

ФОРМАЛЬНЫЕ ЯЗЫКИ И МЕТОДЫ СПЕЦИФИКАЦИИ,
АНАЛИЗА И СИНТЕЗА ИНФОРМАЦИОННЫХ СИСТЕМ
Годовой отчет по гранту РАН 2/12
Новосибирск 2010
ОГЛАВЛЕНИЕ
ВВЕДЕНИЕ................................................................................................................................. 3
ОПИСАНИЕ ВЫПОЛНЕННОЙ РАБОТЫ.............................................................................. 6
Тема 1. Логические методы....................................................................................................... 6
Тема 2. Информационные системы на основе онтологий...................................................... 9
Тема 3. Методы автоматического извлечения фактов из текстов на естественном языке..23
Тема 4. Формально-языковые проблемы информационных систем.................................... 30
Тема 5. Принципы и инструментальные средства электронной фактографии................... 34
Тема 6. Теоретические исследования и программные эксперименты по математической лингвистике................................................................................................................................ 39
ВВЕДЕНИЕ
В связи с бурным ростом объемов информации все более актуальной становится задача эффективного информационного обеспечения научных, производственных процессов и процессов принятия решений. В настоящее время наблюдается бум создания информационных систем (ИС). Однако, как правило, процесс создания ИС носит неунифицированный характер (привязан к среде разработки, программному обеспечению, компетенции и предпочтениям конкретных разработчиков и т. д.) и в слабой степени использует формальные методы. Это затрудняет процесс спецификации предметной области, для которой разрабатывается ИС, процесс анализа ИС (в частности, проверки качества разрабатываемой ИС), ее документирование и сопровождение.
Поэтому задача формализации и унификации процесса разработки ИС имеет актуальное значение. Использование языков формальной спецификации ИС приводит к стандартизации и унификации документации по ИС, что облегчает ее сопровождение и модификацию. Формальные методы анализа ИС позволяют получать ИС с более качественными характеристиками (степень надежности, корректность, степень эффективности, уровень распараллеливания и т. д.), обеспечивая также количественные и качественные меры измерения этих характеристик, что упрощает сравнительный анализ ИС и выбор ИС с заданными характеристиками. Формальные методы синтеза ИС по ее спецификации позволяют получать различные сборки ИС в соответствии с требованиями заказчика и обеспечивают оперативность модификации ИС на всех этапах ее жизненного цикла, особенно на этапе проектирования ИС, когда цена ошибки особенно велика.
Целью проекта является разработка формальных языков и методов спецификации, анализа и синтеза ИС.
Проект разбит на 6 основных тем, включающих следующие направления исследований:
Тема 1. Логические методы
- Исследование выразительной силы и алгоритмических свойств комбинаций отдельных логических формализмов (логики ролей и понятий, фреймовой, эпистемической и темпоральной логик) с алгебраическим аппаратом анализа формальных понятий.
- Исследование выразительной силы и алгоритмических свойств комбинации логики ролей и понятий (расширенной средствами анализа формальных понятий) с другими логическими формализмами (с фреймовой, эпистемической и темпоральной логиками).
- Апробация ценности полученных теоретических результатов по комбинации алгебро-логических формализмов для спецификации и анализа мультиагентных систем и проблемно-ориентированных онтологий.
Тема 2. Информационные системы на основе онтологий
- Развитие формальных и программных методов и средств построения онтологий.
- Разработка методов и средств автоматического построения компонентов ИС (пользовательского интерфейса, базы данных) на основе онтологий.
- Разработка методов анализа и визуализации онтологий и информационного наполнения ИС.
- Разработка методов эволюции и реинжиниринга онтологий, используемых в ИС.
Тема 3. Методы автоматического извлечения фактов из текстов на естественном языке
- Разработка методов представления коммуникативно-прагматического контекста ЕЯ-сервиса в информационных системах.
- Разработка методов автоматического извлечения прагматических данных из текстов делового или научного жанра.
- Разработка методологии формирования лингвистической и коммуникативно-прагматической базы знаний.
- Разработка методов и средств поддержки ЕЯ-сервиса на основе лингвистических и коммуникативно-прагматических знаний.
Тема 4. Формально-языковые проблемы информационных систем
- Разработка формализмов для спецификации ИС, которые комбинируют логические, онтологические и операционные подходы к спецификации ИС и унифицируют средства спецификации ИС, базирующиеся на этих подходах.
- Разработка языков спецификации ИС, базирующихся на предлагаемых формализмах.
- Разработка методологии применения предлагаемых языков к спецификации ИС.
- Разработка формальной семантики предлагаемых языков.
- Разработка методов анализа спецификаций ИС, описанных на предлагаемых языках.
- Разработка методов синтеза ИС по их спецификациям, описанных на предлагаемых языках.
- Апробация предлагаемых формализмов, языков и методов на примерах ИС.
Тема 5. Принципы и инструментальные средства электронной фактографии
- Разработка и обоснование принципов электронной фактографии для фиксации фактов и данных о сопряженных им сущностях.
- Разработка новых методик построения распределенных баз данных и документов.
- Разработка новых формальных спецификаций для описания предметных областей и формирования базы знаний.
- Развитие созданной в ИСИ СО РАН онтологии неспецифических сущностей, позволяющей структурировать разносортную информацию.
- Разработка инструментальных программных средств для сбора и редактирования информации: обработки, представления и анализа данных в едином распределенном информационном поле.
- Исследование взаимодействия средств локального хранения данных и средств, предоставляющих возможности формирования общего поля данных и документов.
- Апробация предлагаемых методов на примерах фактографических информационных систем.
Тема 6. Теоретические исследования и программные эксперименты по математической лингвистике
- Разработка машинно-ориентированных логических методов отображения семантики текста на естественном языке. Развитие имеющейся в настоящий момент исследовательской системы для анализа текстов на естественном языке.
- Проведение формального анализа конструкций, применяемых в системах синтаксического анализа с целью их оптимизации. Создание специализированных модификаций систем синтаксического анализа.
- Исследования по распараллеливанию лингвистических алгоритмов. Проведение экспериментов с лингвистическими алгоритмами на параллельных вычислительных системах.
- Разработка поисковых систем, использующих лингвистические алгоритмы.
- Исследование по распознаванию текстов очень низкого качества.
- Разработка ряда словарей с быстрым доступом и создание на их основе отчуждаемых программных компонент.
ОПИСАНИЕ ВЫПОЛНЕННОЙ РАБОТЫ
Тема 1. Логические методы
Полученные за отчетный период важнейшие результаты
Проведено исследование мультиагентных протоколов, в результате выполнения которых мультиагентная система кооперативно решает геометричесую задачу о назначениях (вариант классической комбинаторной задачи на графах). Для этой задачи было предложено и обосновано несколько протоколов. В 2009 г. были разработаны алгоритмы для «прыгающих» роботов (т. е. способных к мгновенным перемещениям) и алгоритмы с избранием лидера (который решает задачу за всех), причём, коректность первого из этих алгоритмов была доказана для систем, в которых общение между роботами удовлетворяет гипотезе спарведливости. В 2010 г. были разработаны алгоритмы для произвольных роботов (не «прыгающих»), которые приводят к решению без избрания лидера и гипотезы справедливости при общении агентов.
Исследовалась проблема представления знаний в мультиагентных системах, в которых состояния агентов характеризуются полулинейными множествами чисел. Для представления и верификации знаний в таких системах предложено символьное представление в виде деревьев, узлы которых помечены полулинейными множествами. Экспериментально проверена эффективность данного символьного формата при решении модельной задачи, в которой теоретически могло возникнуть до 10^36000 состояний системы.
Разработана и реализована экспериментальная версия портала знаний по классификации и парадигмам компьютерных языков. В основу концепции создания этого портала положена идея разработки онтологии предметной области компьютерных языков в виде открытой эволюционирующей темпоральной on-line онтологии компьютерных языков со средствами навигации и поддержкой связей между языками и парадигмами посредством инструментов логики описаний ролей и понятий. Произведено первоначальное наполнение портала знаниями о компьютерных языках из открытых Интернет-источников при помощи специально разработанных инструментальные средства сканирования таких источников. Для этого были проанализированы имеющиеся Интернет-системы классификации компьютерных языков Progopedia и FreeBase; часть данных о более чем 1200 языков была извлечена из Прогопедии и Freebase, объединена и преобразована в формат, пригодный для использования в прототипе портала для онтологической классификации. На рисунке представлен интерфейс редактора онтологии компьютерных языков после первоначального наполнения портала.
