

Модели и алгоритмы организации темпорального хранилища данных (на примере телекоммуникационной компании)
На правах рукописи
Спандерашвили Дмитрий Викторович
МОДЕЛИ И АЛГОРИТМЫ ОРГАНИЗАЦИИ ТЕМПОРАЛЬНОГО ХРАНИЛИЩА ДАННЫХ (НА ПРИМЕРЕ ТЕЛЕКОММУНИКАЦИОННОЙ КОМПАНИИ)
Специальность:
05.13.10 - "Управление в социальных и экономических системах"
АВТОРЕФЕРАТ
диссертации на соискание ученой степени
кандидата технических наук
Астрахань - 2006
Работа выполнена в
Астраханском государственном университете
| НАУЧНЫЙ РУКОВОДИТЕЛЬ: | доктор технических наук, профессор Петрова Ирина Юрьевна |
| ОФИЦИАЛЬНЫЕ ОППОНЕНТЫ: | доктор технических наук, профессор Дворянкин Александр Михайлович кандидат технических наук, доцент Лаптев Валерий Викторович |
| ВЕДУЩАЯ ОРГАНИЗАЦИЯ: | Поволжская государственная академия телекоммуникаций и информатики |
Защита диссертации состоится 23 декабря 2006 г. в 13 час. 00 мин. на заседании диссертационного Совета ДМ 212.009.03 в Астраханском государственном университете по адресу: 414056, г. Астрахань, ул. Татищева, 20А, конференц-зал.
Отзывы на автореферат в двух экземплярах, заверенные гербовой печатью, просим направлять ученому секретарю диссертационного совета по адресу: 414056, г. Астрахань, ул. Татищева 20А, АГУ.
С диссертацией можно ознакомиться в библиотеке университета.
Автореферат разослан 21 ноября 2006 г.
Ученый секретарь
Диссертационного Совета,
д.т.н., проф. Петрова И.Ю.
Общая характеристика работы
Актуальность темы
В течение последних лет в телекоммуникационных компаниях значительно увеличилась динамика внедрения принципиально новых услуг. По данным группы компаний ОАО «Связьинвест», представленным на рис. 1, отмечается устойчивое увеличение превалирования доли новых услуг по сравнению с традиционными.

Рис. 1. Динамика изменения соотношения традиционных и новых услуг связи в телекоммуникационной отрасли (по данным группы компаний "Связьинвест")
Процесс принятия решений, касающихся развития компании, должен опираться на достоверные и актуальные данные о деятельности компании. Существенное влияние на качество принимаемых решений имеет глубина анализа данных. Таким образом, основными задачами систем поддержки принятия решений (DSS, Decision Support Systems) является предоставление достоверных данных за наиболее продолжительный непрерывный временной интервал.
Высокие темпы внедрения новых технологий приводят к регулярным структурным изменениям в телекоммуникационных компаниях. Динамичность организационной структуры, а также постоянная модернизация и смена применяемых технологий создает определённые трудности при анализе эффективности функционирования телекоммуникационных компаний, т.к. в описанных условиях существенно уменьшается глубина анализа данных.
В большинстве крупных компаний для долгосрочного анализа, сбора и хранения данных в настоящее время внедряют системы OLAP(On-Line Analytical Processing) – системы оперативной аналитической обработки. OLAP системы на сегодняшний день можно отнести к числу наиболее динамично развивающихся сегментов рынка информационных технологий. Согласно исследованию, проведенному «The OLAP Report», которое было посвящено обзору рынка средств OLAP, оборот рынка аналитических приложений в 2005 году составил $4,9 млрд., рост по сравнению с 2004 годом достиг 13,7 процентов. Динамика роста оборота рынка OLAP-систем представлена на рис. 2.

Рис. 2. Динамика роста объемов рынка OLAP-систем (данные «The Olap Report»)
Фундаментом и, во многих случаях, составной частью OLAP систем, определяющим качественные возможности проведения анализа данных, является расширяемое, целостное хранилище данных (DW, Data Warehouse), способное не только аккумулировать данные продолжительное время, но и предоставлять OLAP системе возможность проводить анализ данных произвольных интервалов временной оси. Хранилище данных компании является одним из уровней иерархии систем, задействованных в принятии решений, представленной на рис. 3. Каждый уровень иерархии использует сервисы, предоставляемые всеми нижними уровнями.
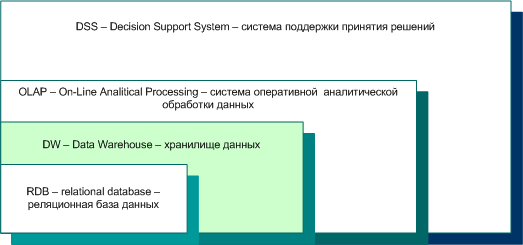
Рис. 3. Иерархия систем, участвующих в принятии решений
Подавляющее большинство современных OLAP-систем использует в качестве логической модели данных n-мерный куб (гиперкуб). Данные в гиперкубе представлены в виде числовых значений (мер) и распределены по измерениям, которые определяют величины, описывающие данные.
