плотность вероятности первого порядка и коэффициент автокорреляции.
Второй раздел посвящен рассмотрению принципов, положенных в основу работы предложенного в диссертационной работе метода компрессии видеоданных. Рассмотрены основные этапы работы предложенного алгоритма и обозначена область его применения.
Область применения исследуемого алгоритма – компрессия видеоданных с априорно известными типами объектов и характером их движения (изменениями параметров) в кадре. За счет разделения изображения кадра видеопоследовательности на отдельные объекты, появляется возможность осуществлять компрессию видеоизображения с учетом характерных свойств, присущих каждому объекту в кадре, что позволяет повысить величину коэффициента компрессии без существенной потери качества результирующего изображения.
В диссертационной работе рассматривается применение предложенного метода в области видеотелефонии и видеоконференций. Особенностью подобных видеоизображений является то, что объекты, находящиеся в кадре, представляют собой фоновое изображение и изображение человека или нескольких людей, а движение в кадре представляет собой перемещение изображения человека по полю кадра и изменение мимики его лица. Трехмерная модель соответствует форме человеческой головы. Перемещение характерных элементов описывают мимику говорящего. В случае изображения человеческого лица характерными элементами являются антропометрические точки лица.
Компрессия заднего плана может быть реализована на базе алгоритмов JPEG или MPEG в зависимости от того, является ли задний план статичным или динамичным. Для компрессии объектов переднего плана в диссертационной работе предложен метод, использующий перенос параметров объекта в кадре и информации о его движении на трехмерную модель, представляющую собой полигональный шаблон, соответствующий по своим характеристикам оригинальному объекту в кадре, и дальнейшее кодирование переднего плана векторами анимации адаптированной модели.
Алгоритм кодирования видеопоследовательности включает в себя:
- обнаружение объекта в кадре и локализацию характерных элементов,
- адаптацию 3D модели к параметрам объекта в кадре,
- трассировку движения объекта и его характерных элементов,
- кодирование параметров структуры и движения модели и изображения фона.
Алгоритм декодирования осуществляет
- декодирование параметров структуры и движения модели и изображения фона,
- построение 3D модели в соответствии с положением объекта в кадре,
- текстурирование 3D модели,
- совмещение модели с фоном, соответствующим заднему плану видеоизображения.
Для передачи движения в первом кадре видеопоследовательности выносится решение о присутствии требуемого объекта в кадре, определяется его положение и выделяются характерные инвариантные элементы объекта, определяющие его свойства. В случае лица такими точками являются антропометрические точки.
Следующей этапом предлагаемого метода является правильная инициализация базовой трехмерной модели в кадре, т.е. адаптация полигональной сетки модели к форме исходного объекта и пространственное размещение модели в соответствии с положением оригинального объекта в кадре.
В общем случае проблему инициализации можно представить следующим образом: пусть B = (V; F) – полигональный триангулированный шаблон из N-вершин, представляющий трехмерную модель объекта, где ![]() набор вершин и
набор вершин и ![]() набор граней модели. B’ = (V’; F’) – шаблон B, модифицированный в соответствии с формой объекта в кадре видеопоследовательности. Преобразование B в B’ может быть представлено следующим образом:
набор граней модели. B’ = (V’; F’) – шаблон B, модифицированный в соответствии с формой объекта в кадре видеопоследовательности. Преобразование B в B’ может быть представлено следующим образом:
![]() ,
,
где ![]() - локальная трансформация полигонального шаблона,
- локальная трансформация полигонального шаблона, ![]() - глобальная трансформация шаблона,
- глобальная трансформация шаблона, ![]() - параметры всего объекта и его отдельных элементов.
- параметры всего объекта и его отдельных элементов.
Под глобальной трансформацией полигонального шаблона мы понимаем размещение в кадре адаптированной по форме полигональной модели в соответствии с положением оригинального объекта в кадре. Локальная трансформация полигонального шаблона позволяет адаптировать базовую модель к форме оригинального объекта. Очевидно, что локальная трансформация в общем случае не будет одинаковой для всех вершин ![]() модели B, а будет зависеть от особенностей формы оригинального объекта в кадре и расположения его характерных элементов. Применение локальной трансформации к базовому трехмерному шаблону позволяет нам получить персонифицированную (адаптированную к реальному объекту) трехмерную модель.