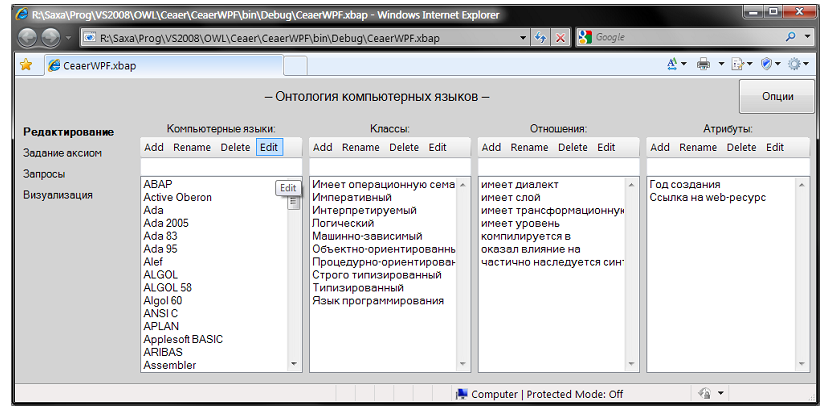
Рис. 1. Портал знаний по классификации и парадигмам компьютерных языков
Публикации (2009-2010)
- Ануреев И.С., Батура Т.В., Боровикова О.И., Загорулько Ю.А., Кононенко И.С., Марчук А.Г., Марчук П.А., Мурзин Ф.А., Сидорова Е.А., Шилов Н.В. Модели и методы построения информационных систем, основанных на формальных, логических и лингвистических подходах / Отв. ред. А.Г. Марчук ; Рос. акад. наук, Сиб. отд-ние, Ин-т систем информатики им. А.П. Ершова. – Новосибирск: Изд-во СО РАН, 2009. ISBN 978–5–7692–1113–3. – 330 с.
- Shilov N.V., Garanina N.O. Combined Logics of Knowledge, Time and Actions for Reasoning about Multi-Agent Systems. Принято к публикации в трудах конференции Knowledge Processing in Practice в серии Lecture Notes in Artificial Intellegence, Springer, 11 стр.
- Garanina N.O., Shilov N.V. and Konyaev L.E. Can Robots Solvethe Assignment Problem? Proceedings of Workshop on Concurrency, Specification, and Programming CS&P 2009, v.1, p.154-163.
- Гаранина Н.О. Как роботам решить задачу о назначениях? Proceedings of the Knowledge and Ontology *ELSEWHERE* Workshop. University High School of Economics, Moscow, Russia, 2009, p.72-86.
- Шилов Н.В., Акинин А.А. О классификации компьютерных языков на основе формальной онтологии. Материалы Международная научной конференция «Философия, математика, лингвистика: аспекты взаимодействия», 20-22 ноября 2009, Санкт-Петербургское отделение Математического института им. В.А. Стеклова РАН, 2009, стр. 176-181.
- Шилов Н.В. Заметки о преподавании парадигм программирования. Принято к представлению на IV Международной научно-практической конференции «Современные информационные технологии и ИТ-образование», Москва, факультет вычислительной математики и кибернетики МГУ им. Ломоносова, 14-16 декабря 2009 г., 8 стр.
- Андреева Т.А., Ануреев И.С., Бодин Е.В., Городняя Л.В., Марчук А.Г., Мурзин Ф.А., Шилов Н.В. Образовательное значение компьютерных языков // Прикладная информатика, 6(24) 2009. – С. 18 – 28.
- Shilov N., Natalia Garanina N. and Eugene Bodin E. Multiagent approach to a Dijkstra problem. Принята для публикации в трудах Workshop on Concurrency, Specification, and Programming CS&P 2010, 12 с.
- Гаранина Н.О. Проверка моделей распределенных систем с помощью аффинного представления данных. Workshop Program Semantics, Specification and Verification: Theory and Applications. Казань: Отечество. 2010. - С. 56-62.
- Shilov N., Idrisov R., Akinin A., Zubkov A. Development of the Computer Language>
Участие в международных и всероссийских научных мероприятиях (2009-2010)
- International Workshop “Concurency, Specification and Programming” (CSP2009), Krakov, Poland, 2009.
- Всероссийская конференция с международным участием «Знания – Онтология – Теория» (ЗОНТ–09), Новосибирск, 2009.
- Весенняя школа по играм и верификации, Берниторо, Италия, 31 мая – 6 июня 2009 г. Организована европейской исследовательской сетью по играм и верификации (GAMES) при поддержке European Science Foundation.
- Семинар с международным участием «Знания и Онтологии *ELSEWHERE* 2009» (ELSEWHERE-2009) в рамках 17th International Conference on Conceptual Structures (ICCS-2009), 26-31 июля 2009 года, Москва, Высшая школа экономики.
- Международная междисциплинарная конференция «Философия, математика, лингвистика: аспекты взаимодействия», 17-22 ноября 2009, Санкт-Петербургское отделение Математического института им. В.А. Стеклова РАН.
- IV Международная научно-практическая конференция «Современные информационные технологии и ИТ-образование», 14-16 декабря 2009 г. Москва, МГУ им. М. В. Ломоносова.
- International Workshop on Program Semantics, Specification and Verification, June 14-15, Kazan, Russia.
- International Workshop “Concurency, Specification and Programming” (CSP2010), Berlin, Germany, September 27 – 29, 2010.
- XIII Российская конференция с участием иностранных ученых «Распределенные информационные и вычислительные ресурсы» (DICR'2010), Новосибирск, 30 ноября - 3 декабря 2010 г.
ПЛАН ИССЛЕДОВАНИЙ НА 2011 ГОД
- Продолжить исследование проблемы представления знаний в мультиагентных системах, в которых состояния агентов характеризуются полулинейными множествами чисел.
- На основе полученного в 2010 г. мультиагентного алгоритма для геометрической задачи о назначениях разработать и обосновать мультиагентный алгоритм планирования перемещений агентов на плоскости.
- Пополнить портал знаний о компьютерных языках ссылками на внешние ресурсы информации, сведениями об авторстве редакторских правок, сервисом поиска языков по спецификациям. Программы для извлечения данных для портала из внешних (открытых) источников предполагается довести до состояния инструментальных приложений, с помощью которых участник проекта сможет легко получить данные из открытых источников в Интернете и перевести их в формат портала знаний.
Тема 2. Информационные системы на основе онтологий
В рамках этой темы в 2010 г. проводились исследования в следующих направлениях:
- Исследование методов автоматизации построения и настройки компонентов информационной системы (пользовательского интерфейса, хранилища данных) на основе онтологий.
- Продолжение работ по визуализации онтологий и информационного наполнения информационной системы (ИС).
- Разработка методов получения структурированного представления текста документа, позволяющего установить ассоциативные связи между публикациями (документами, представленными в контенте ИС) и персонами с целью их последующей визуализации и анализа.
- Исследование подходов к построению онтологий информационных систем путем трансформации уже существующих онтологий
Полученные за отчетный период важнейшие результаты
1. Исследование методов автоматизации построения и настройки компонентов информационной системы на основе онтологий проводилось в двух направлениях. Первое из них связано с построением и настройкой пользовательского интерфейса ИС, второе – с построением и настройкой хранилища данных.
1.1. В рамках исследования методов автоматизации построения и настройки пользовательского интерфейса информационной системы на основе онтологий были выявлены следующие подходы к автоматизированному построению и настройке пользовательского интерфейса:
- Без построения онтологии пользователя (дополнительных онтологий).
- С построением онтологии пользователя.
- С построением онтологии интерфейса.
1.1.1. Первый подход не предполагает построение дополнительных онтологий, в частности, онтологии пользователя. Здесь пользователю предоставляется возможность настраивать определенные компоненты пользовательского интерфейса. Например, на портале научных знаний пользователь может выбрать вид отображения структуры данных (в виде дерева, или в виде списков), язык (русский или английский), порядок отображения новостных сообщений. Кроме того, пользователь может настроить визуализацию объектов определенного класса онтологии, задав шаблоны визуализации как самих объектов, так и содержательных ссылок на них. Шаблон визуализации объектов класса определяет порядок, в котором отображаются все его атрибуты и связанные с ним отношения. Шаблон визуализации ссылок на конкретные объекты класса может включать атрибуты как этого класса, так и классов, связанных с ним отношениями, а также атрибуты этих отношений.
Во время функционирования ИС все визуальные формы и страницы, с которыми работает пользователь (списки объектов, страницы с описанием определенных классов, отношений, объектов, формы для их ввода и редактирования и т.п.) строятся на основе информации, описанной в онтологии с учетом тех настроек, которые сделал пользователь.
1.1.2. Список доступных пользователю настроек, их содержательность и функциональность, можно существенно расширить, если построить онтологию пользователя. Так, зная информацию о научных интересах пользователя, можно в первую очередь предлагать для просмотра интересные ему разделы контента ИС; зная некоторые личные данные пользователя, можно строить поисковые формы с автоматически заполненными полями. Кроме того, ИС может оповещать пользователя об изменениях, происходящих в интересующих его разделах или информировать о деятельности (просмотр или редактирование контента ИС) связанной с данным пользователем группы пользователей. На Рис.2. представлен фрагмент онтологии пользователя.


