

Разработка и исследование методов и алгоритмов кластеризации для систем анализа данных
На правах рукописи
Елизаров Сергей Иванович
разработка и Исследование методов и алгоритмов кластеризации для систем анализа данных
Специальность: 05.13.18 – Математическое моделирование, численные методы и комплексы программ
АВТОРЕФЕРАТ
диссертации на соискание ученой степени
кандидата технических наук
Санкт-Петербург – 2008
Работа выполнена в Санкт-Петербургском государственном электротехническом университете "ЛЭТИ" имени В.И. Ульянова (Ленина).
Научный руководитель –
доктор технических наук, профессор Куприянов Михаил Степанович.
Официальные оппоненты –
доктор технических наук, профессор Сенилов М. А.
кандидат технических наук, доцент Балтрашевич В. Э.
Ведущая организация – ОАО ‘Интелтех” (г. Санкт-Петербург).
Защита состоится "___" __________ 200 г. в ____часов на заседании совета по защите докторских и кандидатских диссертаций Д 212.238.01 Санкт-Петербургского государственного электротехнического университета "ЛЭТИ" имени В.И. Ульянова (Ленина) по адресу: 197376, Санкт-Петербург, ул. Проф. Попова, 5.
С диссертацией можно ознакомиться в библиотеке Санкт-Петербургского государственного электротехнического университета "ЛЭТИ" имени В.И. Ульянова (Ленина).
Автореферат разослан “____” ___________ 200 г.
| Ученый секретарь совета по защите докторских и кандидатских диссертаций | ||
| к.т.н, доцент | М. Г. Пантелеев |
Общая характеристика работы
Актуальность. Настоящая работа посвящена разработке и исследованию методов и алгоритмов кластеризации, широко используемой в системах интеллектуального анализа данных. Синонимами термина интеллектуальный анализ данных являются добыча данных (data mining), обнаружение знаний (knowledge discovery). Интеллектуальный анализ данных связан с поиском в данных скрытых нетривиальных и полезных закономерностей, позволяющих получить новые знания об исследуемых данных. Особенный интерес к методам анализа данных возник в связи с развитием средств сбора и хранения данных, позволившим накапливать большие объемы информации. Перед специалистами из разных областей человеческой деятельности встал вопрос об обработке собираемых данных, превращения их в знания. Известные статистические методы покрывают лишь часть нужд по обработке данных, и для их использования необходимо иметь четкое представление об искомых закономерностях. В такой ситуации методы интеллектуального анализа данных приобретают особую актуальность. Их основная особенность заключается в установлении наличия и характера скрытых закономерностей в данных, тогда как традиционные методы занимаются главным образом параметрической оценкой уже установленных закономерностей. Среди методов интеллектуального анализа данных особое место занимают классификация и кластеризация. Классификация, при известной заранее группировке данных на подмножества (классы), устанавливает закономерность, по которой данные группируются именно таким образом. Кластеризация же, основываясь на установленном отношении схожести элементов, устанавливает подмножества (кластеры), в которые группируются входные данные. В широком круге задач нашли свое применение методы нечеткой кластеризации, в которых элементы входного множества относят к тому или иному кластеру на основании значения функции принадлежности. Нечеткая кластеризация одна из наиболее проработанных методик интеллектуального анализа данных. Однако, традиционные методы нечеткой кластеризации не дают приемлемых решений на данных со сложной внутренней структурой. Это связано с рядом допущений, закладываемых в эти методы: кластеры имеют заданную форму и особую внутреннюю точку – центр кластера; разбиение определяется, исходя из взаимосвязей между данными и центрами кластеров. Так как кластеры в общем случае могут быть произвольной формы и не иметь центров, актуальной является разработка метода кластеризации, свободного от указанных допущений и обеспечивающего разбиение только на базе отношений на исследуемых данных.
Задача кластеризации имеет различные способы решения. Сложность заключается в отсутствии на момент начала анализа какой-либо дополнительной информации о данных. В связи с этим возможное множество решений по мощности сопоставимо с входным множеством, что на практике неприемлемо. Для качественного и быстрого решения задачи кластеризации необходимы методики выбора наилучших решений. Поэтому особую актуальность имеет разработка методики адаптивной кластеризации, при которой выбор наилучшего решения осуществляется формально, по заданным критериям.