модели B, а будет зависеть от особенностей формы оригинального объекта в кадре и расположения его характерных элементов. Применение локальной трансформации к базовому трехмерному шаблону позволяет нам получить персонифицированную (адаптированную к реальному объекту) трехмерную модель.
На следующем этапе на 3D модель накладывается текстура, представляющая собой битовую карту с изображением объекта, находящегося в кадре последовательности.
Для передачи (сохранения) информации о глобальном движении достаточно определить векторы перемещения центра модели относительно координатных осей и углы поворота модели. Для передачи локального движения необходимо передавать данные об изменении положения каждой вершины полигональной сетки. Для уменьшения объема передаваемых данных передаются векторы движения не для всех вершин, а только для вершин, соответствующих характерным элементам объекта. Положение остальных вершин модели вычисляется путем взвешенного суммирования векторов анимации вершин, соответствующих основным антропометрическим точкам с весовыми коэффициентами, зависящими от свойств объекта.
При воспроизведении 3D модели, осуществляется её проекция на плоскость кадра с изображением заднего плана.
В третьем разделе рассматриваются вопросы локализации лица и его отдельных элементов в кадре видеопоследовательности. Для адаптации шаблонной трехмерной модели к объекту требуется вынести решение о его наличии в кадре, получить данные о его положении, вычислить параметры формы и текстуры лица и определить расположение основных антропометрических точек, данные о перемещении которых позволят описать мимику лица.
В первой части раздела проведен анализ современных алгоритмов локализации лиц и выработаны основные критерии, определяющие выбор метода сегментации для исследуемого алгоритма. К таким критериям относятся быстродействие алгоритма, определяющее возможность работы в реальном времени, необходимость точного определения положения антропометрических точек, возможность определения параметров формы по первому кадру изображения и возможность дальнейшего уточнения их положения в последующих кадрах. Также определен ряд допущений, позволяющий упростить алгоритм сегментации. К ним относятся фиксированное положение головы объекта в кадре на этапе локализации, который должен быть обращен лицом в сторону камеры (в фас), равномерная освещенность лица, отсутствие объектов, заслоняющих лицо.
В качестве признака, определяющего наличие лица в кадре и, позволяющего провести сегментацию, в работе выбрана цветовая характеристика изображения. Оптимальным цветовым пространством при построении маски лица является пространство ![]() . Главным достоинством работы в
. Главным достоинством работы в ![]() пространстве является то, что мы ограничиваем влияние яркостной компоненты изображения на дальнейшую обработку кадра. В
пространстве является то, что мы ограничиваем влияние яркостной компоненты изображения на дальнейшую обработку кадра. В ![]() пространстве каждая компонента характеризуется своей яркостью, а в случае
пространстве каждая компонента характеризуется своей яркостью, а в случае ![]() пространства яркость изображения описывается только компонентой
пространства яркость изображения описывается только компонентой ![]() , а
, а ![]() и
и ![]() составляющие являются независимыми от яркости.
составляющие являются независимыми от яркости.
Опираясь на данные экспериментальных исследований, проведенных на группе изображений лиц, определены оптимальные значения порогов цветоразностных компонент, на основании которых строится бинарная маска, соответствующая изображению лица.
Для удаления областей, попавших в границы цветовых интервалов, но не принадлежащих изображению лица (например, другие части тела или элементы одежды), дополнительно производится фильтрация по признаку формы и исключение из рассмотрения тех областей маски, соотношение сторон которых априорно не соответствует геометрическим параметрам лица.
В тех областях изображения, которые после первого этапа оказались сегментированы как изображения лица, требуется определить форму лица и положение характерных элементов. Для этих целей в работе используется метод активных контуров.