Рис. 2. Фрагмент онтологии пользователя.
1.3. С построением онтологии интерфейса. Интересный подход к построению пользовательских интерфейсов предложен в [1]. Основная идея подхода – сформировать декларативную модель пользовательского интерфейса на основе моделей онтологий и затем по высокоуровневому декларативному описанию автоматически генерировать исполнимый код интерфейса.
Модель любого пользовательского интерфейса прикладной программы можно рассматривать как совокупность следующих моделей: системы понятий предметной области, выразительных средств интерфейса, прикладной программы, сценария диалога, а также соответствий между моделями системы понятий предметной области и выразительных средств, между моделями системы понятий и прикладной программы.
Описанные выше идеи положены в основу разрабатываемой методологии построения интерфейсов ИС. Согласно этой методологии, ИС, наряду с онтологией пользователя, содержит онтологию пользовательского интерфейса, в которую включены понятия, отображающие возможные компоненты интерфейса. Каждая компонента имеет свои визуальное представление и функциональность, предназначена для определенных целей и играет в пользовательском интерфейсе свою особую роль. С компонентой пользовательского интерфейса связан реализующий ее программный модуль. Перед началом работы пользователь, используя онтологию интерфейса, определяет необходимые ему компоненты, либо (при отсутствии должной квалификации) просто указывает, для каких целей он хочет использовать ИС и какой функциональности он от нее ожидает (в этом случае необходимые компоненты будут определены автоматически). После этого система автоматически строит из выбранных компонентов интерфейс, определяя его архитектуру и загружая необходимые программные модули.
1.2. В рамках исследования методов автоматизации построения и настройки на основе онтологий хранилища данных и информационной системы в целом был рассмотрен такой класс информационных систем, как системы поддержки принятия решений.
Система поддержки принятия решений – это интерактивная информационно-аналитическая система, которая помогает лицу, принимающему решения (ЛПР), использовать данные и модели для решения его профессиональных слабо формализуемых задач.
В виду слабой формализованности решаемых в СППР задач очень важно иметь детальное непротиворечивое описание предметной и проблемной областей, в рамках которых ЛПР решает свои задачи. Онтология является хорошим инструментом для создания такого описания.
В большинстве типов СППР используются большие массивы разнородных данных и знаний. Благодаря тому, что онтология позволяет явно описывать семантику данных и знаний, она обеспечивает базис для их интеграции и совместного использования при решении задач.
Была предложена архитектура СППР, использующей в своей работе внешнее хранилище данных (ВХД) и набор решателей, реализующих различные методы принятия решений. Включением в СППР онтологии в качестве полноправного компонента обеспечивается настройка системы на предметную область и типы решаемых задач. В связи с этим назначением онтология состоит из двух частей – онтологии предметной области (ПО) и онтологии задач.
Онтология ПО служит для настройки системы на предметную область. С одной стороны, она выступает в качестве высокоуровневого интерфейса к внешнему хранилищу данных, обеспечивая доступ к данным ВХД в виде объектов предметной области, т.е. реализует объектную модель взаимодействия с ВХД. С другой стороны, на основе онтологии ПО разработан формат представления данных в виде тех же объектов предметной области (экземпляров понятий онтологии) и отношений между ними, что позволяет упростить и унифицировать обмен информацией между разнородными компонентами и модулями (решателями) СППР.
Со временем предметная область СППР может пополниться новыми сущностями и в связи с этим может возникнуть необходимость в извлечении из ВХД объектов, соответствующих этим сущностям. Такие изменения должны быть отражены в онтологии предметной области. Для этого в онтологию ПО должны быть введены соответствующие классы объектов, а также новые типы отношений, связывающих новые классы объектов с уже имеющимися в онтологии.
Онтология задач обеспечивает настройку системы на типы решаемых задач. Она включает описания решаемых системой задач и модулей поддержки принятия решений, реализующих их решения. В онтологии также вводятся отношения между самими задачами и между задачами и модулями принятия решений.
В онтологии с задачей связываются ее параметры, описанные в терминах онтологии предметной области, а все модули поддержки принятия решений снабжены следующими атрибутами: «Имя модуля», «Входные данные», «Выходные данные», «Решатель». Реализации модулей принятия решений хранятся в специальном репозитарии.
На задачах определены отношения «Подзадача» и «Порождает». Первое отношение связывает некоторую задачу с другими задачами (ее подзадачами), решение которых требуется для решения данной задачи. Отношение «Порождает» определяет потенциальную возможность порождения одной задачи другой.
В онтологии задач вводится также отношение «Реализует», связывающее модуль принятий решений с задачей, решение которой он обеспечивает.
Во время функционирования СППР, когда возникает потребность в решении какой-либо задачи, планировщик при построении плана ее решения обращается к онтологии, где представлены связи между задачами и модулями принятия решения. При этом он выбирает из репозитария необходимые модули принятия решений и последовательно передает их на исполнение соответствующим решателям. Результаты решения задачи сообщаются пользователю и выкладываются во внешнее хранилище данных в формате, определенном онтологией предметной области.
При появлении новых задач, таковые должны быть описаны и включены в онтологию задач. Для каждой новой задачи должен быть разработан отдельный модуль поддержки принятия решений, а его писание включено в онтологию задач, где оно должно быть связано с новой задачей отношение «Реализует». После этого СППР будет настроена на решение новых задач.
2. В рамках исследования методов анализа и визуализации онтологий и информационного наполнения ИС велась разработка и реализация методов визуализации и навигации по иерархическим структурам большого объема, представленных в виде графов. Реализована подсистема интерактивной визуализации онтологии и информационного наполнения портала знаний, включающая:
- Методы визуализации, учитывающие типы конкретных отношений, а также методы визуализации комбинаций отношений разного типа.
- Навигацию, позволяющую пользователю выбирать интересующие его отношения между классами или объектами, выделять соответствующие подграфы и изображать их.
Так, для визуализации связей между классами оказалось весьма полезным совместное изображение отношения наследования и ассоциативных отношений, а для визуализации связей между объектами - совместное изображение отношения партономии в комбинации с различными ассоциативными отношениями;
Для построения таких изображений разработан новый алгоритм визуализации ассоциативных связей, использующий иерархические жгуты ребер. Показано также, что этот метод визуализации позволяет более эффективно обнаруживать классы, не имеющие собственной специфики (отношения, атрибуты), по отношению к родительским классам (см. Рис. 3).


(а) (б)
Рис. 3. Совместное изображение отношений наследования и ассоциативных отношений. (а) радиальный алгоритм визуализации. (б) круговой алгоритм и иерархические жгуты ребер.
Реализовано также расширение подсистемы визуализации информационного наполнения таких порталов новыми средствами анализа, обеспечивающими генерацию сетей сотрудничества из имеющихся данных, извлечение научных сообществ и их визуализацию (см. Рис. 4).


(а) (б)
Рис. 4 (а) Наибольшая связная компонента сети соавторства, имеет 370 вершин и 1690 ребер. (б) визуализация разбиения сети соавторства на 35 научных сообществ.
Наконец, на основе метода иерархических жгутов ребер реализована возможность совместного изображения сетей сотрудничества и онтологических отношений (см. Рис. 5).

Рис 5. Совместное изображение сетей соавторства и онтологических отношений. Отношение соавторства между разными разделами археологии.
3. Разработаны методы получения структурированного представления текста документа, позволяющего установить ассоциативные связи между публикациями и персонами с целью их последующей визуализации и анализа.
В рамках исследований по данной теме, прежде всего, была разработана формальная структура представления статьи, которая включает два основных блока: описание основных данных о статье и описание содержащихся в статье ссылок на другие публикации.
Первый блок включает основные характеристики статьи: «название», «авторы», «аннотация», «ключевые слова». Второй блок содержит следующие атрибуты цитируемой в статье публикации: «авторы», «название», «год издания», «название журнала», «том», «выпуск», «первая страница», «последняя страница», «URL» и другие.
Разработан метод автоматического построения формального описания научной статьи, суть которого состоит в следующем:: (1) с помощью эвристических правил и с опорой на маркеры (характерные слова или словосочетания) выделяются основные разделы статьи (заголовок, список авторов, аннотация, ключевые слова, список литературы), (2) на основе анализа выделенных разделов определяются основные характеристики статьи, (3) на основе иерархической системы шаблонов и регулярных выражений выполняется синтаксический разбор списка литературы и формируются библиографические ссылки (цитаты), (4) все полученные данные о статье заносятся в базу данных цитирования (библиографических ссылок).