Целью диссертационного исследования является разработка методов и алгоритмов кластеризации, не требующих предварительной информации о кластерах, для систем анализа данных.
В процессе достижения поставленной цели решались следующие задачи:
- анализ проблем, возникающих при применении методов кластеризации;
- разработка метода и алгоритма кластеризации на базе нечеткого отношения эквивалентности;
- разработка критериев качества кластеризации, пригодных для построения адаптивной системы;
- разработка методики адаптивной кластеризации.
Методы исследования. Методологической базой явились работы по методам кластеризации, в том числе посвященные практическим аспектам их применения. В работе использован математический аппарат теории нечетких множеств, методы дискретной и вычислительной математики.
Основные положения, выносимые на защиту:
- Определения нечетких отношений, порождаемых только на основании свойств исследуемых данных.
- Метод и алгоритм кластеризации данных на базе нечеткого отношения эквивалентности, не требующие дополнительной информации о кластерах и не привлекающие понятий центра и формы кластера.
- Методика адаптивной кластеризации, формализующая решение задачи, в том числе, оценку качества каждого разбиения и выбор наилучшего из них.
Научную новизну работы составляют:
- определения нечетких отношений толерантности и эквивалентности, позволяющие порождать их из свойств исследуемых данных;
- метод и алгоритм кластеризации на базе нечеткого отношения эквивалентности, основанные на отношениях, порождаемых данными, и не делающие допущений о форме кластеров и наличии в них центров, и, следовательно, лишенные недостатков традиционных методов;
- критерии качества кластеризации, пригодные для построения адаптивной системы;
- методика адаптивной кластеризации, основанная на использовании критериев оценки качества решения и позволяющая полностью формализовать решение задачи кластеризации. Отличительной особенностью методики является оценка качества каждого разбиения и выбор наилучшего из них. Кроме того, данная методика и рекомендации по ее применению позволяют значительно сократить ресурсы, затрачиваемые на анализ данных.
Обоснованность и достоверность полученных результатов обеспечивается корректностью применяемого математического аппарата, строгими доказательствами предложенных теорем и утверждений; согласованностью получаемых результатов при использовании предложенных методов и алгоритмов с результатами применения известных подходов на тестовых примерах и задачах.
Практическая значимость работы состоит в том, что предложенные метод и алгоритм кластеризации на базе нечеткого отношения эквивалентности позволяют эффективно выявлять в данных кластеры произвольной формы; приведенные в работе критерии позволяют оценить качество решений задачи кластеризации, получаемых как при помощи традиционных методов, так и при помощи нового метода предлагаемого в работе; описанная в работе методика адаптивной кластеризации и рекомендации по ее применению позволяют значительно формализовать анализ данных и сократить затрачиваемые на него ресурсы; реализованная в составе системы мобильных агентов методика адаптивной кластеризации позволяет повысить уровень эффективности применения системы для решения задач интеллектуального анализа данных.
Реализация и внедрение результатов работы. Результаты диссертационного исследования внедрены в отделе контроля качества петербургского филиала ЗАО «Моторола ЗАО», что подтверждено актом о внедрении. Кроме того, результаты работы использованы в рамках реализации проекта министерства образования и науки Российской Федерации по теме: «Многоагентная технология интеллектуального анализа данных и извлечения знаний», код проекта 75103, а также проекта «Разработка теории и методов исследования самовосстанавливающихся систем» аналитической ведомственной целевой программы «Развитие научного потенциала высшей школы» министерства образования и науки Российской Федерации, код проекта 2.1.2.7828.
Апробация работы. Основные положения и результаты диссертационной работы докладывались и обсуждались на международных конференциях по мягким вычислениям и измерениям SCM’2006 и SCM’2007, Санкт-Петербург, 2006-2007 г.г, конференциях профессорско-преподавательского состава СПбГЭТУ «ЛЭТИ», Санкт-Петербург, 2004-2007 г.г.