На этапе локализации характерных элементов лица в качестве наиболее важных при построении мимики и наиболее устойчивых к изменениям внешних условий мы выбрали изображения глаз и рта. В этом случае, на начальном кадре изображения требуется равномерно распределить вершины контуров вокруг каждого из этих элементов. В исследовании использовано по шесть равномерно распределенных вершин вдоль контура для рта, по шесть вершин для глаз и семь вершин для контура лица. Для нахождения оптимального положения каждой из этих вершин, применяется вычисленный методом главных компонент собственный вектор для каждой вершины ![]() , извлекая их образцы из базы данных, составленной на этапе обучения. Для каждой вершины контура
, извлекая их образцы из базы данных, составленной на этапе обучения. Для каждой вершины контура ![]() исследуется область вокруг её предполагаемого положения, минимизируется ошибка разности относительно соответствующего собственного вектора.
исследуется область вокруг её предполагаемого положения, минимизируется ошибка разности относительно соответствующего собственного вектора.
В определении метода активных контуров, контур представлен как набор вершин ![]() для i=0, …, N-1, где
для i=0, …, N-1, где ![]() и
и ![]() - x и y координаты i-й вершины. Энергия контура, которая должна быть минимизирована, определяется следующим выражением:
- x и y координаты i-й вершины. Энергия контура, которая должна быть минимизирована, определяется следующим выражением:
![]()
где ![]() - внутренняя энергия контура, обеспечивающая плавность его формы при прохождении через вершины,
- внутренняя энергия контура, обеспечивающая плавность его формы при прохождении через вершины, ![]() - внешняя энергия, определяющая прохождение контура через конкретные элементы на изображении.
- внешняя энергия, определяющая прохождение контура через конкретные элементы на изображении.
Для вычисления ![]() используют приближение второй производной:
используют приближение второй производной:

где ![]() =1, если
=1, если ![]() - не является угловым узлом и
- не является угловым узлом и ![]() =0, если является.
=0, если является. ![]() представляет максимальное значение, которое принимает приближение второй производной.
представляет максимальное значение, которое принимает приближение второй производной.
Присутствие величины ![]() позволяет обеспечить прохождение контура через характерные точки или контура на изображении. В работе был использован градиент интенсивности изображения вдоль контура от
позволяет обеспечить прохождение контура через характерные точки или контура на изображении. В работе был использован градиент интенсивности изображения вдоль контура от ![]() до
до ![]() и данные, полученные при вычислении положения вершины методом главных компонент
и данные, полученные при вычислении положения вершины методом главных компонент
![]() ,
,
где ![]() ,
, ![]() ,
, ![]() ,
, ![]() - подматрица матрицы главных векторов для вершины
- подматрица матрицы главных векторов для вершины ![]() , которая содержит
, которая содержит ![]() основных собственных векторов,
основных собственных векторов, ![]() . Пиксели, положение которых характеризуется минимальным значением ошибки, рассматриваются как возможные кандидаты для вершины
. Пиксели, положение которых характеризуется минимальным значением ошибки, рассматриваются как возможные кандидаты для вершины ![]() .
.
Для исследования алгоритма была разработана программа, реализующая поиск и сегментацию изображений лиц, полученных с различных источников. Исследование алгоритма проводилось на базе 50 фронтальных изображений лиц, размер нормированных изображений составил 200x350. Для определения эталонного положения узлов для каждого изображения была проведена ручная разметка. Наиболее подходящим критерием для оценки работы алгоритма является величина расстояния между положениями узлов, которое определил алгоритм в автоматическом режиме и истинным положением узла, определенным вручную.
В четвертом разделе рассмотрен алгоритм адаптации шаблонной трехмерной модели к реальному объекту в кадре видеопоследовательности и вопросы трассировки и передачи движения объекта в кадре видеопоследовательности, основанные как на анимации трехмерной модели в соответствии с мимикой и движением объекта в кадре, так и на методе ДКИМ.
Наличие априорных данных об объекте в кадре видеопоследовательности (голова говорящего человека в кадре) позволяет использовать в качестве точек, определяющих пространственную форму модели, антропометрические точки. Предлагаемый в работе алгоритм адаптации модели заключается в вычислении смещения вершин полигональной сетки шаблонной модели на основе информации о расположении антропометрических точек лица объекта в кадре видеопоследовательности. Для построения трехмерной формы в исследовании используется модель с плотностью полигональной сетки в диапазоне 2700-3100 вершин на объект.