Наибольшую сложность представляет синтаксический разбор ссылок, входящих в список литературы. При его выполнении каждая ссылка сопоставляется с заранее разработанными шаблонами ссылок (или полными шаблонами) с целью определения значений ее атрибутов. В случае, если ссылка подходит под какой-либо шаблон, то указанным в шаблоне полям ставятся в соответствие их текстовые значения, извлеченные из ссылок.
Каждый шаблон ссылки описывается упорядоченным набором блок-полей или символьных блоков:
<Шаблон> ::= {<Блок-поле>|<Символьный блок>}+
Блок-поле в записи шаблона представляют собой имя поля, заключенное в угловые скобки. Определение в ссылке значения некоторого блок-поля происходит при помощи частичных шаблонов путем нахождения им соответствий в ссылке. Частичные шаблоны описываются на языке PCRE (Perl Compatible Regular Expressions). Создание и редактирование их требует от пользователя хорошего знания этого языка. В синтаксическом разборе используются следующие блок-поля: «Автор», «Название», «Год», «Название журнала», «Том», «Выпуск», «Стартовая страница», «Конечная страница», «URL» и другие.
Символьные блоки – это набор символов, как правило, присутствующий в шаблоне для описания характерных для библиографической ссылки элементов. Например, согласно [ГОСТ 7.1-84, 1984] название статьи и название журнала в библиографической ссылке разделяются комбинацией «//». Символьные блоки располагаются в шаблоне между блок-полями.
Для каждого типа ссылки (журнальная статья, статья в трудах конференции, статья в книге и т.п.) разработан свой шаблон. Каждому из типов шаблонов соответствуют свои наборы полей, которые могут входить в ссылку. По их наличию и определяется тип ссылки.
Разработан модуль, реализующий указанные методы автоматической обработки текста статьи. Создан пользовательский интерфейс, позволяющий пользователю просматривать и редактировать полученные в результате автоматической обработки формальные описания статей. Разработан конструкторский интерфейс, позволяющий редактировать полные и частичные шаблоны.
Разработан модуль, обеспечивающий конвертирование базы данных библиографических ссылок в стандартные форматы, в частности, в XML, что делает доступной содержащуюся в ней информацию для визуализации и анализа.
Достоинством предложенного подхода является возможность настройки алгоритмов построения формальных описаний научных статей на коллекцию статей, подлежащих обработке. Это необходимо в связи с тем, что правила оформления статей, особенно списка цитируемой литературы, у разных изданий различаются. Такая настройка обеспечивается путем модификации набора шаблонов, обеспечивающих обработку статей.
4. Исследованы подходы к построению онтологий информационных систем путем трансформации уже существующих онтологий. в том числе, методы эволюции и реинжиниринга онтологий.
4.1. Методы эволюции онтологий.
Эволюция онтологии (ontology evolution) может быть определена как регулярная модернизация (адаптация) онтологии, сопровождаемая согласованным распространением изменений. Модификации в одной части онтологии могут породить едва заметные несоответствия в другой ее части, в экземплярах понятий, зависимых онтологиях и приложениях. Это множество причин и следствий изменения онтологии делает эволюцию онтологии очень сложной операцией, которая должна реализовываться как составной организационный процесс. В работе [A. Maedche, B. Motik, L. Stojanovic, N. Stojanovic. User-driven ontology evolution management. In European Conf. Knowledge Eng. and Management (EKAW 2002). Springer-Verlag, 2002. pp. 285–300] определены и рассмотрены шесть возможных фаз процесса эволюции онтологии: (1) представление изменений, (2) семантика изменений, (3) реализация изменений, (4) распространение изменений, (5) валидация изменений, (5) обнаружение и фиксация изменений. Рассмотрим эти фазы подробнее.
(1) Представление изменений. Чтобы разрешить изменения, их нужно не только идентифицировать, но и представить в подходящем формате. Элементарные изменения в онтологии (например, добавление понятия, удаление свойства, задание для свойства его области значений) выводятся из ее концептуальной модели. Однако такая глубина детализации изменений онтологии не всегда является удобной. Часто смысл изменений может быть выражен на более высоком уровне. Например, пользователь захочет переместить понятие от одного родителя к другому. Он может привести онтологию в желаемое состояние путем последовательного применения списка элементарных эволюционных изменений (например, “удалить подпонятие” и “добавить подпонятие”). Однако, множество ненужных изменений может быть выполнено, если каждое изменение выполняется отдельно. Чтобы избежать этого недостатка, необходимо выражать изменения в более крупных операциях, с тем, чтобы они были непосредственно видны. Поэтому вводятся составные изменения, представляющие группу элементарных изменений, выполняемых вместе.
(2) Семантика изменений. Изменение одной части онтологии может вызвать появление несовместностей (противоречий) в другой ее части. Различают семантические и синтаксические несовместности. Семантическая несовместность возникает, если значение (смысл) онтологической сущности изменяется. Синтаксическая несовместность появляется, либо когда используется неопределенная сущность на уровне понятий онтологии или экземпляров, либо когда ограничения онтологической модели нарушаются. Например, удаление понятия, которое является единственным элементом области значений какого-нибудь свойства, приводит к синтаксической несовместности. Разрешение этой проблемы трактуется как запрос на новое изменение онтологии, которое может привести к появлению новых задач, которые повлекут за собой новые изменения и т.д. Если онтология большая, то будет достаточно трудно понять объем и смысл каждого наведенного изменения. Задача фазы «Семантика изменений» сделать возможным разрешение наведенных изменений систематическим способом, обеспечивая согласованность всей онтологии. Чтобы помочь лучшему пониманию эффектов каждого изменения, эта фаза должна обеспечить максимум прозрачности, делая возможным детальное проникновение в суть выполняемых изменений.
Для каждого изменения онтологии можно сгенерировать множество различных наведенных изменений. На этой фазе используется различные стратегии эволюции, являющиеся механизмами, с помощью которых пользователь может настроить процесс эволюции онтологии в соответствии со своими потребностями. В результате, пользователь может переводить онтологию в желаемое непротиворечивое состояние.
(3) Реализация изменений. Для того чтобы избежать нежелательных изменений, перед выполнением операции изменения онтологии должен быть сгенерирован и представлен пользователю список всех ее последствий для онтологии. Пользователь должен быть способен понять этот список и иметь возможность подтвердить или отменить эти изменения. Когда изменения одобрены, они выполняются последовательно. Так как требуется выполнять несколько изменений сразу, требуется сервер транзакций. Если изменения отменены, онтология остается неизменной.
(4) Распространение изменений. Задача фазы распространения изменений – привести все зависимые элементы в непротиворечивое (целостное) состояние, после того как обновление онтологии выполнено. Во-первых, после модификации онтологии, должны быть изменены все экземпляры понятий онтологии, чтобы сохранить их согласованность с онтологией. Во-вторых, обновление онтологии может повредить зависящие от нее онтологии, а следовательно и все артефакты, базирующиеся на этих онтологиях. Эти проблемы могут быть разрешены рекурсивным применением процесса эволюции онтологии к этим онтологиям. Однако, кроме синтаксической несовместности, может возникать семантическая. Например, когда зависимая онтология уже содержит понятие, добавленное в оригинальную онтологию. В-третьих, когда онтология изменяется, базирующиеся на ней приложения могут начать работать некорректно. Методы эволюции онтологии должны распознавать такие изменения в онтологии, которые могут влиять на функциональность зависящих от них приложений, и реагировать на них соответствующим образом.
(5) Валидация изменений. При коллективной разработке онтологии у разных групп разработчиков могут возникать различные мнения о том, какие изменения должны быть внесены в онтологию. В дальнейшем одна из групп может не понять действительный эффект изменения и будут выполнены нежелательные изменения онтологии. Кроме того, могут потребоваться изменения онтологии в экспериментальных целях. Для того, чтобы защититься от этих ситуаций, в процесс эволюции онтологии вводится фаза валидации. Валидация должна оценить правильность онтологии по отношению к проблемной области – насколько правильно онтология представляет выбранную часть реальности и требования пользователей. Она делает возможным подтверждение выполненных изменений и аннулирование их по требованию пользователя. Важно заметить, что обратимость означает устранение всех эффектов изменения, которые могут быть не теми же самыми как при простом выполнении обратных изменений вручную. Например, если понятие удаляется из иерархии понятий, его подпонятия либо также должны быть удалены, либо подсоединены к корневому понятию или родителю удаленного понятия. Обращение такого изменения не эквивалентно воссозданию удаленного понятия – требуется возвратить иерархию понятий в прежнее состояние. Проблема обращения обычно решается путем создания логов эволюции. Лог эволюции сохраняет информацию о каждом изменении, позволяя реконструировать последовательность изменений, приводящих к первоначальному состоянию онтологии.