Публикации. Основные теоретические и практические результаты диссертации опубликованы в 4 работах, среди которых 1 работа в ведущих рецензируемых изданиях, рекомендуемых в действующем перечне ВАК, 2 – разделы книг, 1 работа – в материалах международной конференции.
Структура и объем диссертации. Диссертация состоит из введения, 4 глав с выводами и заключения. Она изложена на 147 листах машинописного текста и содержит 61 рисунок, 5 таблиц, 2 приложения, список литературы из 59 наименований.
Основное содержание работы
Во введении обоснована актуальность, научная новизна и практическая значимость работы, изложены цели, задачи и методы диссертационного исследования.
Первая глава носит обзорный характер. Раздел 1.1 посвящен рассмотрению задач интеллектуального анализа данных. Интеллектуальный анализ данных – область знаний, относящаяся к обработке данных, изучающая поиск и описание скрытых, нетривиальных и практически полезных закономерностей в исследуемых данных. Среди задач интеллектуального анализа данных выделяют задачи классификации, кластеризации, регрессии, в том числе задачи прогнозирования, и поиска ассоциативных правил.
В разделе 1.2 даны формальные постановки задач интеллектуального анализа данных.
В задачах регрессии и классификации требуется определить значение зависимой переменной объекта на основании значений других переменных, характеризующих данный объект.
Пусть дано конечное множество объектов I = {i1,i2,…,ij,…in}. Каждый из объектов характеризуется некоторым признаковым описанием (x1,x2,…,xk,…,xm,xm+1). Пусть значения признаков (x1,x2,…,xk,…,xm) известны. Тогда задача заключается в определении неизвестного признака xm+1. Если его множество значений конечно, то задачу называют классификацией, а если счетно или имеет мощность континуума, то говорят о задаче регрессии.
Задача поиска ассоциативных правил заключается в обнаружении часто встречающихся наборов объектов в большом множестве таких наборов, а также закономерностей в их появлении.
Дано конечное множество объектов I = {i1,i2,…,ij,…in} и каждому наблюдаемому событию соответствует некоторое подмножество Th множества I, которое назовем событием. Рассмотрим множество D всех наблюдаемых событий. Пусть мощность D равна m. Множество событий, в которых наблюдался объект ij, обозначим Di = {Tr: ijTr, j = 1…n, r = 1…m}D. Множество событий, в которые входит набор объектов F, обозначим DF = {Tr: FTr, r = 1…m}D. Отношение количества событий, при которых наблюдался набор объектов F, к общему количеству событий называют поддержкой набора F и обозначают Supp(F). Задача поиска ассоциативных правил состоит в поиске наборов F, поддержка которых превышает некоторое минимальное пороговое значение: L = {F: Supp(F) > Suppmin}.
Одним из частных случаев рассматриваемой задачи является анализ последовательностей. Его основным отличием от поиска ассоциативных правил является задание отношения порядка на множестве объектов I.
Задача кластеризации заключается в разбиении множества объектов на группы по некоторым признакам. Полученные группы называют кластерами.
Дано конечное множество объектов I = {i1,i2,…,ij,…in}. Каждый из объектов характеризуется m-компонентным признаковым описанием (x1,x2,…,xk,…,xm), xkXk, где Xk – допустимое множество значений признака. Требуется построить множество кластеров C и отображение F: IC. Кластер chC имеет структуру ch = {ij,ip: ij,ipI, d(ij,ip)<}, т.е. кластер состоит из объектов, находящихся в пространстве признаков рядом в смысле метрики d и определяется величиной.
Раздел 1.3 посвящен обзору методов интеллектуального анализа данных. Методы интеллектуального анализа данных опираются на математический аппарат классической теории множеств, теории нечетких множеств, математической статистики, нейронных сетей, а также разнообразные эмпирические методики. Алгоритмическое решение формализованной задачи интеллектуального анализа данных связано с различными задачами поиска: экстремума целевой функции, вида целевой зависимости.
В разделе 1.4 поясняется особое место кластеризации среди прочих задач интеллектуального анализа данных, рассматриваются известные методы кластеризации, выявляются недостатки и их причины.