Первая часть раздела посвящена вопросам инициализации шаблонной модели в соответствии с положением объекта в кадре видеопоследовательности. Пусть B = (V; F) – полигональный шаблон из N-вершин, представляющий голову человека, где ![]() набор вершин и
набор вершин и ![]() набор граней. Для вычисления величины деформации шаблонной модели, требуется вычислить смещение
набор граней. Для вычисления величины деформации шаблонной модели, требуется вычислить смещение ![]() для каждой вершины такое, что проекция деформированного полигонального шаблона
для каждой вершины такое, что проекция деформированного полигонального шаблона ![]() , с набором вершин
, с набором вершин ![]() , будет оптимально соответствовать изображению объекта в кадре видеопоследовательности. Для вычисления величины адаптивного смещения вершин можно использовать два параметра:
, будет оптимально соответствовать изображению объекта в кадре видеопоследовательности. Для вычисления величины адаптивного смещения вершин можно использовать два параметра:
1. Смещение вершин - ![]() ,
,
2. Регулирующий показатель - ![]() .
.
Форма лица, адаптированная к оригинальному изображению ![]() , может быть выражена следующим образом:
, может быть выражена следующим образом:
![]()
где коэффициент ![]() определяет влияние регулирующего показателя на модификацию модели и подбирается экспериментально.
определяет влияние регулирующего показателя на модификацию модели и подбирается экспериментально.
Смещение вершин определяется следующим выражением:
![]()
где ![]() - матрица первых m главных компонент,
- матрица первых m главных компонент, ![]() - коэффициенты главных компонент формы.
- коэффициенты главных компонент формы.
На этапе адаптации подразумевается, что для восстановления формы объекта на шаблонной модели отобраны T характерных вершин, положение которых соответствует положению антропометрических точек на лице объекта в кадре. Величина смещения для остальных вершин полигонального шаблона вычисляется на основе коэффициента удаления от контрольной вершины по следующей формуле:
![]()
где ![]() - смещение контрольной вершины k адаптированной модели относительно эталонной,
- смещение контрольной вершины k адаптированной модели относительно эталонной, ![]() – коэффициент, позволяющий учитывать удаление вершины n от контрольной вершины k, и характеризующий уменьшение влияния данной контрольной вершины на деформируемую.
– коэффициент, позволяющий учитывать удаление вершины n от контрольной вершины k, и характеризующий уменьшение влияния данной контрольной вершины на деформируемую.
Проекция координат характерных вершин на оригинальное изображение ![]() , где
, где ![]() - вектор перемещения вершин, а
- вектор перемещения вершин, а ![]() - коэффициент масштабирования.
- коэффициент масштабирования.
![]() ,
,
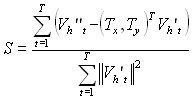 .
.
По найденным значениям ![]() ,
, ![]() и
и ![]() вычисляется значение
вычисляется значение ![]() .
.
На втором шаге вычисляется вектор коэффициентов главных компонент формы ![]() :
:
![]() ,
,
Подставляя новое значение ![]() в выражение
в выражение ![]() , можно вычислить новое значение для координат вершин антропометрических точек адаптируемой шаблонной модели.
, можно вычислить новое значение для координат вершин антропометрических точек адаптируемой шаблонной модели.
Коэффициент формы ![]() сводится к фиксированному значению за 8-10 итераций.
сводится к фиксированному значению за 8-10 итераций.
Для компенсации неравномерного распределения вершин по модели, необходимо добавить, регулирующий параметр Er, который скомпенсирует большое смещение между соседними вершинами на полигональном шаблоне.
![]()
Для генерации текстуры в работе использовалась ортогональная проекция оригинального изображения, соответствующая области лица на трехмерную модель. Для восстановления этой информации о текстуре на участках модели, скрытых от камеры используется алгоритм линейной интерполяции, который позволяет заполнить пустые области на основе текстурных данных из известных областей.
- Во второй части раздела рассматриваются вопросы трассировки объекта в последующих кадрах и вычисления параметра смещения
 , определяющего правила движения модели и изменение её формы в соответствии с объектом в кадре. Для оценки движения в кадре видеопоследовательности его целесообразно разделить на два типа: глобальное движение всего объекта и локальное движение антропометрических точек, определяющих мимику.