При функционировании компании в элементах и структуре измерений многомерной модели данных происходят изменения: добавление, изменение, удаление, дробление и объединение элементов измерений; добавление и удаление измерений; изменения в иерархических связях элементов измерений – в случае иерархических измерений. Все эти изменения должны быть учтены, так как в анализ могут быть вовлечены как данные актуальные в момент до изменения в измерениях, так и данные актуальные в момент после изменения измерений. Несмотря на модификации в структуре и элементах измерений, информация о предыдущих состояниях измерения должна оставаться в системе и участвовать в анализе.
Увеличить глубину анализа возможно при наличии механизмов отслеживания изменений в многомерных структурах данных. Такие механизмы используются в темпоральном хранилище данных (TDW, Temporal Data Warehouse). Вопросы организации темпоральных хранилищ данных в настоящее время недостаточно освещены в научной литературе, особенно в части промышленного применения. В промышленных OLAP-системах проблема отслеживания изменений в структуре измерений также практически не решается, или решается на довольно примитивном уровне с использованием классических подходов к отслеживанию изменений в медленно меняющихся измерениях.
Большой вклад в формирование основ многомерного представления данных и классических подходов к отслеживанию изменений в измерениях внесли работы учёных: Б. Инмона (B. Inmon, США), Р. Кимболла (R. Kimball, США), Н. Пендса (N. Pendse, США), Т. Педерсена (T. Pedersen, США). Исследованиями в области темпоральных баз данных (TDB, Temporal Data Bases) занимались М. Бехлен (M. Bhlen, Германия), С. Дженсен (С. Jensen, США), Р. Снодграс (R. Snodgras). Работы по исследованию темпоральных хранилищ данных (TDW, Temporal Data Warehouse – темпаральное хранилище данных) и битемпоральных хранилищ данных (BTDW, Bi-Temporal Data Warehouse – би-темпоральное хранилище данных) ведутся в настоящий момент следующими учеными: Й. Эдер (J. Eder, Австрия), Х. Концилиа (Ch. Koncilia, Австрия), Т. Морзий (T. Morzy, Польша), Г. Коглер (H. Kogler, Австрия), однако единый подход к построению TDW пока отсутствует.
Отсутствие средства организации данных телекоммуникационной компании в условиях динамичных структурных и технологических изменений, недостаточная разработанность вопросов построения темпорального хранилища данных, отсутствие исследования полного цикла функционирования темпорального хранилища данных, включая процессы внедрения и реализации процесса ETL (Extract Transform Load – «извлечение-трансформация-загрузка»), позволяют сделать вывод об актуальности исследования данной темы.
Цель работы и задачи исследования
Целью диссертационного исследования является создание многомерной модели организации данных для системы поддержки принятия решений, позволяющей увеличить глубину анализа в условиях изменений в структуре измерений на основе разработки моделей и алгоритмов темпорально-многомерного хранения информации.
Для достижения поставленной цели необходимо решить следующие задачи:
- Исследовать вопросы консолидированного хранения информации телекоммуникационной компании для её удобного краткосрочного и долгосрочного анализа, произвести классификацию используемой информации;
- Исследовать технологии построения многомерных хранилищ данных, возможности классических подходов контроля изменений в измерениях многомерных структур данных, исследовать технологии построения темпоральных баз данных;
- Построить модель темпорального хранилища данных и схему базы данных, позволяющие реализовать принципы темпорально-многомерного хранения информации на основе реляционной СУБД.
- Разработать и реализовать в виде программной системы алгоритмы, обеспечивающие функционирование темпорального хранилища данных телекоммуникационной компании.
- Проверить достоверность предложенных моделей и алгоритмов на реальных и тестовых данных.
Методы исследования
При решении поставленных задач использовались методы: системного анализа, объектно-ориентированного анализа и проектирования, объектно-ориентированного программирования, теории баз данных, теории графов, методы построения и анализа алгоритмов.
Научная новизна
Результаты диссертационной работы характеризуются научной новизной:
- Дано формальное описание трансформации куба данных в темпоральном хранилище данных, позволяющее осуществлять трансформацию данных одной структурной версии в структуру другой структурной версии, способствуя увеличению глубины анализа;
- Разработана объектно-реляционная модель темпорального хранилища данных и структуры данных темпорального хранилища данных, позволяющие реализовать темпорально-многомерную модель данных средствами реляционной СУБД, а также осуществить программную реализацию темпорального хранилища данных;
- Разработаны алгоритмы, позволяющие решить практические вопросы функционирования темпорального хранилища данных: алгоритм перехода с существующих систем хранения информации на темпоральное хранилище данных; алгоритм трансформации куба данных; алгоритм трансформации данных в процессе переноса данных из оперативных регистрирующих систем с использованием матриц трансформации.
Практическая ценность работы
В результате диссертационного исследования разработаны структура, математическое и программное обеспечение системы хранения данных телекоммуникационной компании, обеспечивающие интегральное хранение многомерной информации, предоставляющие инструменты отслеживания многократных стохастических изменений в структуре измерений многомерной модели.