На практике часто возникает задача первичного анализа, когда о внутренних зависимостях в данных ничего неизвестно. В таких условиях первой задачей анализа, требующей решения, является задача кластеризации, т.е. выявление внутренней структуры в данных, на основании которой в дальнейшем можно будет формулировать более детальные задачи о поиске зависимостей, влияющих на группировку данных в исходном множестве.
Известно большое число методов кластеризации, которые делятся на иерархические и неиерархические, среди которых наибольшее распространение получили методы разбиения. Общими для методов разбиения являются: расстояние как метод сравнения данных, множество центров кластеров и матрица принадлежности как основные результаты работы алгоритма, функционал, минимизация которого определяет решение, а также набор ограничений. Среди методов разбиения наиболее известны методы k-средних, Fuzzy C-Means и кластеризация по Гюстафсону-Кесселю. Первый отличается тем, что получаемые с его помощью значения матрицы принадлежности являются четкими (принимают значения из множества {0,1}). Fuzzy C-Means и кластеризация по Гюставсону-Кесселю – нечеткие методы кластеризации, в них матрица принадлежности состоит из соответствующих значений функций принадлежности нечетким кластерам. Отличие этих методов проявляется в форме кластеров, которыми они оперируют. Fuzzy C-Means порождает кластеры сферической формы, а кластеризация по Гюстафсону-Кесселю – эллипсоиды.
Данные алгоритмы, несмотря на различия, очень сходны и обладают общими недостатками: извлечение кластеров только заданной алгоритмом формы, что не позволяет обнаруживать другие кластеры; использование в решении понятия центра кластера, хотя в ряде задач они могут отсутствовать; построение разбиений, исходя из отношений между элементами данных и центрами кластеров.
Глава 2 посвящена разработке метода нечеткой кластеризации, призванного преодолеть недостатки известных методов. Данная цель достигается при помощи привлечения аппарата нечетких отношений.
В разделе 2.1 производится рассмотрение нечетких отношений и их свойств. Вводятся специальные нечеткие множества и отношения.
Мера сходства по расстоянию (1) и нормальная мера сходства (2) порождают нечеткие множества точек близких к y
![]() , (1)
, (1)
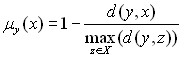 , (2)
, (2)
где x,y,zX.
Достоинство нормальной меры сходства заключаются в том, что для каждого xX существует, по крайней мере, один образец данных, который абсолютно схож с ним (при этом y(x) = 1) и один образец данных, максимально отличающийся от x (при этом y(x) = 0).
Опираясь на нормальную меру можно определить относительную меру сходства двух образцов данных относительно третьего (3).
y(x,z) = 1 – |y(x) – y(z)|, (3)
где x,y,zX, а y – нормальная мера сходства.
Легко показать, что каждое отношение из данного семейства отношений является нечетким отношением толерантности.
Через относительную меру сходства можно определить меру сходства двух образцов данных на всем множестве X, которая определяется через следующее высказывание: «если два образца сходны относительно y1 и … и сходны относительно y|X|, то два образца данных сходны относительно всего множества X» и записывается как (4)
(x,z) = T(y1(x,z),…,y|X|(x,z)) (4)
где T – t-норма, yi(x,z) - относительная мера сходства, yiX, i = 1,…,|X|, x,zX. Таким образом, построено нечеткое отношение толерантности, которое объективным образом показывает сходство между объектами из множества X.
Нечеткое отношение эквивалентности получается путем вычисления транзитивного замыкания нечеткого отношения толерантности. Для этого доказан ряд теорем и утверждений.
Теорема 1. Если отношение R – отношение нечеткой толерантности, то справедливо следующее утверждение RR2…Rn…
Теорема 2. Транзитивное замыкание ![]() , вычисляемое как наименьшая верхняя граница объединения отношений Ri, для отношения нечеткой толерантности R на множестве X равно отношению R|X|.
, вычисляемое как наименьшая верхняя граница объединения отношений Ri, для отношения нечеткой толерантности R на множестве X равно отношению R|X|.