(6) Обнаружение и фиксация изменений. После фазы валидации мы можем получить онтологию, которая хотя и непротиворечива, но имеет ненужные понятия или плохую структуру. Например, разные пользователи могут работать над разными частями онтологии при недостаточном уровне коммуникации. Они могут удалять подпонятия общего понятия, руководствуясь своими сиюминутными нуждами. В результате у понятия может остаться только одно подпонятие. Так как классификация только с одним классом противоречит первоначальным целям классификации, можно рассматривать такую онтологию как имеющую неоптимальную структуру. Чтобы помочь пользователям обнаруживать такие ситуации, рекомендуется применение принципов самоприспосабливающихся систем, которые порождают упреждающие предложения по усовершенствованию онтологии (т.е. изменению онтологии с целью ее улучшения) с целью сделать ее более легкой для понимания и более удобной для модификации. Такие предложения по улучшению онтологии, базирующиеся на эвристиках и/или алгоритмах data mining, могут управляться результатами анализа таких источников, как:
- Структура онтологии
– Если все подпонятия имеют одно и то же свойство, то это свойство может быть приписано их родительскому понятию;
– Понятие с одним подпонятием должно быть слито с его подпонятием;
– Если у одного понятия существует более дюжины подпонятий, то необходимо ввести еще один уровень иерархии понятий;
– Понятие без свойств является кандидатом на удаление;
– Если прямой (непосредственный) родитель понятия может быть достигнут через непрямой путь, тогда прямая связь должна быть удалена.
- Экземпляры онтологии
– Понятие без экземпляром является кандидатом на удаление;
– Если ни один экземпляр понятия C не использует никакие свойства, определенные в понятии C, и в то же время такие экземпляры используют свойства, наследуемые от родительского понятия, можно сделать предположение, что понятие C лишнее;
– Понятие, имеющее слишком много экземпляров, является кандидатом для разделения на подпонятия, при этом его экземпляры будут распределены между новообразованными понятиями.
- Информация описывающая образцы использования онтологии
– Отслеживая, когда какое-либо понятие было последний раз найдено при обработке запроса, можно обнаружить, что это понятие устарело и может быть удалено из онтологии или скорректировано.
Для управления эволюцией онтологии портала научных знаний нами была разработана специальная стратегия эволюции. Необходимость в эволюции онтологии портала может возникнуть в связи с тем, что в процессе его эксплуатации могут появляться новые знания о его предметной области, а также обнаруживаться пробелы и неточности в знаниях, уже представленных в онтологии. Все это, безусловно, требует изменения онтологии. Однако при изменении онтологии необходимо следить за тем, чтобы не нарушилась логическая целостность системы знаний портала и не произошла потеря информации.
Эволюция онтологии может заключаться в расширении или перестройке ее системы понятий, удалении или переименовании понятий и/или отношений.
Вначале рассмотрим случаи, связанные с расширением системы понятий онтологии.
В простейшем случае такое расширение заключается в добавлении нового атрибута какому-либо понятию. Здесь требуется учитывать, что такой атрибут уже мог быть у понятий, являющихся потомками данного понятия. Поэтому нужно просмотреть всех его потомков и, если необходимо, выполнить переименования соответствующих атрибутов.
Добавление нового понятия в самый низ иерархии понятий не требует каких-либо усилий по поддержанию целостности системы понятий, так как при этом новое понятие унаследует все атрибуты и связи вышестоящих понятий.
Если добавляется понятие, которое станет корневым в одной из иерархий понятий, необходимо учитывать атрибуты и связи нижестоящих понятий. Возможно, потребуется перемещение части атрибутов и связей в новое понятие, тем более, учитывая перспективу появления новых ветвей иерархии, берущих начало из нового понятия.
Вставка нового понятия в иерархию между двумя «старыми» понятиями также требует некоторых методологических усилий. Чтобы избежать дублирования и возможных коллизий имен, необходимо аккуратно выбрать для него атрибуты и связи из нижестоящих понятий.
При удалении «листового» понятия, т.е. понятия, находящегося в самом низу иерархии, стоит подумать о передаче его собственных атрибутов и связей вышестоящему понятию, чтобы не произошло потери знаний. Нужно иметь в виду, что если на основе удаляемого понятия уже созданы информационные объекты, то, чтобы не потерять данные, необходимо эти информационные объекты привязать к предку удаляемого понятия. Но этого может оказаться недостаточно для сохранения всей информации об этих объектах, если предварительно вышестоящему понятию не будут переданы все собственные атрибуты и связи удаляемого понятия.
Если удаляемое понятие не является «листовым», то перед его удалением необходимо подумать о передаче его атрибутов и связей нижестоящему понятию (см. Рис.6). Информационные объекты, как и в случае с «листовым понятием», должны быть привязаны к вышестоящему понятию и модифицированы в соответствии с его структурой.

Рис.6. Удаление «нелистового» понятия. (a) – исходная структура онтологии, (b) – результирующая структура.
Удаление «корневых» понятий онтологии портала, находящегося в эксплуатации или на этапе информационного наполнения, не рекомендуется из-за возможной потери информации.
При удалении атрибутов из понятий также нужно учитывать возможную потерю информации. Частным случаем удаления атрибута является его перемещение в понятие более высокого или более низкого уровня, когда выясняется, что данный атрибут является более общим или, наоборот, более специфическим. В первом случае потери информации не происходит, так как перемещаемый атрибут все равно будет унаследован модифицируемым понятием. Во втором случае такая потеря возможна, и нужно принять меры для ее восстановления.
Иногда приходится перемещать понятие внутри иерархии. При этом нужно учитывать, что меняется не только набор наследуемых понятием атрибутов, но и связей. Возможно, что некоторые потерянные в результате этого перемещения атрибуты и связи придется восстанавливать «вручную».
Достаточно интересным случаем представляется перемещение поддеревьев из одной ветки иерархии в другую. Этот случай практически рекурсивно сводится к рассмотренному выше случаю. В большинстве случаев достаточно «привести в порядок» корневое понятие перемещаемого поддерева, а остальные понятия модифицируются автоматически.
4.2. Реинжиниринг онтологий.
Реинжиниринг онтологий применяется тогда, когда требуемая онтология не может быть получена из существующей путем эволюции. Под реинжинирингом онтологии понимается процесс (см. Рис.7), включающий (1) получение концептуальной модели уже реализованной онтологии, (2) отображение ее в другую, более адекватную для решаемой задачи концептуальную модель, (3) реализацию на основе этой модели новой онтологии.

Рис. 7. Процесс реинжиниринга онтологии.
Наиболее известен метод реинжиниринга онтологий, разработанный и применяемый онтологической группой Мадридского политехнического университета [Gmez-Prez, A., Rojas, M. D.: Ontological Reengineering and Reuse”. In: 11th European Workshop on Knowledge Acquisition, Modeling and Management. pp. 139–156. Springer-Verslag, Dagstuhl Castle, Germany, 1999]. Рассмотрим его подробнее.
Этот метод адаптирует схему реинжиниринга программного обеспечения Чиковского [Chikofsky, E.J., Cross II, J.H.: Reverse Engineering and design recovery: A taxonomy. J. Software Magazine. 1990. 7 (1), 13–17] к области онтологий. В этой схеме выделены три главные деятельности: (1) восстановление исходной структуры, (2) реструктурирование (перепроектирование) и (3) прямая разработка онтологии.
Целью восстановления исходной структуры является получение концептуальной модели на основе кода (спецификации на каком-либо формальном языке) онтологии. При построении концептуальной модели используется множество промежуточных представлений, предложенных в методологии METHONTOLOGY [Fernndez, M., Gmez-Prez, A., Juristo, N.: METHONTOLOGY: From Ontological Art Towards Ontological Engineering. In: Symposium on Ontological Engineering of AAAI. pp. 33-40. Spring Symp. Series, AAAI Press, Menlo Park, Calif. 1997]. Фактически, такая методология реинжиниринга может быть рассмотрена как расширение возможностей методологии METHONTOLOGY.
В задачу реструктурирования входит преобразование исходной концептуальной модели в новую концептуальную модель, которая строится с учетом использования реструктурированной онтологии другими онтологиями или приложениями. Деятельность по реструктуризации включает две фазы: анализ и синтез.
Фаза анализа включает оценку онтологии, т.е. проверку того, что иерархия онтологии и ее классы, экземпляры, отношения и функции полны, непротиворечивы (нет конфликтов), не избыточны (нет явных или неявных повторений) и синтаксически корректны.
На фазе синтеза реализуется корректная онтология и документируются любые сделанные изменения. Таким образом, в этом контексте возникают деятельности, связанные с управлением конфигурациями, целью которых является сохранение протокола эволюции онтологии и строгий контроль за ее изменениями.
Целью прямой разработки является получение новой реализации онтологии на базе новой концептуальной модели.