Применение предложенных методов и алгоритмов позволяет: сократить сроки анализа деятельности телекоммуникационной компании, за счёт применения централизованного хранилища информации; увеличить качество результатов анализа, на основе увеличения глубины анализа, за счет применения механизмов отслеживания изменений в структуре данных; обеспечить преемственность при миграции с существующей многомерной схемы хранения данных, на предложенную темпорально-многомерную, за счет применения механизма структурных версий.
Реализация и внедрение результатов работы
Результаты работы реализованы в программном продукте «Автоматизированная система сбора и обработки статистических данных телекоммуникационной компании» (свидетельство о регистрации №2006611990), которая внедрена (приказ о введении в промышленную эксплуатацию №34 от 01.02.2005) и используется в региональном филиале ОАО «ЮТК» «Связьинформ» Астраханской области (г. Астрахань).
Полученные научные результаты и практические методы реализации темпорально-многомерного хранилища данных обладают высокой степенью универсальности и могут быть использованы не только в рассмотренной области применения – построения хранилища данных региональной телекоммуникационной компании, но и в широком спектре сфер деятельности, требующих хранения и анализа информации за длительный период времени, а также в научно-исследовательской деятельности при исследовании вопросов построения хранения и анализа данных.
Апробация работы
Научные результаты и положения диссертационной работы докладывались и обсуждались на следующих конференциях: региональной научно-методической конференции «Информатика: проблемы, методология, технологии» (Воронеж, 2005), всероссийской научной конференции «Проблемы стратегии регионального развития» (Тамбов, 2006), международной научно-технической конференции «Инфокоммуникационные технологии в науке и технике» (Ставрополь, 2006), международной научно-технической конференции «Информационные технологии в науке, образовании и производстве» (Орел, 2006), всероссийской конференции «Фундаментальные исследования в технических университетах» (Санкт-Петербург, 2006).
Публикации
Основное содержание диссертации отражено в 9 публикациях.
Структура и объем работы
Диссертационная работа состоит из введения, четырех глав, заключения, списка использованной литературы из 127 наименований. Диссертационная работа изложена на 143 страницах машинописного текста, содержит 53 рисунка, 3 таблицы и 4 приложения.
Основное содержание работы
Во введении обосновывается актуальность выбранной темы диссертационной работы, формулируется цель и содержание поставленных задач, формулируется объект и предмет исследования, научная новизна и практическая значимость полученных результатов, излагаются методы исследования, дается краткое содержание глав работы.
В первой главе проводится анализ систем обработки данных в компании, рассматриваются системы оперативной и аналитической обработки данных, определяется место хранилища данных в процессе обработки данных. Анализируется информация в телекоммуникационной компании, производится ее классификация, определяются потоки информации в телекоммуникационной компании до и после введения централизованного хранилища данных. Проводится сравнение основных архитектур построения хранилищ данных.
Дано описание систем оперативной регистрации транзакций – OLTP (On-Line Transaction Processing – оперативная обработка транзакций), рассмотрены их особенности, роль и место в обработке данных телекоммуникационной компании. Отмечена неэффективность использования OLTP систем для проведения анализа деятельности предприятия.
Рассмотрены системы оперативной аналитической обработки – OLAP (Online Analytical Processing – оперативная аналитическая обработка). Сформулированы основные характеристики, которым должна соответствовать OLAP система, место OLAP системы в обработке данных телекоммуникационной компании. Отмечена важность наличия хранилища данных – DW (Data Warehouse – хранилище данных) с пространственной организацией данных для эффективного функционирования OLAP систем. Дана обобщённая схема взаимодействия OLTP, OLAP и DW. Определена роль и место DW в обработке данных телекоммуникационной компании.
Приведены результаты анализа типов информации, используемой в телекоммуникационной компании. Произведена классификация типов информации как по назначению, так и по характеру и периодичности фиксации.
Произведён анализ потоков информации в телекоммуникационной компании при отсутствии централизованного хранилища информации и при его наличии, результаты представлены в виде обобщённых схем потоков информации между подразделениями компании.
Схема потоков информации в телекоммуникационной компании, приведенная на рис. 4, характеризуется необходимостью получения информации непосредственно из регистрирующих систем, или у филиалов.

Рис. 4. Потоки информации до введения централизованного хранилища данных
Данный подход имеет ряд недостатков:
- неоднородность источников получения информации для анализа приводит к неоднозначности предоставляемых данных;
- существует необходимость взаимодействия служб дирекции непосредственно со службами филиалов;
- существует необходимость взаимодействия коммерческих служб с техническими, так как некоторые коммерческие показатели требуют анализа технических и наоборот;
- существует опасность дублирования информации, так как несколько служб могут предоставлять информацию, описывающую один объект, но, ввиду различия точек фиксации его параметров, информация может различаться;
- избыточность во взаимосвязях между службами компании ведет к снижению производительности труда.