Теорема 3. Объединение отношений нечеткой толерантности есть также отношение нечеткой толерантности.
Утверждение 1. Транзитивное замыкание отношения нечеткой толерантности порождает отношение нечеткой эквивалентности на множестве X.
Утверждение 2. Задание уровня нечеткой эквивалентности порождает разбиение множества X на классы эквивалентных элементов таким образом, что каждый элемент X принадлежит точно одному классу эквивалентности.
Учитывая вышесказанное, был предложен алгоритм кластеризации (рис. 1), использующий нечеткое отношение эквивалентности и состоящий из следующих шагов:
- построить для каждого образца данных нормальную меру сходства (2);
- построить относительно каждого образца данных на основании нормальной меры сходства относительную меру сходства (3) для пар образцов данных;
- построить меру сходства образцов данных на множестве X (4), взяв в качестве t-нормы min-норму:
(x,z) = min(y1(x,z),…,y|X|(x,z)),
которая является нечетким отношением толерантности на множестве X, x,yi,zX, i = 1,…,|X|;
- построить транзитивное замыкание отношения нечеткой толерантности, вычисляемое в следующему цикле:
![]() ,
,
где R = (x,z), x,zX, i = 2,…,|X|; в результате получим
![]() ,
,
которое по утверждению 1 является отношением нечеткой эквивалентности;
- построить для отношения нечеткой эквивалентности шкалу, как упорядоченное по возрастанию множество различных элементов матрицы этого отношения.
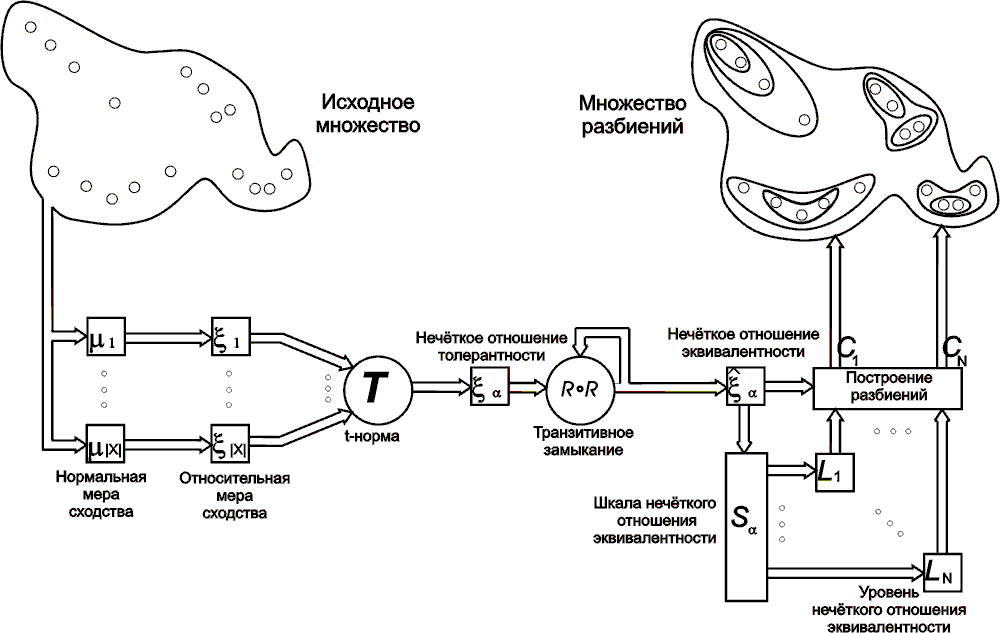 |
| Рис. 1. Схема работы алгоритма. |
Шкала отношения нечеткой эквивалентности порождает семейство отношений эквивалентности в классическом смысле, каждое из которых разбивает исходное множество на классы эквивалентности. Для более высокого уровня отношения свойственно более детальное разбиение множества X.
Глава 3 посвящена преодолению сложностей, возникающих при использовании алгоритмов кластеризации. Эти сложности в большой степени связаны с необходимостью указывать количество кластеров до начала анализа, что не всегда можно сделать обоснованно. В связи с этим особое значение имеют критерии оценки качества решения задачи кластеризации.