, определяющего правила движения модели и изменение её формы в соответствии с объектом в кадре. Для оценки движения в кадре видеопоследовательности его целесообразно разделить на два типа: глобальное движение всего объекта и локальное движение антропометрических точек, определяющих мимику.
В диссертационной работе для определения глобального движения использована ошибка компенсации движения (![]() ) для определения перемещения всего объекта в кадре видеопоследовательности вдоль вертикальной и горизонтальной сторон кадра.
) для определения перемещения всего объекта в кадре видеопоследовательности вдоль вертикальной и горизонтальной сторон кадра.
 ,
,
где ![]() и
и ![]() - яркость пикселя в текущем и предыдущем кадре соответственно. Область поиска блока в новом кадре имеет размер
- яркость пикселя в текущем и предыдущем кадре соответственно. Область поиска блока в новом кадре имеет размер ![]() по вертикали и горизонтали соответственно.
по вертикали и горизонтали соответственно. ![]() координаты x и y блока в предыдущем кадре. По полученным данным вычисляется средний вектор смещения объекта. Расчет значений углов поворота объекта осуществляется на основе информации о смещении осей лица объекта в кадре видеоизображения.
координаты x и y блока в предыдущем кадре. По полученным данным вычисляется средний вектор смещения объекта. Расчет значений углов поворота объекта осуществляется на основе информации о смещении осей лица объекта в кадре видеоизображения.
Для определения положения основных антропометрических точек в последующих кадрах видеопоследовательности требуется вычислить энергию контура аналогично тому, как это было сделано для первого кадра видеопоследовательности. Первое слагаемое суммы представляет собой величину градиента по периметру контура, а второе образец текстуры, взятый из предыдущего кадра последовательности в области, где был расположен узел контура. Выражение для вычисления внешней энергии контура примет следующий вид:
![]()
Для переноса глобального движения на 3D модель вектор ![]() умножается на матрицы аффинных преобразований с параметрами углов и смещений, полученных на этапе трассировки. Для переноса локального движения аналогичная операция проводится для вершин вектора
умножается на матрицы аффинных преобразований с параметрами углов и смещений, полученных на этапе трассировки. Для переноса локального движения аналогичная операция проводится для вершин вектора ![]() , содержащего информацию только о координатах антропометрических точек модели лица.
, содержащего информацию только о координатах антропометрических точек модели лица.
Для нахождения положения остальных вершин модели лица в работе предложен метод, использующий адаптивную сегментацию лица на гибкие области. И использование карт влияния контрольных вершин на соседние с ними области модели. Под термином “карта влияния” рассматривается набор коэффициентов, определяющих параметры перемещения вершин модели относительно движения контрольных вершин.
В качестве базового стандарта для представления данных модели в диссертационной работе выбран формат.obj.
- Предложенный алгоритм кодирования анимации модели на основе векторов движения контрольных вершин на практике позволяет получить выигрыш в 3,5-100 раз относительно существующих алгоритмов. Эффективность предложенного алгоритма возрастает при работе с моделями сложной формы, характеризующихся высокой плотностью полигональной сетки. При использовании алгоритма контрольных вершин для компрессии данных анимации модели плотность полигональной сетки оказывает влияние на общий объем передаваемых данных лишь для коротких последовательностей. В случае длинных последовательностей (60 секунд и более) объем данных определяется в основном количеством контрольных точек модели и выравнивается для моделей различной степени сложности.
- В третьей части раздела приводятся результаты экспериментального исследования работы предложенного алгоритма, а также алгоритмов ДКИМ и форматов OBJ и VRML. Показано, что эффективность алгоритмов ДКИМ и предложенный в работе алгоритм анимации контрольных вершин возрастает с увеличением длительности последовательности кадров.
Пятый раздел посвящен экспериментальному исследованию предложенного метода и алгоритмов в составе системы компрессии видеоизображений. Для исследования был отобран набор из нескольких видеопоследовательностей, удовлетворяющих условиям, сформулированным в начале работы. Исходные видеопоследовательности представляли собой изображения, взятые из различных источников видеосигнала. Для сравнения с исследуемым методом были отобраны следующие современные методы видеокомпрессии – Tiff, RAR, MJPG, MPEG2, H264.