Рис. 5. Потоки информации после введения централизованного хранилища данных
При введении единого хранилища данных устраняются многие проблемы сбора и анализа информации (рис. 5):
- устраняются излишние взаимосвязи между коммерческими и техническими службами;
- устраняется возможность дублирования данных, так как при внесении данные проходят очистку посредством анализа правильности ввода и наличия определенного регламента взаимодействия с пользователями;
- повышается производительность труда, так как часть данных из оперативных баз данных автоматически преобразуется и переносится в хранилище аналитической информации;
- службы дирекции для анализа информации больше не обращаются к оперативным базам данных;
- часть функций по анализу данных, группировке данных, агрегации и построению отчетов берет на себя хранилище данных.
В диссертационной работе доказана эффективность применения централизованного хранилища данных.
Для доказательства эффективности применения централизованного хранилища данных в диссертационной работе рассмотрена компания, состоящая из центрального отделения – дирекции и нескольких филиалов. Пусть количество отделов филиала и дирекции совпадает, таким образом, во всех количество отделов равно. Также введем допущение, что в компании существует всего два типа информации: коммерческая и техническая.
Введем следующие обозначения:
 – количество филиалов;
– количество филиалов; – количество технических служб в каждом отделении компании;
– количество технических служб в каждом отделении компании; – количество коммерческих служб в каждом отделении компании;
– количество коммерческих служб в каждом отделении компании; – количество регистрирующих систем технического сектора;
– количество регистрирующих систем технического сектора; – количество регистрирующих систем коммерческого сектора;
– количество регистрирующих систем коммерческого сектора;
Тогда, в случае отсутствия хранилища данных:
- количество транзакций при взаимодействии каждой службы с регистрирующей системой своего сектора рассчитывается по формуле (1);
| | (1) |
(умножение на два, т.к. обмен информацией двусторонний, пользователи как вводят, так и берут информацию);
- количество транзакций при взаимодействии отделов технического и коммерческого сектора всех филиалов и дирекции рассчитывается по формуле (2);
| | (2) |
- количество транзакций при взаимодействии отделов филиала с дирекцией рассчитывается по формуле (3);
| (3) |
- общее количество транзакций (4):
 | (4) |
В случае применения хранилища данных:
- количество транзакций при взаимодействии каждого отдела с регистрирующей системой своего сектора рассчитывается по формуле (5);
| (5) |
- количество транзакций при взаимодействии отделов технического и коммерческого сектора внутри филиала равно нулю;
- количество транзакций при взаимодействии отделов филиала и дирекции равно нулю;
- количество транзакций при взаимодействии служб каждого филиала и дирекции с хранилищем данных рассчитывается по формуле (6);
| (6) |
- общее количество транзакций рассчитывается по формуле (7):
 | (7) |
Преимущества применения единого хранилища данных при различном количестве структурных единиц в компании продемонстрированы на рис. 6.

Рис. 6. Демонстрация преимущества применения единого хранилища данных при различном количестве структурных единиц в компании
В диссертационной работе рассматривается два основных подхода к построению хранилища данных:
- корпоративная информационная фабрика – CIF (Corporate Information Factory), основоположником которой является Билл Инмон;
- хранилище данных с архитектурой шины (Data Warehouse Bus, сокр. BUS), основоположником которой является Ральф Кимболл.
Рассматриваются особенности каждого подхода. Делается вывод о предпочтительности использования архитектуры BUS в качестве основы для решения поставленных задач.
Во второй главе дано обоснование применения многомерной модели хранения информации в хранилищах данных, проведён анализ основных архитектур реализации многомерных моделей. Дана классификация типов изменений в элементах и структуре измерений многомерной модели данных, проводится анализ существующих подходов к отслеживанию этих изменений, делается вывод о невозможности применения данных подходов в условиях динамичных изменений в элементах и структуре измерений. Выдвигается предположение о возможности отслеживания изменений в измерениях любой сложности путем применения темпорально-многомерной модели данных. Дано формальное описание элементов, составляющих темпоральное хранилище данных, а также функций трансформации, как механизма преобразования данных одной структурной версии к структуре другой структурной версии. Разработана модель темпорального хранилища данных, использующая матрицы трансформации в качестве механизма трансформации данных между структурными версиями. Произведен анализ возможных запросов в темпоральном хранилище данных, дано формальное описание операций, необходимых для выполнения этих запросов.
Многомерная модель оптимальна для проведения анализа информации; базовым элементом многомерной модели являются измерения. Количество измерений определяет количество возможных перспектив анализа предметной области. В диссертационной работе приводится описание базовых понятий многомерной модели: кубов данных, измерений, фактов, мер, запросов. Описываются операции агрегации по простым и иерархическим измерениям.
Даётся описание основных архитектур реализации многомерных моделей: MOLAP (Multidimensional Online Analytical Processing – многомерный оперативный анализ ) и ROLAP – (Relational Online Analytical Processing – реляционный многомерный анализ). Проводится сравнение основных характеристик двух подходов. Делается вывод о предпочтительном использовании подхода ROLAP, ввиду наличия большей гибкости в модификации измерений и размерности кубов данных.
При функционировании компании в многомерной модели данных в течение времени происходят изменения. В диссертационной работе приводится классификация возможных изменений, а также проводится анализ существующих подходов к отслеживанию этих изменений, который позволяет сделать вывод о неприменимости данных подходов в условиях динамичных изменений в элементах и структуре измерений.