Разделы 3.2 и 3.3 посвящены анализу известных критериев, применяемых для центроидной кластеризации. Первый рассматриваемый критерий – коэффициент разбиения:
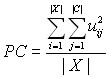 ,
,
где uij – соответствующий элемент матрицы принадлежности, X – входное множество, С – множество кластеров. Данный критерий принимает значения из [|C| 1,1], причем значению |C| 1 соответствует худший случай разбиения (максимальной неопределенности), а значению 1 – максимально четкое разбиение. Было замечено, что на малых значениях количества кластеров, коэффициент разбиения дает ошибочные результаты, что связано с его областью значений. Не меняя характера критерия, его область значений была сдвинута таким образом, чтобы зависимость от количества кластеров была связана не началом указанного отрезка, а с его окончанием. Это сделано путем вычитания из коэффициента разбиения |C| 1. Полученный критерий
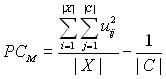
– модифицированный коэффициент разбиения, область его значений лежит в отрезке [0, (|С| – 1)/C].
Далее в работе рассматривается энтропия разбиения:
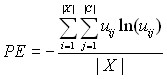 ,
,
где uij – соответствующий элемент матрицы принадлежности, X – входное множество, С – множество кластеров. Диапазон значений критерия – [0, ln |C|], причём наилучшему разбиению соответствует 0, а наихудшему – ln |C|. Сравнивать разные решения при помощи этого критерия некорректно, поскольку его диапазон значений для каждой кластеризации будет разным. Более правильным будет использовать модифицированную энтропию разбиения:
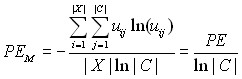 .
.
Ее диапазон значений не связан с количеством кластеров и лежит в отрезке [0,1]. Таким образом, при помощи данного критерия можно сравнивать кластеризации с разным количеством кластеров.
Последним в группе центроидных критериев рассматривается эффективность разбиения:
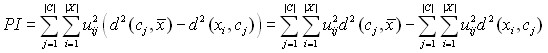
где ![]() – среднее значение элементов входного множества, cj – центр кластера j. Критерий состоит из двух частей: первая показывает межкластерные отличия, чем они выше, тем лучше выполнена кластеризация, а вторая – внутрикластерные отличия, чем они меньше, тем лучше выполнена кластеризация. Таким образом, чем больше значения критерия, тем лучше выполнена кластеризация.
– среднее значение элементов входного множества, cj – центр кластера j. Критерий состоит из двух частей: первая показывает межкластерные отличия, чем они выше, тем лучше выполнена кластеризация, а вторая – внутрикластерные отличия, чем они меньше, тем лучше выполнена кластеризация. Таким образом, чем больше значения критерия, тем лучше выполнена кластеризация.
При анализе критериев было сделан вывод о целесообразности использования на практике модифицированного коэффициента разбиения, модифицированной энтропии разбиения, эффективности разбиения.
Разделы 3.4 и 3.5 посвящены проблеме выбора наилучшего решения задачи кластеризации, выполненной с использованием нечеткого отношения эквивалентности. Для этой цели был разработан критерий, названный качеством разбиения. При разработке критерия было введено понятие практически полезного кластера – кластера, входящего в группу наиболее мощных кластеров. Необходимость введения этого понятия вытекает из того, что классы эквивалентности значительно различаются по мощности (особенно в начале шкалы нечеткой эквивалентности), причем большее число из них состоит из небольшого количества элементов. Группа практически полезных кластеров определяется как:
Cc = {ciC: |ci|TH},
где сi – класс эквивалентности, С – множество классов эквивалентности, а TH –порог мощности, вычисляемый при помощи специальной процедуры.
Определив группу практически полезных кластеров, вычисляется коэффициент разбиения – отношение суммарной мощности практически полезных кластеров к общей мощности множества.
Используя понятия уровня отношения эквивалентности, практически полезных кластеров и коэффициента разбиения формулируется критерий оценки качества: наилучшим разбиением назовем такое разбиение, для которого качество разбиения (5) достигает максимума.