Файл видеопоследовательности, подвергнутый компрессии предложенным методом, включает в себя:
- Изображение заднего плана, представленное в формате записи JPEG
- Текстуру лица, представленную в формате записи JPEG
- 3D-модель объекта в кадре видеопоследовательности
- Информацию о глобальном движении объекта и параметры движения основных антропометрических точек в каждом кадре
Результаты экспериментов представлены в таблицах 1 и 2:
Табл.1. Объем данных (в мегабайтах) для видеопоследовательностей 1 и 2 при использовании различных компрессоров.
| Длительность | Некомпрессированный AVI файл | Компрессия без потерь информации | Компрессия с потерями информации | Исследуемый алгоритм | ||||||||||
| TIFF | Арифметическое кодирование (RAR) | MJPEG (Quality 30% bitrate 1,2Мб/с) | H.264 (Quality 30% bitrate 0,039Мб/с) | MPEG2 (bitrate 0,5Мб/с) | ||||||||||
| Последовательность 1 | ||||||||||||||
| 1сек | 3,38 | 2,87 | 1,36 | 0,092 | 0,042 | 0,063 | 0,701 | |||||||
| 10сек | 33,7 | 29,2 | 14,1 | 0,89 | 0,39 | 0,69 | 0,738 | |||||||
| 60сек | 203 | 173,9 | 83,5 | 5,26 | 2,28 | 8,41 | 0,955 | |||||||
| Последовательность 2 | ||||||||||||||
| 1сек | 32 | 26,3 | 7,68 | 0,79 | 0,35 | 0,136 | 0,729 | |||||||
| 10сек | 324 | 265 | 75,2 | 7,92 | 3,42 | 3,58 | 0,766 | |||||||
| 60сек | 1944 | 1523 | 449,9 | 47,4 | 20,5 | 25,6 | 0,983 | |||||||
Табл.2. Величина PSNR для видеопоследовательностей 1 и 2 при использовании различных компрессоров, кодирующих данные с потерей информации
| PSNR для различных компрессоров | ||||
| № последовательности | MJPEG (Quality 30% bitrate 1,2Мб/с) | H.264 (Quality 30% bitrate 0,039Мб/с) | MPEG2 (bitrate 0,5Мб/с) | Исследуемый алгоритм |
| 1 | 37,66 | 31,39 | 32,03 | 35,47 |
| 2 | 39,62 | 33,77 | 33,14 | 29,95 |
Коэффициент компрессии предлагаемого метода, основанного на передаче параметров анимации модели, пропорционален длительности видеопоследовательности. Так как в заголовке файла исследуемого метода передается информация о параметрах 3D модели и изображение заднего плана. В случае малой длительности видеопоследовательности данная служебная информация составляет большую часть файла. При увеличении длительности видеопоследовательности доля служебной информации снижается относительно, что приводит к росту коэффициента компрессии. Величина коэффициента компрессии, обеспечиваемого предложенным методом, лежит в диапазоне от 4,8 до 1977 раз в зависимости от длительности видеопоследовательности (длительность последовательностей в исследовании менялась в диапазоне от 1 до 60 сек.).
Также к достоинству предложенного метода можно отнести малую зависимость коэффициента компрессии от разрешения исходного видеоизображения. Так как объем данных, описывающих движение в кадре, определяется только количеством антропометрических точек лица, используемых для передачи мимики объекта, то при увеличении разрешения оригинального изображения увеличится только размер заголовка файла, в котором содержится информация об изображении заднего плана и текстуре объекта. Такое изменение в значительной степени скажется только на коротких видеопоследовательностях, в которых размер заголовка составляет значительную часть от общего размера файла.
Для исследуемого метода характерной оказалась зависимость величины PSNR от положения объекта в кадре видеопоследовательности. Величина PSNR для исследуемого метода колеблется в пределах от 42 до 25 дБ в зависимости от положения объекта в кадре. Значения PSNR для остальных методов в исследовании не имели такой жесткой зависимости от перемещения объекта. При значительных отклонениях положения головы объекта в кадре от первоначального значения PSNR для исследуемого метода уменьшается. Данный факт возможно объяснить тем, что при построении модели использовалась информация с первого кадра изображения, в котором отсутствовала часть данных, касающихся формы и текстуры объекта в областях скрытых от камеры. Также при восстановлении изображения в работе не учитывалось расположение источников освещения относительно объекта в реальной сцене. Виртуальная модель освещалась заполняющим бестеневым источником белого цвета, который равномерно освещает модель со всех сторон.