Отслеживание изменений в измерениях любой сложности возможно при применении темпорально-многомерной модели данных. Для определения темпорально-многомерной модели данных необходимы следующие расширения многомерной модели:
- временные штампы, т.е. маркировка многомерных данных во времени с тем, чтобы они представляли достоверное время;
- структурные версии, т.е. возможность работы с различными версиями структур (структурными версиями) при наличии временных штампов;
- Функции трансформации, т.е. механизм поддержания трансформации данных из одной структурной версии в другую.
При составлении запросов к хранилищу данных выбирается начальная структурная версия. Данные же, возвращенные запросом могут порождать обращение к нескольким (различным) структурным версиям куба. Поэтому необходимо задание функций отображения между структурными версиями.
Функцию отображения можно определить как:
 , , | (8) |
где:
![]() и
и ![]() – структурные версии,
– структурные версии,
![]() и
и ![]() – элементы измерения, принадлежащие соответственно структурной версии
– элементы измерения, принадлежащие соответственно структурной версии ![]() и
и ![]() ,
,
![]() непустой, конечный набор идентификаторов фактов,
непустой, конечный набор идентификаторов фактов,
![]() – коэффициент трансформации для проецирования данных из одной структурной версии в другую.
– коэффициент трансформации для проецирования данных из одной структурной версии в другую.
В диссертационной работе для реализации механизма отображения предлагается представлять многомерный куб виде матрицы с измерениями, представляющими комбинации измерений исходного куба, а связи между элементами измерений различных структурных версий посредством матриц трансформации.
Пусть ![]() – структурная версия с N измерениями. Каждое измерение
– структурная версия с N измерениями. Каждое измерение ![]() состоит из набора
состоит из набора ![]() , который представляет все элементы нулевого уровня этого измерения. Эту структурную версию можно представить как
, который представляет все элементы нулевого уровня этого измерения. Эту структурную версию можно представить как ![]() гиперкуб.
гиперкуб.
Пусть ![]() и
и ![]() две структурные версии, для которых определим матрицу трансформации
две структурные версии, для которых определим матрицу трансформации ![]() для каждого измерения
для каждого измерения ![]() и каждого факта F. Тогда
и каждого факта F. Тогда ![]() число, представляющее коэффициент трансформации –
число, представляющее коэффициент трансформации – ![]() для отображения факта F элемента измерения
для отображения факта F элемента измерения ![]() структурной версии
структурной версии ![]() в факт элемента измерения
в факт элемента измерения ![]() структурной версии
структурной версии ![]() .
.
Итак, матрицу трансформации можно определить следующим образом:
| (9) |
где:
![]() – структурная версия, в которой находятся трансформируемые данные;
– структурная версия, в которой находятся трансформируемые данные;
![]() – структурная версия в структуру, которой необходимо преобразовать;
– структурная версия в структуру, которой необходимо преобразовать;
![]() – набор элементов измерения исходной структурной версии;
– набор элементов измерения исходной структурной версии;
![]() – набор элементов целевой структурной версии;
– набор элементов целевой структурной версии;
Элемент матрицы трансформации определяет коэффициент трансформации факта элемента исходного измерения в факт элемента целевого измерения. Коэффициент трансформации следующим образом:
| (10) |
где:
![]() – структурная версия, в которой находятся трансформируемые данные;
– структурная версия, в которой находятся трансформируемые данные;
![]() – структурная версия в структуру, которую необходимо преобразовать;
– структурная версия в структуру, которую необходимо преобразовать;
![]() – элемент измерения
– элемент измерения ![]() ;
;
![]() – элемент измерения
– элемент измерения ![]() ;
;
![]() – коэффициент трансформации элементов исходного измерения в целевое.
– коэффициент трансформации элементов исходного измерения в целевое.
В качестве примера матрицы трансформации можно привести матрицу (11):
 | (11) |
Элементы матрицы трансформации состоят из коэффициентов трансформации исходного измерения в целевое – ![]() . Правильное определение этих коэффициентов определяет степень достоверности данных, получаемых при трансформации куба данных.
. Правильное определение этих коэффициентов определяет степень достоверности данных, получаемых при трансформации куба данных.
В наиболее простом случае мы принимаем ![]() статическим значением. В диссертационной работе высказано предположение о возможности применения в качестве коэффициентов трансформации функциональных значений (12).
статическим значением. В диссертационной работе высказано предположение о возможности применения в качестве коэффициентов трансформации функциональных значений (12).
 | (12) |
При анализе данных двух структурных версий необходимо отобразить куб структурной версии ![]() в структуру
в структуру ![]() .
.
В диссертационной работе определена операция трансформации над кубом данных.
Пусть ![]() – матрица трансформации измерения
– матрица трансформации измерения ![]() при отображении куба данных структурной версии
при отображении куба данных структурной версии ![]() в структуру структурной версии
в структуру структурной версии ![]() .
.