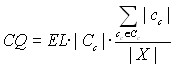 (5)
(5)
где EL – уровень эквивалентности, Cc = {сс} – множество практически полезных кластеров, а последний множитель – коэффициент разбиения. Данный критерий учитывает следующее:
- чем выше этот уровень эквивалентности, тем более схожи объекты внутри классов эквивалентности, тем качественнее разбиение;
- чем мощнее множество практически полезных кластеров, тем лучше разбиение;
- чем он выше коэффициент разбиения, тем больше элементов вошли в результирующее разбиение, что повышает качество разбиения.
В разделе 3.6 формулируется методика адаптивной кластеризации, состоящая из 6 шагов:
- предварительная подготовка данных;
- определение целей анализа;
- определение средств анализа и способа представления результатов;
- нормирование данных;
- формулирование ограничений, выбор критериев оценки качества решения;
- применение адаптивной кластеризации и анализ результатов.
Предварительная подготовка данных заключается в выборе множества для анализа и выделении атрибутов, по которым будет производиться анализ. Эти атрибуты должны кратко и полно описывать исследуемое множество, остальные же, как не несущие полезной для анализа информации, исключаются из рассмотрения.
Цели анализа выбираются из следующего набора:
- Определение кластерного состава данных. При этом определяются количество и состав кластеров. Как правило, это основная цель решения задачи кластеризации.
- Выявление отклонений, т.е. поиск элементов множества, которые нельзя отнести ни к одному из кластеров. Они указывают на аномалии в процессе, породившие исследуемые данные.
- Подготовка к решению задачи классификации, которая в дополнение к определению кластерного состава данных предполагает обязательную постобработку результатов с целью дать названия и описания полученным кластерам. Поименованные и описанные кластеры – классы, а установление зависимостей между значениями атрибутов элементов множества и их принадлежностью кластерам – решение задачи классификации.
Определение средств анализа и способа представления результатов. Средствами анализа могут выступать различные программные системы. Например, для проведения исследования критериев использовалась среда Matlab, для решения задачи анализа распределенных данных использовалась многоагентная система и библиотека алгоритмов XELOPES.
Способ представления результатов может быть одним из нижеследующих.
- Простое перечисление. Каждый кластер описывается перечислением своих элементов. Применимо при использовании любого метода кластеризации.
- Дендрограмма. Получается естественным образом при использовании иерархических методов, а также метода нечеткого отношения эквивалентности. Для центроидной кластеризации, в общем случае, данный способ представления результатов неприменим.
- Матрица принадлежности. Представляет результаты кластеризации в виде таблицы, где строки соответствуют элементам, а столбцы кластерам. Ячейки таблицы содержат значения соответствующих функций принадлежности. Этот способ представления результатов является естественным для центроидной кластеризации.
Подготовка данных. Подготовка данных – технологический этап, состоящий из перевода категориальных данных в числовые и нормирования числовых данных в диапазоне [0,1]. Перевод категориальных данных в числовые производится взвешиванием или упорядочиванием. Взвешивание производится экспертом предметной области путем приписывания числовых значений категориальным атрибутам. Упорядочивание менее эффективная стратегия, но не требует привлечения эксперта. При ее использовании каждому из значений категориального атрибута приписывается порядковый номер. В случае сомнения в правильности использования стратегии упорядочивания и невозможности использовать знания эксперта, возможно, лучше исключить атрибут из рассмотрения. Нормирование числовых данных необходимо, чтобы каждый из атрибутов имел равный вес при сравнении данных. В случае, когда вес атрибутов разный, это необходимо учитывать при нормировании.
Формулировка ограничений, критериев оценки качества решения. Ограничения накладываются на возможное значение числа кластеров, получаемых в результате кластеризации. Это полезно с точки зрения сокращения ресурсов, затрачиваемых на кластеризацию. Выбор критерия, для оценки качества решения задачи, может быть сделан на основании рекомендаций, данных в диссертации.