В заключении сформулированы основные результаты диссертационной работы.
Основные результаты и выводы
В работе были получены следующие основные результаты:
- Проведен анализ современных методов компрессии данных «без потерь» и «с потерями информации» применительно к области сжатия видеоизображений реальных сцен с априорно известными типами объектов в кадре при условии обеспечения высокого качества результирующих изображений. На основе проведенного исследования были выявлены основные достоинства и недостатки существующих алгоритмов компрессии.
- На основании анализа существующих методов компрессии предложен и исследован метод, использующий априорную информацию о типе изображения и характере поведения объектов в кадре, для обеспечения степени компрессии, значительно превосходящую ту, которую позволяют получить известные методы. Предложенный метод основывается на замене изображения оригинального объекта на трехмерную модель, адаптированную по своим параметрам к исходному объекту, анимация которой описывается некоторым набором функций, отражающих поведение оригинального объекта в кадре видеопоследовательности.
- Для определения параметров трехмерных моделей, проведена серия экспериментов, направленных на исследование проблемы восприятия трехмерных объектов наблюдателем. Экспериментально определена необходимая точность представления полигональной сетки трехмерных моделей объектов различной формы. Проведена оценка чувствительности зрительной системы человека к различного рода искажениям модели, затрагивающим как геометрическую форму, так и параметры текстуры.
- Показано, что дополнительная компрессия данных о параметрах модели возможна за счет отказа от использования текстуры оригинального объекта, вместо которой может быть использована битовая карта, синтезированная по данным о статистических характеристиках текстуры исходного объекта.
- Предложен и исследован алгоритм нахождения и определения параметров лица в кадре видеоизображения, в основе которого лежит цветовая сегментация объекта и локализация основных антропометрических точек лица. Для определения параметров лица используется метод активных контуров.
- Разработан алгоритм адаптации и трассировки движения шаблонной трехмерной модели объекта к параметрам визуального объекта в кадре видеоизображения.
ОСНОВНЫЕ ПУБЛИКАЦИИ ПО ТЕМЕ ДИССЕРТАЦИИ
- Мироненко Е.П. Алгоритм дифференциальной кодово-импульсной модуляции в задачах компрессии цифрового потока данных, описывающих движение 3D модели // журнал Известия вузов - Приборостроение, 2008 (в печати )
- Н.Н. Красильников, Е.П. Мироненко Исследование погрешностей восприятия формы при наблюдении 3D объектов //Оптический журнал. - 2006. - Т. 73, № 5. - c. 18 - 24.
- Н.Н. Красильников, Е.П. Мироненко, О.И. Красильникова Коэффициент эффективности зрительной системы человека при произвольных ракурсах наблюдения трехмерных объектов //Оптический журнал. - 2006. - Т. 73, № 10. - c. 63 - 68.
- Мироненко Е.П. Влияние формы трехмерного объекта на формирование образа в коре головного мозга // Сборник докладов 8-й научной сессии аспирантов ГУАП. Технические науки. – СПб.: ГУАП, 2005,
- Мироненко Е.П. Применение алгоритма дифференциальной кодово-импульсной модуляции при сохранении информации о движении и мимики 3D модели человеческой головы // Сборник докладов 9-й научной сессии аспирантов ГУАП. Технические науки. – СПб.: ГУАП, 2006,
- Мироненко Е.П. Метод распознавания лица в задачах компрессии видеоизображений // Сборник докладов 10-й научной сессии аспирантов ГУАП. Технические науки. – СПб.: ГУАП, 2007,
- Мироненко Е.П., Красильников Н.Н. Оценка точности восприятия трехмерных объектов наблюдателем// Материалы 4-ой международной конференции «Телевидение: передача и обработка изображений», СПб, 2005. С. 56-57.
- Krasilnikov N.N., Mironenko E.P. Investigation of accuracy of 3D representation of a 3D object shape in the human visual system // ECVP European Conference on Visual Perception, Corua, Spain 2005