![]() – куб в структурной версии
– куб в структурной версии ![]() ;
;
![]() – куб в структурной версии
– куб в структурной версии ![]() ;
;
![]() – куб
– куб ![]() в структурной версии
в структурной версии ![]() ;
;
![]() – куб
– куб ![]() в структурной версии
в структурной версии ![]() ;
;
![]() – двумерная матрица, представляющая собой развертку куба данных
– двумерная матрица, представляющая собой развертку куба данных ![]() , такую, что по горизонтали располагаются элементы
, такую, что по горизонтали располагаются элементы ![]() , а по вертикали все возможные комбинации элементов остальных измерений;
, а по вертикали все возможные комбинации элементов остальных измерений;
![]() – двумерная матрица, представляющая собой развертку куба данных
– двумерная матрица, представляющая собой развертку куба данных ![]() такую, что по горизонтали располагаются элементы
такую, что по горизонтали располагаются элементы ![]() , а по вертикали все возможные комбинации элементов остальных измерений; тогда можно определить следующую формулу:
, а по вертикали все возможные комбинации элементов остальных измерений; тогда можно определить следующую формулу:
 | (13) |
Операция перемножения в данной формуле означает перемножение матриц (так при перемножении ![]() на
на ![]() получаем
получаем ![]() ;
; ![]() – количество комбинаций членов измерений без
– количество комбинаций членов измерений без ![]() ,
, ![]() – количество элементов
– количество элементов ![]() ,
, ![]() – количество элементов измерения
– количество элементов измерения ![]() .
.
Возможны следующие варианты соотношения количества элементов измерений исходной и целевой структурных версий:
![]() – перегруппировка мощности элементов измерения;
– перегруппировка мощности элементов измерения;
![]() – объединение элементов измерения;
– объединение элементов измерения;
![]() – дробление элементов измерения;
– дробление элементов измерения;
![]() – порождение нового измерения с k элементами;
– порождение нового измерения с k элементами;
![]() – вырождение одного измерения (в частном случае – агрегация).
– вырождение одного измерения (в частном случае – агрегация).
Формально из этого следует, что в любом кубе может существовать бесконечное множество измерений, которые могут свободно вырождаться и порождаться при правильно подобранных коэффициентах трансформации ![]() , без потери качества данных.
, без потери качества данных.
Для преобразования всего куба необходимо произвести поочередное перемножение разверток куба по измерениям на соответствующие матрицы преобразования этих измерений.
Для преобразования всего куба данных ![]() в
в ![]() в диссертационной работе выведена следующая формула (14):
в диссертационной работе выведена следующая формула (14):
 | (14) |
где:
![]() – количество различных измерений двух структурных версий, то
– количество различных измерений двух структурных версий, то
есть если ![]() и
и ![]() количество измерений в структурных версиях
количество измерений в структурных версиях ![]() и
и ![]() , то
, то ![]() ;
;
Произведен анализ возможных запросов в темпоральном хранилище данных, дано формальное описание операций, необходимых для выполнения этих запросов. Данное формальное описание дает основу для практической реализации темпорального хранилища данных.
На основе формального описания модели темпорального хранилища данных построена концептуальная модель темпорально хранилища данных в нотации UML (Universal Modeling Language – универсальный язык моделирования), представленная на рис. 7. Данная модель позволяет программно реализовать темпоральное хранилище данных.

Рис. 7. Концептуальная модель темпорального хранилища данных в нотации UML
В третьей главе рассматривается модель организации данных темпорального хранилища данных на основе реляционной СУБД. Описываются разработанные алгоритмы: алгоритм преобразования многомерной модели данных в темпорально-многомерную, алгоритм трансформации куба данных и его составная часть – алгоритм перемножения разреженных матриц, алгоритм ETL(Extract Transform Load) процесса с использованием матриц трансформации.
В диссертационной работе предложена ER-диаграмма темпорального хранилища данных в нотации UML, представленная на рис. 8. Данная диаграмма позволяет реализовать темпоральную модель данных средствами реляционной СУБД.

Рис. 8. ER-диаграмма данных темпорального хранилища данных в нотации UML
В связи с важностью процесса внедрения нового темпорального хранилища без потери данных, накопленных в старых многомерных и реляционных хранилищах данных, рассматривается вопрос перехода на темпорально-многомерное хранилище данных. Приводится разработанный алгоритм перехода с существующих систем хранения информации на темпоральное хранилище данных с формированием матриц трансформации, которые обеспечивают возможность вовлечения в анализ старых данных одновременно с новыми данными. Диаграмма деятельности в нотации UML, описывающая разработанный алгоритм, представлена на рис. 9.

Рис. 9. Диаграмма деятельности в нотации UML, описывающая алгоритм перехода с существующих систем хранения многомерной информации на темпоральное хранилище данных
Обобщенный алгоритм трансформации куба данных ![]() из структурной версии
из структурной версии ![]() в структурную версию
в структурную версию ![]() , представленный в виде диаграммы деятельности в нотации UML, приведен на рис. 10, данный алгоритм представляет собой реализацию формулы (14).
, представленный в виде диаграммы деятельности в нотации UML, приведен на рис. 10, данный алгоритм представляет собой реализацию формулы (14).