Применение адаптивной кластеризации и анализ результатов. Основной по затрачиваемым ресурсам частью адаптивной кластеризации является выполнение алгоритма, который, последовательно перебирая значения количества кластеров из заданного диапазона, выполняет кластеризацию и вычисляет значения выбранных критериев. Производится анализ множества экстремумов каждого из критериев и выбирается наилучшее разбиение. Таким образом, получается основной результат адаптивной кластеризации – разбиение на кластеры. Далее, в зависимости от поставленных целей может быть выполнен поиск отклонений, проведена подготовка к классификации. Если результаты анализа удовлетворяют поставленным целям, анализ завершается, иначе, производится новая итерация, начиная с одного из предыдущих этапов.
Глава 4 посвящена применению полученных в работе результатов. Подробно описано применение методики адаптивной кластеризации в рамках анализа данных о процессе разработки программного обеспечения в петербургском филиале ЗАО «Моторола ЗАО». Кроме того, разрабатывается многоагентная система для интеллектуального анализа данных, в ходе реализации которой были использованы положения диссертации, в частности, критерии оценки качества решения задачи кластеризации и методика адаптивной кластеризации.
Заключение
Данная диссертационная работа посвящена разработке и исследованию методов и алгоритмов кластеризации. Особое внимание было уделено адаптивной кластеризации. Итогом работы стали следующие основные научные и практические результаты:
- определения нечетких отношений толерантности и эквивалентности, порождаемых из свойств исследуемых данных и составляющих основу предложенного метода кластеризации;
- метод и алгоритм кластеризации на базе нечеткого отношения эквивалентности, которые не делают допущений о форме кластеров и наличии в них центров и лишены недостатков традиционных методов; алгоритм кластеризации на базе нечеткого отношения эквивалентности позволяет эффективно выявлять в данных кластеры произвольной формы; отношения, используемые в ходе решения задачи кластеризации, задаются в соответствии с конструктивными определениями, предложенными в работе.
- критерии качества кластеризации, пригодные для построения адаптивной системы;
- методика адаптивной кластеризации, основанная на использовании критериев оценки качества решения и позволяющая полностью формализовать решение задачи кластеризации. Отличительной особенностью методики является оценка качества каждого разбиения и выбор наилучшего из них. Кроме того, данная методика и рекомендации по ее применению позволяют значительно сократить ресурсы, затрачиваемые на анализ данных;
- многоагентная система интеллектуального анализа данных, в ходе реализации которой были использованы положения диссертации, в частности, критерии оценки качества решения задачи кластеризации и методика адаптивной кластеризации. Экспериментальное исследование, проведенное с использованием данной системы, подтвердило достоверность и эффективность результатов, полученных в работе.
Публикации по теме диссертации
Публикации в изданиях, рекомендованных ВАК России:
- Елизаров С. И., Куприянов М. С., Холод И. И. Самонастраивающиеся агенты для интеллектуального анализа распределенных данных // Известия Санкт-Петербургского государственного электротехнического университета «ЛЭТИ» им. В. И. Ульянова (Ленина) №2 2006. – СПб.: Изд-во СПбГЭТУ «ЛЭТИ», 2006. – С. 3-7. (Личный вклад: адаптивная методика для самонастройки агентов).
В других изданиях:
- Елизаров С. И. Кластеризация данных при помощи нечетких отношений // Баргесян А. А., Куприянов М. С., Степаненко В. В., Холод И. И. Методы и модели анализа данных: OLAP и Data Mining. – СПб.: БХВ-Петербург, 2004. – С.174-207.
- Елизаров С. И. Адаптивные методы кластеризации // Баргесян А. А., Куприянов М. С., Степаненко В. В., Холод И. И. Технологии анализа данных: Data Mining, Visual Mining, Text Mining, OLAP. – СПб.: БХВ-Петербург, 2007. – С.168-174.
Материалы конференций:
- Елизаров С. И. Адаптивные методы нечеткой кластеризации // Сб. докл.: Международная конференция по мягким вычислениям и измерениям. – СПб.: Изд-во СПбГЭТУ «ЛЭТИ», 2007. – Т.2. – С.234-237.