Хотя рассмотренный выше метод реинжиниринга онтологий является достаточно хорошо проработанным и описанным, он может быть улучшен. В частности, чтобы повысить переиспользуемость онтологии, получаемой в ходе реинжиниринга, необходимо внести в процесс реструктуризации рекомендации и критерии достижения высокой степени переиспользуемости. Другим открытым вопросом в этом методе является отношение между реструктурируемой онтологией и существующими онтологиями высокого уровня. Кроме того, этап восстановления исходной структуры в этом методе сильно завязан на методологию METHONTOLOGY (метод использует предложенные в этой методологии промежуточные представления концептуальной модели). Чтобы сделать этот метод реинжиниринга онтологий более универсальным, нужно формализовать данный этап с использованием традиционных средств, например логики первого порядка.
Публикации
- Yury A. Zagorulko. On Experience of Building Knowledge Portals on Humanities // First Russia and Pacific Conference on Computer Technology and Applications, 6-9 September, 2010, Vladivostok, Russia. –P.336-339.
- Yury Zagorulko, Olesya Borovikova, Galina Zagorulko. Knowledge Portal on Computational Linguistics: Content-Based Multilingual Access to Linguistic Information Resources // Selected topics in Applied Computer Science. Proceedings of the 10th WSEAS International Conference on Applied Computer Science (ACS’10). Hamido Fujita, Jun Sasaki (Eds.). (Iwate Prefectural University, Japan, October 4-6, 2010). – WSEAS Press, 2010. –P.255-262.
- Yury Zagorulko, Galina Zagorulko. Ontology-Based Approach to Development of the Decision Support System for Oil-and-Gas Production Enterprise // New Trends in Software Methodologies, Tools and Techniques. Proceedings of the 9th SoMeT_10. Hamido Fujita (Eds.) –IOS Press, -Amsterdam, –2010. –P.457-466.
- Yury Zagorulko, Galina Zagorulko. An Approach to Development of the Decision Support System for Enterprise with Complex Technological Infrastructure // Bulletin of NCC.— Issue 31.— 2010.— (to appear).
- Ануреев И.А., Загорулько Ю.А., Загорулько Г.Б. Подход к разработке системы поддержки принятия решений на примере нефтегазодобывающего предприятия. // Известия Томского политехнического университета. – 2010. – Т. 316. – № 5. –С. 127–131.
- Загорулько Ю.А., Боровикова О.И., Загорулько Г.Б. О применении технологии создания порталов научных знаний // Тр. XV Байкальской Всероссийской конф. "Информационные и математические технологии в науке и управлении". – Иркутск: Институт систем энергетики им Л.А. Мелентьева СО РАН, 2010. –Т.2. –С. 164-171.
- Загорулько Ю.А., Загорулько Г.Б., Кравченко А.Ю., Сидорова Е.А. Разработка системы поддержки принятия решений для нефтегазодобывающего предприятия // Труды 12-й национальной конференции по искусственному интеллекту с международным участием – КИИ-2010. – Москва: Физматлит, 2010. -Т.3. -С.137-145.
- Загорулько Ю.А., Загорулько Г.Б., Булгаков С.В. Подход к разработке системы поддержки принятия решений для добывающего предприятия нефтегазового комплекса // Тр. XII Междунар. конф. "Проблемы управления и моделирования в сложных системах". – Самара: Самарский Научный Центр РАН, 2010. –С. 512–517.
- Загорулько Ю.А., Загорулько Г.Б. Поддержка принятия решений по повышению энергоэффективности и экологической безопасности на нефтегазодобывающем предприятии // Тр. XV Байкальской Всероссийской конф. "Информационные и математические технологии в науке и управлении". – Иркутск: Институт систем энергетики им Л.А. Мелентьева СО РАН, 2010. –Т.2. –С. 185-190.
- Апанович З.В. Методы визуализации информации – наукоемкое направление современных ИТ // Компьютерные инструменты в образовании.— N2.— 2010 — С. 20–27.
- Апанович З.В. Методы визуализации графов, как инструмент, способствующий пониманию информации // Компьютерные инструменты в школе.— N2.— 2010 — С. 34–39
- Апанович З.В., Кислицина Т.A. Расширение подсистемы визуализации наполнения информационного портала средствами визуальной аналитики // Проблемы управления и моделирования в сложных системах: Труды XII Международной конференции (Самара, 21-23 июня 2010 г.).— 2010.— С. 518–525.
- Апанович З.В. Винокуров П.С. Информационные порталы, основанные на онтологиях, и визуализация научных сообществ // Труды 12-й национальной конференции по искусственному интеллекту с международным участием – КИИ-2010. – Москва: Физматлит, 2010. –Т.2. –С.213-221.
- Apanovich Z.V., Vinokurov P.S., Ontology based portals and visual analysis of scientific communities//First Russia and Pacific Conference on Computer Technology and Applications, 6-9 September, 2010, Vladivostok, Russia. –P.7-11.
- Апанович З.В., Винокуров П.С., Кислицина Т.А. Гибкая подсистема визуализации онтологии и информационного наполнения порталов знаний на протяжении их жизненного цикла // Труды RCDL'2010 - Двенадцатая Всероссийская научная конференция "Электронные библиотеки: перспективные методы и технологии, электронные коллекции" Казань, Казанский университет, 2010.— C. 265-272.
- Apanovich Z.V., Vinokurov P.S. An extension of a visualization component of ontology based portals with visual analytics facilities. // Bulletin of NCC.— Issue 31.— 2010.— (to appear).
Участие в международных и всероссийских научных мероприятиях
- Международная научная конференция «Интеллектуальные системы принятия решений и проблемы вычислительного интеллекта» (ISDMCI’2010). Евпатория, Украина, 17-21 мая 2010 г.
- XII Международная конференция "Проблемы управления и моделирования в сложных системах" (ПУМСС-2010). Самара, 21-23 июня, 2010 г.
- XV Байкальская Всероссийская конференция "Информационные и математические технологии в науке и управлении". Иркутск, 4-9 июля, 2010 г.
- First Russia and Pacific Conference on Computer Technology and Applications, 6-9 September, 2010, Vladivostok, Russia.
- 12-я национальная конференция по искусственному интеллекту с международным участием – КИИ-2010, 21-24 сентября, 2010 г, Тверь.
- 9th SoMeT_10 conference (“New Trends in Software Methodologies, Tools, and Techniques”). Yokohama, Japan, 29 September – 1 October 2010.
- 10th WSEAS International Conference on Applied Computer Science (ACS’10). Iwate Prefectural University, Morioka, Japan, October 4-6, 2010.
- Второй симпозиум «Онтологическое моделирование: состояние, направления исследований и применения». Казань, 11-12 октября 2010 г
- XII Всероссийская научная конференция «Электронные библиотеки: перспективные методы и технологии, электронные коллекции» (RCDL’2010), Казань, 13 – 17 октября 2010 г.
ПЛАН ИССЛЕДОВАНИЙ НА 2011 ГОД
- Развитие формальных и программных методов и средств построения онтологий.
- Разработка методов автоматизации построения и настройки компонентов информационной системы, а также интеграции в ИС внешних источников данных на основе онтологий.
- Разработка формальных методов эволюции, слияния и реинжиниринга онтологий. Апробация указанных методов на примере эволюции и реинженринга онтологии научного портала знаний с целью ее использования в Semantic Web приложениях..
- Продолжение работ по визуализации онтологий и информационного наполнения ИС. В частности, проведение исследований и экспериментальная разработка нескольких интерактивных методов визуализации онтологий и информационного наполнения ИС в виде графа.
Тема 3. Методы автоматического извлечения фактов из текстов на естественном языке
В рамках этой темы в 2010 г. проводились исследования в следующих направлениях:
- Исследование прагматического контекста в информационных системах, основанных на знаниях.
- Развитие методов и программных средств построения баз знаний
- Развитие формальных моделей и программных средств для автоматического извлечения фактов из текстов деловых и научных документов предметной области «Деятельность СО РАН»
Полученные за отчетный период важнейшие результаты
1. Исследование прагматического контекста в информационных системах, основанных на знаниях
В рамках исследований по данной теме был проанализирован прагматический контекст информационных систем (ИС), основанных на знаниях. Большинство ИС в той или иной форме используют ЕЯ-сервисы, предназначенные для решения различных задач, связанных с анализом текста на естественным языке. Выделено два типа ЕЯ-сервисов: системные сервисы, используемые для автоматического наполнения и изменения содержания системы, и пользовательские сервисы, предоставляющие пользователям ИС разнообразный доступ к информации (Рис.8).