Приведенное во второй главе формальное описание трансформации хранилища данных предполагает перемножение матриц трансформации, (сложность алгоритма перемножения матриц – ![]() ) на двумерное представление многомерного куба данных, что, в условиях наличия большого количества измерений, является достаточно ёмкой операцией как по использованию оперативной памяти системы, так и процессорного времени. Важной особенностью кубов данных является наличие большого количества нулевых элементов – разреженность куба данных, что ведёт к нерациональному расходу памяти при представлении матриц в виде двумерных массивов.
) на двумерное представление многомерного куба данных, что, в условиях наличия большого количества измерений, является достаточно ёмкой операцией как по использованию оперативной памяти системы, так и процессорного времени. Важной особенностью кубов данных является наличие большого количества нулевых элементов – разреженность куба данных, что ведёт к нерациональному расходу памяти при представлении матриц в виде двумерных массивов.

Рис. 10. Диаграмма деятельности в нотации UML, описывающая алгоритм трансформации куба данных
Матрицы трансформации также отличаются наличием большой доли нулевых элементов. В диссертационной работе с учётом описанных особенностей, предлагается оптимизированное для решаемой задачи представление матриц в виде массива связных списков и алгоритм трансформации куба данных с представлением куба данных и матриц трансформации в виде массива связных списков. Диаграмма деятельности в нотации UML, описывающая разработанный алгоритм, представлена на рис. 11.

Рис. 11. Диаграмма деятельности в нотации UML, описывающая алгоритм перемножения разреженных матриц
Важное место в функционировании хранилища данных занимает процесс импорта данных из оперативных регистрирующих систем – процесс ETL (Extract Transform Load – извлечение трансформация загрузка). В диссертационной работе предложен алгоритм трансформации данных в ETL процессе с использованием матриц трансформации. Алгоритм основан на предположении о возможности представить извлечённые данные любой регистрирующей системы или нескольких регистрирующих систем в виде многомерного куба данных или нескольких кубов данных. Структура этого куба данных будет отличаться от структуры куба данных темпорального хранилища данных. Осуществить трансформацию исходных данных в структуру целевого куба данных возможно, определив однократно матрицы трансформации структуры исходного куба данных в структуру куба темпорального хранилища данных. Впоследствии данная трансформация осуществляется каждый раз при импорте данных. Процедура аналогична трансформации структурных версий темпорального хранилища данных. Диаграмма деятельности в нотации UML, представляющая алгоритм ETL-процесса с использованием матриц трансформации, представлен на рис. 12.

Рис. 12. Диаграмма деятельности в нотации UML, описывающая алгоритм ETL процесса с использованием матриц трансформации
В четвёртой главе рассмотрены вопросы разработки программного обеспечения темпорального хранилища данных, обосновывается выбор предложенных средств программной реализации, даётся оценка корректности предложенной модели и алгоритмических решений путем проведения трансформации куба данных на реальных и тестовых данных. Рассматриваются вопросы использования результатов диссертационной работы в различных отраслях производства.
Рассмотрены вопросы физической организации модулей, составляющих темпоральное хранилище данных. Приведена диаграмма развертывания системы в нотации UML, представленная на рис. 13, представляющая архитектуру системы, описывается назначение модулей и характер их взаимосвязи.
Описываются предложенные средства программной реализации темпорально-многомерного хранилища данных. Обосновывается выбор средств реализации. Следует отметить, что все использованное программное обеспечение и языки разработки, а также разработанные модули являются кроссплатформенными. Все использованное в разработанной системе программное обеспечения является открытым и свободно распространяемым.
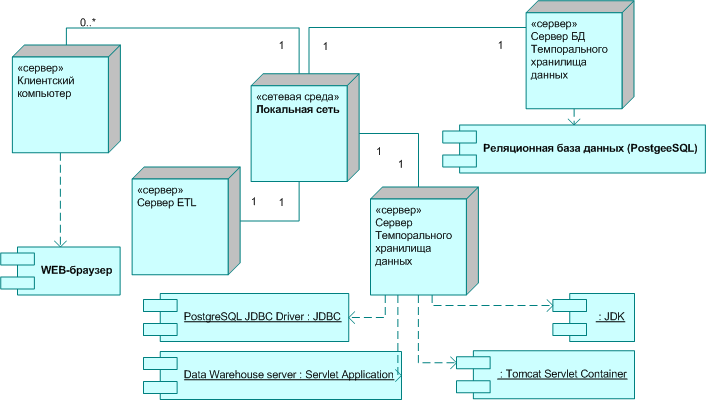
Рис. 13. Диаграмма развертывания системы в нотации UML
В главе приводится пример трансформации куба данных на тестовых данных, подтверждая верность теоретических выводов и разработанного алгоритма трансформации куба данных одной структурной версии в структуру другой структурной версии.
Система внедрена и функционирует на протяжении трех лет в региональном филиале ОАО «ЮТК» «Связьинформ» Астраханской области.