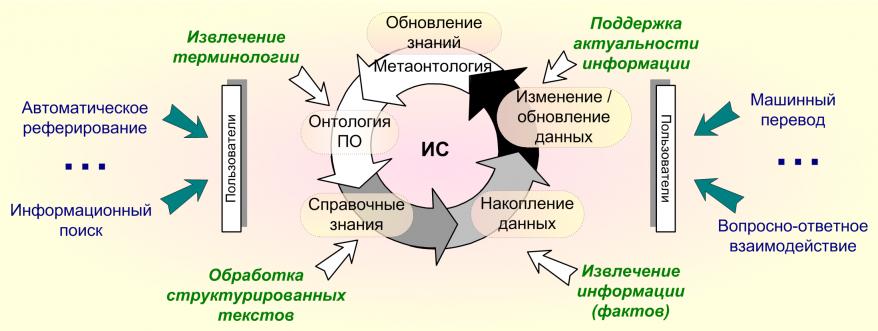
Рис.8. ЕЯ-сервисы информационной системы.
Разработка базы знаний информационной системы – это обязательно итеративный процесс, поэтому был рассмотрен жизненный цикл базы знаний ИС в контексте использования средств анализа текста для ее развития. Под жизненным циклом понимается непрерывный процесс, который начинается с момента принятия решения о необходимости создания ИС и заканчивается в момент полного прекращения ее поддержки. Таким образом, жизненный цикл базы знаний, как неотъемлемая часть жизненного цикла самой системы, охватывает все стадии и этапы ее создания, сопровождения и развития. Отметим, что задачи, решаемые сервисом анализа текста на разных этапах, на самом деле различны, даже типы или жанры документов, с которыми приходится работать, могут быть неодинаковы.
На начальном этапе разработки системы онтология играет важную роль при анализе требований и концептуальном моделировании. На данном этапе осуществляется проектирование базы знаний системы – формируется онтология верхнего уровня (метаонтология), фиксируются основные понятия предметной области; определяется набор системных ЕЯ-сервисов, необходимых ИС.
Онтологический анализ предметной области (ПО) обычно начинается с создания словаря терминов, который используется при обсуждении и исследовании характеристик объектов и процессов, составляющих рассматриваемую предметную область, также выделяются основные логические взаимосвязи между введенными понятиями (и терминами). Таким образом, встает задача автоматического извлечения предметной терминологии, которая включает как однословные, так и многословные термины. Для решения этой задачи используется подборка текстов по данной тематике, на которых применяются методы обучения словаря (под обучением понимается процесс формирования словаря со статистическими показателями), включающие морфологический и поверхностный синтаксический анализ текстов. Далее, на основе статистического распределения терминов выделяются общезначимые и предметные термины, для которых, используя различные методы кластеризации, можно автоматизировать построение иерархичных отношений и сформировать списки синонимов для дальнейшего анализа. Условием применения таких методов является наличие обучающего корпуса текстов – массива текстов специальным образом размеченного.
Следующий этап – наполнение системы необходимой информацией.
В первую очередь осуществляется добавление справочно-энциклопедической информации, вид и характер которой должны найти отражение в онтологии ПО. К справочному знанию относятся, например, номенклатурные обозначения, толкования понятий ПО или заранее известный список производственных объектов, такие знания представляются в виде экземпляров понятий и отношений онтологии ПО (поэтому их можно отнести к онтологии нижнего уровня). Таким образом, рассматривается задача автоматического добавления справочной информации в базу знаний системы, на основе анализа имеющихся справочных ресурсов, представленных в электронном виде. Справочные ресурсы – это, как правило, хорошо структурированные тексты, поэтому использование формальной жанровой модели (или структуры текста) таких ресурсов может значительно упростить процесс анализа текста, а также ускорить его настройку. Один из основных видов справочной информации, размещаемой в таких лингвистических ресурсах, как энциклопедии и тезаурусы, – толкования терминов ПО. Еще одной особенностью данного типа ресурсов является наличие в тексте значимых несловарных единиц, выражаемых буквенно-числовыми конструкциями (например, H20, 5 м/с, 103-105 км, корпус 2а, изделие №4b и т.п.).
Основной задачей, решаемой системным сервисом анализа документов, является извлечение значимой для пользователей информации из большого объема поступающих документов (слабо-структурированных текстовых ресурсов) и накопление ее в базе данных системы в формате, определяемом онтологией ПО. Задачей данного этапа является извлечение значимых фактов. Правила для извлечения факта из текста должны учитывать множество языковых способов репрезентации данного факта носителями подъязыка и обеспечивать их трансформацию в формальную структуру объектов и отношений. Таким образом, результат извлечения фактов из текста представляется в виде семантической сети объектов, являющихся экземплярами понятий и отношений, заданных онтологией. Данная семантическая сеть добавляется в информационное пространство ИС и, таким образом, преобразуется в знания, которыми в дальнейшем может оперировать система и ЕЯ-сервисы.
Когда в системе накоплено достаточное количество данных возникает ситуация, когда при поступлении новой информации, ее требуется согласовывать с уже имеющейся в системе. Для этого необходимо обеспечить корректность, целостность, уникальность и актуальность, полученных в результате анализа данных. Т.е. встает задача поддержки актуальности информации.
Внесение изменений в онтологию предметной области (а также, в онтологию верхнего или метаонтологию) возможно либо при изменении требований к системе со стороны пользователя, либо при накоплении достаточного количества фактов сигнализирующих о наличие неполноты в системе описания онтологии.
Для доступа к информации ИС разрабатываются пользовательские ЕЯ-сервисы, такие как информационный поиск фактов или документов, содержащих определенные факты, представление кратких рефератов просматриваемых документов, структурирование информации, полученной по поисковому запросу пользователя (рубрикация, кластеризация) и т.п. Сам запрос пользователь может оформлять либо на естественном языке в виде вопроса (вопросно-ответное взаимодействие), либо по ключевой фразе, либо заполняя определенную форму (формируя тем самым структурированный в соответствии с ПО запрос), либо используя навигационные средства представляемые ИС.
2. Развитие методов и программных средств построения баз знаний
В настоящее время доминантой исследований в области, связанной с обработкой информации на естественном языке, является создание компьютерных лингвистических ресурсов. Разрабатываемая технология обработки текста содержит компоненты, которые, с одной стороны, позволяют экспертам (лингвистам, специалистам в конкретной предметной области и инженерам знаний) формировать базу знаний и, с другой стороны, – обеспечивают автоматическое применение этих знаний в процессе обработки документов, в том числе и для обогащения самой базы знаний.
База знаний включает набор лингвистических ресурсов, для создания которых требуются дополнительные технологические компоненты, позволяющие автоматизировать создание, начальное наполнение, а также обеспечить дальнейшую поддержку (внесение изменений и синхронизацию) ресурсов.

Рис.9. Задачи, ресурсы и средства для поддержки ЕЯ-сервисов.
На Рис.9 представлены лингвистические ресурсы и их соответствия с выполняемыми сервисами задачами и дополнительными средствами, необходимыми для их создания.
2.1. Методы и программные средства разметки корпуса текстов
Одним из необходимых инструментов для исследования экспертом или лингвистом предметной области и создания словаря и других ресурсов, используемых при обработке текста, является инструментальная среда исследования корпуса текстов.
В этом году была спроектирована и разработана первая версия системы разметки корпуса текстов, предназначенной для аннотирования фрагментов текста различными признаками.
В качестве фрагмента может выступать слово, неразрывная цепочка слов (связный фрагмент) или множество неразрывных цепочек, не образующих связный фрагмент (разрывный фрагмент). Признаки формируются пользователем и делятся на три группы: морфологические, синтактико-семантические, объектные (соответствующие точным объектам). Признаки располагаются в древообразной структуре, которая может включать виртуальные вершины (не являющиеся признаками). Множеству признаков сопоставляется цветовая схема разметки, которая впоследствии используется при реализации функций визуализации.
В дальнейшем в системе будут реализованы следующие инструменты: поиск встречаемости термина (однословного или многословного) с учетом словоизменения, группировка контекстов терминов, выбранных по одному или совокупности значений признаков (морфологических, лексических, семантических), визуализация покрытия текста терминами с учетом их признаков; будут совершенствоваться средства разметки текстов.
Размеченные фрагменты текста могут в дальнейшем использоваться для наполнения предметного словаря. Отмеченная лексика обрабатывается морфологическим и синтаксическим компонентами словарной технологии, нормализуется, вносится в словарь и снабжается семантическими признаками в соответствии с разметкой. Для многословных фрагментов фиксируется синтаксический шаблон, для которого накапливается статистика. В дальнейшем эти шаблоны могут объединиться по определенным правилам, просматриваться и редактироваться лингвистом.
2.2. Методы и программные средства создания семантических словарей
Была спроектирована и реализована технология создания семантических словарей, предназначенных для поддержки частичного синтаксического и семантического анализа. Структурно данные семантического словаря разделяются на четыре группы. Это списки лексем и семантико-синтаксических шаблонов (фреймов) предикатно-актантных структур, а также таблицы семантических и грамматических атрибутов. Вся функциональная часть данного словарного компонента основывается на связях соответствующих лексем и сопоставленных им фреймов.
Предикатно-аргументная структура образуется целевым предикатным словом и набором актантов, заполняющих соответствующие валентности этого слова. Валентность – это сочетательная способность предикатного слова, описываемая в словаре в терминах семантических и синтаксических признаков (см. Рис.10). Такое представление предикатного слова и множества его актантов соответствует понятию модели управления (МУ) предиката.

Рис. 10. Структура семантико-синтаксических шаблонов.
Компонент позволяет создавать независимые семантические словари, а также согласовывать семантический словарь с терминологическим словарем.
Словарный компонент должен отвечать требованию многократного использования данных. Данные, хранящиеся в словаре, с одной стороны, должны быть хорошо структурированы, с другой, – доступ к ним должен осуществляться максимально эффективно и просто. Для достижения этой цели был разработан формат хранения словаря, основанный на технологии XML.
Система на данный момент включает редактор и ядро. Редактор предоставляет пользователю функционал по ручному наполнению словаря данными, а также инструменты для сопоставления семантико-синтаксических шаблонов лексемам терминологического словаря и фактически является интуитивно понятным графическим интерфейсом, являющимся оболочкой над ядром компонента. Основным пользователем редактора является лингвист или эксперт, осуществляющий настройку словаря на анализ текстов определенной ПО. Ядро компонента представляет собой отдельную DLL-библиотеку, которая обеспечивает полный набор функций по работе с данными словаря, а также дополнительные сервисные функции поиска соответствующего актанта, проверки управления или согласования для двух входящих элементов текста.
Таким образом, данная система является универсальным средством, реализующим словарь семантико-синтаксических шаблонов, и может использоваться в системах, обрабатывающих связный текст, для широкого круга задач. Была проведена экспериментальная работа по внедрению реализованного компонента в систему фактографического поиска.
3. Развитие формальных моделей и программных средств для автоматического извлечения фактов из текстов деловых и научных документов предметной области «Деятельность СО РАН»
Особенностью развиваемого подхода к извлечению информации из текста является преимущественное использование лексико-семантической информации, что не исключает применения частичного синтаксического анализа и синтаксических ограничений, накладываемых на семантический каркас концептуальных схем фактов. Схема факта должна учитывать множество языковых способов репрезентации описываемого отношения носителями подъязыка и обеспечивать их трансформацию в формальную структуру факта.
Формально, схема факта – это тройка вида < A, Res, C >, где
A – множество дескрипторов аргументов факта, где дескриптором может быть тип словарной единицы, класс информационного объекта (понятие или отношение онтологии) или тип факта.
Res – результат применения схемы, задающий тип операции (создание нового объекта и/или редактирование аргумента), и множество правил для формирования/редактирования объекта.
C – множество ограничений, накладываемых на характеристики аргументов факта. Выделяются следующие ограничения:
условия на класс и другие семантические характеристики аргументов;
ограничение синтаксического согласования вершин синтаксических групп, реализующих аргументы схемы (проверяется согласованность грамматических признаков, например, Согл(число, падеж)),
ограничение семантико-синтаксической сочетаемости вершин синтаксических групп, реализующих аргументы схемы, в соответствии со словарем семантико-синтаксических шаблонов (см. п.2.2),
структурно-текстовые ограничения на взаиморасположение аргументов в тексте.
Реализация подхода, использующего локальный семантико-синтаксический анализ, потребовала реализацию новой словарной технологии по созданию словарей семантико-синтаксических шаблонов (в частности, моделей управления), а также развития разработанных ранее программных средств фактографического анализа.
Разработанные ранее схемы извлечения фактов были ориентированы, главным образом, на извлечение информации об объектах, представленной в синтаксических рамках именной группы. Использование механизма МУ позволило расширить анализ для случаев, когда связь объектов реализуется предикативно, с помощью эксплицитных глагольных предикатов, т.е. лексем, непосредственно репрезентирующих некоторое онтологическое свойство или отношение. В зависимости от семантического признака (класса) предиката, используются схемы, применимые к произвольному предикату этого класса, представленному в любой глагольной форме, возможной в позиции вершины клаузы (личный глагол, причастие, деепричастие и т.п.).
Рассмотрим новые возможности по извлечению фактов на примере ситуации нереферентного употребления имен собственных, когда идентифицированный в тексте фрагмент ФИО не вводит конкретного объекта класса Персона: А. П. Виноградова в контексте Институт геохимии им. А. П. Виноградова; упоминание персон в позиции актанта (С рд) предиката в честь, памяти, а также имя (в контексте присвоить, получить, носить), как акад. А. П. Виноградова в текстовом фрагменте Институту геохимии СО АН СССР присвоено имя выдающегося советского ученого акад. А. П. Виноградова. Это случаи, в которых может иметь место тот или иной вариант локальной неоднозначности (наименование персоны vs. фрагмент наименования организации).
В первом случае омонимия снимается уже на уровне сборки лексических шаблонов объектов: подстрока А. П. Виноградова входит в лексическую конструкцию, реализующую шаблон наименования объекта класса Организация. В остальных случаях снятие неоднозначности требует не только лексического анализа, но и обработки на этапе сборки фактов.
Scheme Имя_Персоны: segment Клауза arg1: Term::Предикат_Имя()
arg2: Object::Персона()
Condition Position = postposition, Упр(arg1,arg2)
arg2(Visibility: false), Fact::Именование(second: arg2)
Идентификация объекта Персона в указанной актантной позиции позволяет изменить статус найденного объекта на нереферентный, одновременно инициируется формирование служебного факта Именование: отношение Именование, в частности, позволяет извлечь связанную с (пере)именованием дату.
Система словарных семантических признаков позволяет представить все необходимые для извлечения релевантной информации контексты употребления предикатных лексических единиц различных семантических классов с учетом их семантической и синтаксической сочетаемости. Эти контексты задаются в словаре МУ предикатных слов, представляющих собой семантико-синтаксические шаблоны, описывающие соответствие семантических характеристик и грамматических признаков единиц в позиции аргументов.
Публикации
- Сидорова Е.А. Обзор задач ЕЯ-сервисов в информационных системах под управлением онтологии // Труды X международной конференции "Проблемы управления и моделирования в сложных системах". –Самара: Самарский Научный Центр РАН, 2010. – C. 534-539.
- Irina S. Kononenko, Elena A. Sidorova. Language Resources in Ontology-Driven Information Systems // First Russia and Pacific Conference on Computer Technology and Applications, 6-9 September, 2010, Vladivostok, Russia. –P.18-23.
ПЛАН ИССЛЕДОВАНИЙ НА 2011 ГОД
- Развитие методов и программных средств создания лингвистических ресурсов, в частности, семантически-размеченного корпуса текстов для дальнейшего его использования в качестве источника прагматической информации.
- Разработка методологии формирования лингвистической и прагматической базы знаний.
- Разработка методов и программных средств поддержки актуальности информации в системе, в частности, идентификации фактов, найденных в тексте.
- Развитие формальных моделей и программных средств извлечения фактов из деловых и научных текстов предметной области «Деятельность СО РАН».
Тема 4. Формально-языковые проблемы информационных систем
В рамках этой темы в 2010 г. проводились исследования в следующих направлениях:
- Разработка формализма для спецификации концептуально-сложных динамических систем (в частности, концептуально-сложных ИС), который комбинирует логические, онтологические и операционные подходы к спецификации ИС и унифицируют средства спецификации ИС, базирующиеся на этих подходах.
- Разработка языка спецификации ИС, базирующегося на предлагаемом формализме.
- Разработка методологии применения предлагаемого языка к спецификации ИС.
- Апробация предлагаемых формализма и языка на примерах ИС.
Полученные за отчетный период важнейшие результаты
В 2010 г. основное внимание было сосредоточено на теоретических и экспериментальных исследованиях в области формальной спецификации предметно-ориентированных концептуально-сложных ИС.
Разработан новый язык выполнимых спецификаций Atoment, который является метаязыком описания предметно-ориентированных языков (domain-specific languages), используемых в концептуально-сложных информационно-вычислительных системах. Описаны синтаксис, семантика и стандартная библиотека этого языка. Язык представляет собой комбинацию двух языков: графового и онтологического. Язык описания и обработки графов с развитыми средствами переписывания графов (graph rewriting) и сопоставления с образцом (pattern matching) выполняет функцию описания данных нижнего уровня и вычислительную функцию обработки этих данных. Онтологический язык с развитой системой макроопределений выполняет функцию концептуальной и терминологической надстройки над графовым языком и приближает за счет макроопределений формальные спецификации к спецификациям на естественном языке, обеспечивая тем самым удобство их понимания и использования.
Выделены два новых класса предметно-ориентированных концептуально-сложных ИС.