Описан опыт практического применения механизма трансформации куба данных, который имел место при структурных изменениях в региональном филиале ОАО «ЮТК» «Связьинформ» Астраханской области. При сравнении данных, полученных при трансформации куба данных, с фактическими данными, которые продолжали собираться, погрешность данных, полученных при трансформации куба данных, составила от 0,24 процента до 3,77 процента, в среднем – 2,1 процента. Погрешность может варьироваться при получении данных по различным показателям. Важную роль в уменьшении погрешности имеет правильный подбор коэффициентов трансформации ![]() .
.
Проведен анализ возможности применения результатов диссертационной работы в других отраслях. Результаты исследования определяют довольно широкий круг предприятий, которые нуждаются в эффективных средствах бизнес аналитики, а, следовательно, и в хранилищах данных. В большинстве компаний, серьезно занимающихся вопросами комплексной бизнес-аналитики, существуют описанные выше проблемы отслеживания изменений в измерениях пространственных структур данных, следовательно, результаты диссертационного исследования могут найти применение в широком диапазоне сфер деятельности.
Основные выводы и результаты
Научные результаты и предложенные алгоритмы позволяют:
- на основе выведенного формального описания трансформации куба данных в темпоральном хранилище данных, осуществить трансформацию данных куба данных одной структурной версии в структуру другой структурной версии, что приводит к увеличению глубины анализа данных в системах поддержки принятия решений;
- реализовать темпоральную модель данных средствами реляционной СУБД, а также программно реализовать темпоральное хранилище данных, что возможно благодаря разработанной объектно-реляционной модели темпорально-многомерного хранилища данных и структуре данных темпорально-многомерного хранилища данных;
- на основе разработанных алгоритмов функционирования темпорального хранилища данных, осуществлять переход с существующих систем хранения информации на темпоральное хранилище данных, осуществлять трансформацию куба данных с использованием матриц трансформации, реализовывать трансформацию данных в ETL процессе с использованием матриц трансформации.
Список работ, опубликованных по теме диссертации
- Спандерашвили, Д.В. Особенности построения системы сбора статистики телекоммуникационной компании./ Д.В. Спандерашвили. // Информатика: проблемы, методология, технологии. Материалы пятой региональной научно-методической конференции. – Воронеж: Воронежский государственный университет, 2005. – Ч 2. – С.136-141. – ISBN 5-9273-0681-0.
- Спандерашвили, Д.В. Темпорально многомерная модель для контроля динамики данных региональной компании./ Д.В. Спандерашвили.// Проблемы стратегии регионального развития: Материалы Всероссийской научной конференции. – Тамбов: Першина, 2006. – С.80-84. – ISBN 5-902517-94-X.
- Спандерашвили, Д.В. Механизмы отслеживания изменений в многомерных структурах данных./ Д.В. Спандерашвили.// Инфокоммуникационные технологии в науке, производстве и образовании: Вторая международная научно-техническая конференция. – Ставрополь: СКГТУ, 2006. – Ч 1. – С.160-162.
- Спандерашвили, Д.В. Объектная модель Темпорально многомерных данных и ее реализация средствами реляционной СУБД./ Д.В. Спандерашвили. // «Информационные технологии в науке, образовании и производстве» (ИТНОП). Материалы международной научно-технической конференции. – Орел: ОрелГТУ, 2006. – Т 4. – С.210-215.
- Спандерашвили, Д.В. Вопросы реализации темпорально-многомерной модели данных на примере хранилища данных телекоммуникационной компании./ Д.В. Спандерашвили. // Фундаментальные исследования в технических университетах. Материалы X Всероссийской конференции по проблемам науки и высшей школы. – СПб.: Изд-во политехн. ун-та, 2006. – С.205-206.
- Спандерашвили, Д.В. Принципы организации взаимодействия регистрирующих систем с хранилищем данных (на примере телекоммуникационной компании)./ Д.В. Спандерашвили, Г.Г. Мирошников.// Инженерное образование. Наука в образовании: электронное научное издание. – №ГОС. РЕГИСТРАЦИИ 0420600025. – Москва: МГТУ им. Н. Э. Баумана, 2006. – №8. – регистрационный номер статьи 0420600025\0025.
- Спандерашвили, Д.В. Алгоритмические вопросы реализации темпорального хранилища данных./ Д.В. Спандерашвили.// Инженерное образование. Наука в образовании: электронное научное издание. – №ГОС. РЕГИСТРАЦИИ 0420600025. – Москва: МГТУ им. Н. Э. Баумана, 2006. – №8. – регистрационный номер статьи 0420600025\0026.
- Спандерашвили, Д.В. Формальное описание модели и алгоритмы трансформации темпорального хранилища данных./ Д.В. Спандерашвили.// Южно-Российский вестник геологии, географии и глобальной энергии. – Астрахань: АГУ, 2006. – №7(20). – С.136-142. – ISSN 1818-5169.
- Спандерашвили, Д.В. Автоматизированная система сбора и обработки данных телекоммуникационной компании./ Д.В.Спандерашвили, И.Ю. Петрова.// Свидетельство об официальной регистрации программ для ЭВМ №2006611990 в Реестре программ для ЭВМ Федеральной службы по интеллектуальной собственности, патентам и товарным знакам. – 2006.